Octopus: A Multi-modal LLM with Parallel Recognition and Sequential Understanding
{kind=link}
Abstract
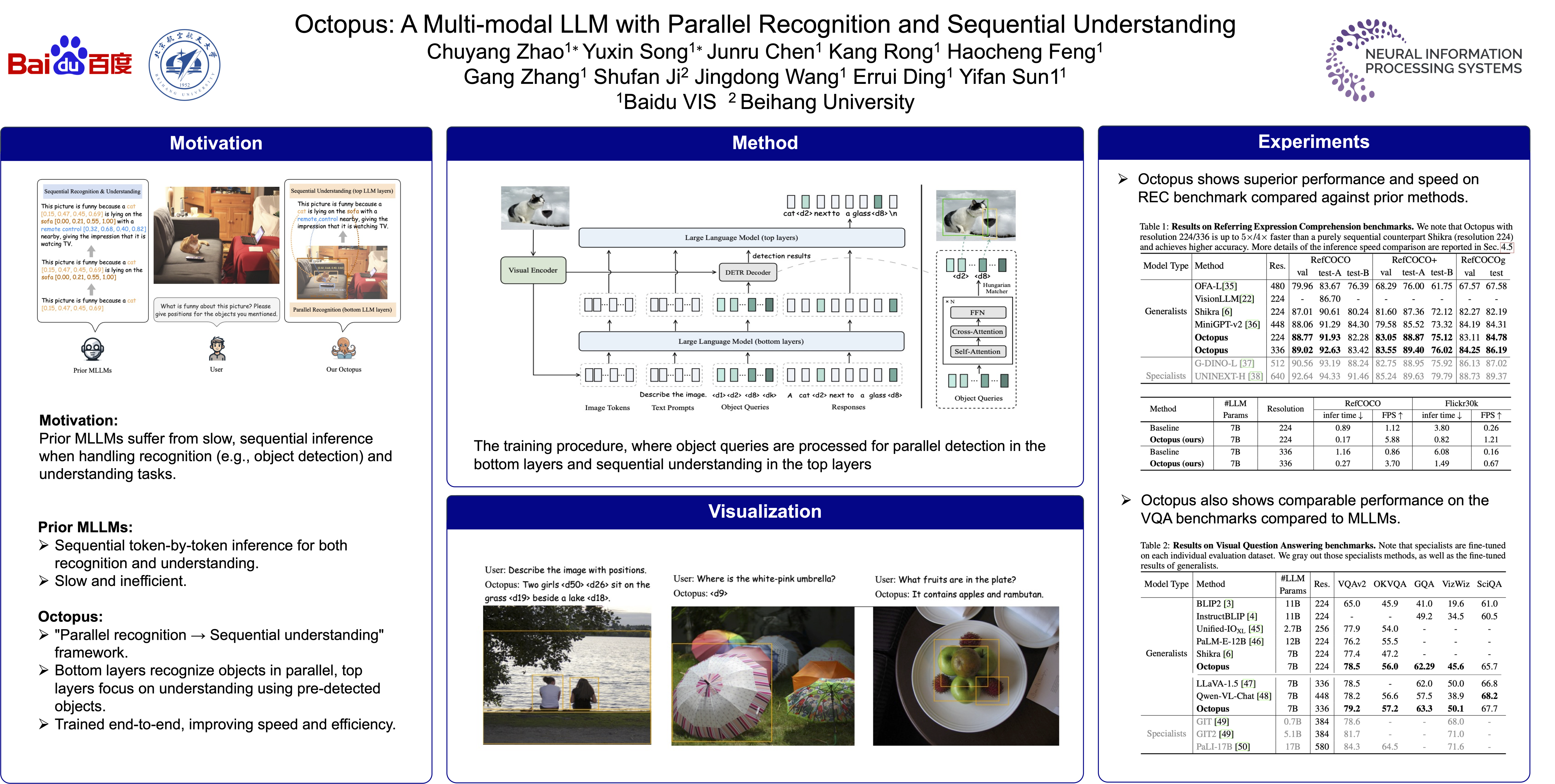
A mainstream of Multi-modal Large Language Models (MLLMs) have two essential functions, i.e., visual recognition (e.g., grounding) and understanding (e.g., visual question answering). Presently, all these MLLMs integrate visual recognition and understanding in a same sequential manner in the LLM head, i.e., generating the response token-by-token for both recognition and understanding. We think unifying them in the same sequential manner is not optimal for two reasons: 1) parallel recognition is more efficient than sequential recognition and is actually prevailing in deep visual recognition, and 2) the recognition results can be integrated to help high-level cognition (while the current manner does not). Such motivated, this paper proposes a novel “parallel recognition → sequential understanding” framework for MLLMs. The bottom LLM layers are utilized for parallel recognition and the recognition results are relayed into the top LLM layers for sequential understanding. Specifically, parallel recognition in the bottom LLM layers is implemented via object queries, a popular mechanism in DEtection TRansformer, which we find to harmonize well with the LLM layers. Empirical studies show our MLLM named Octopus improves accuracy on popular MLLM tasks and is up to 5× faster on visual grounding tasks.