Repurposing Language Models into Embedding Models: Finding the Compute-Optimal Recipe
{kind=link}
Abstract
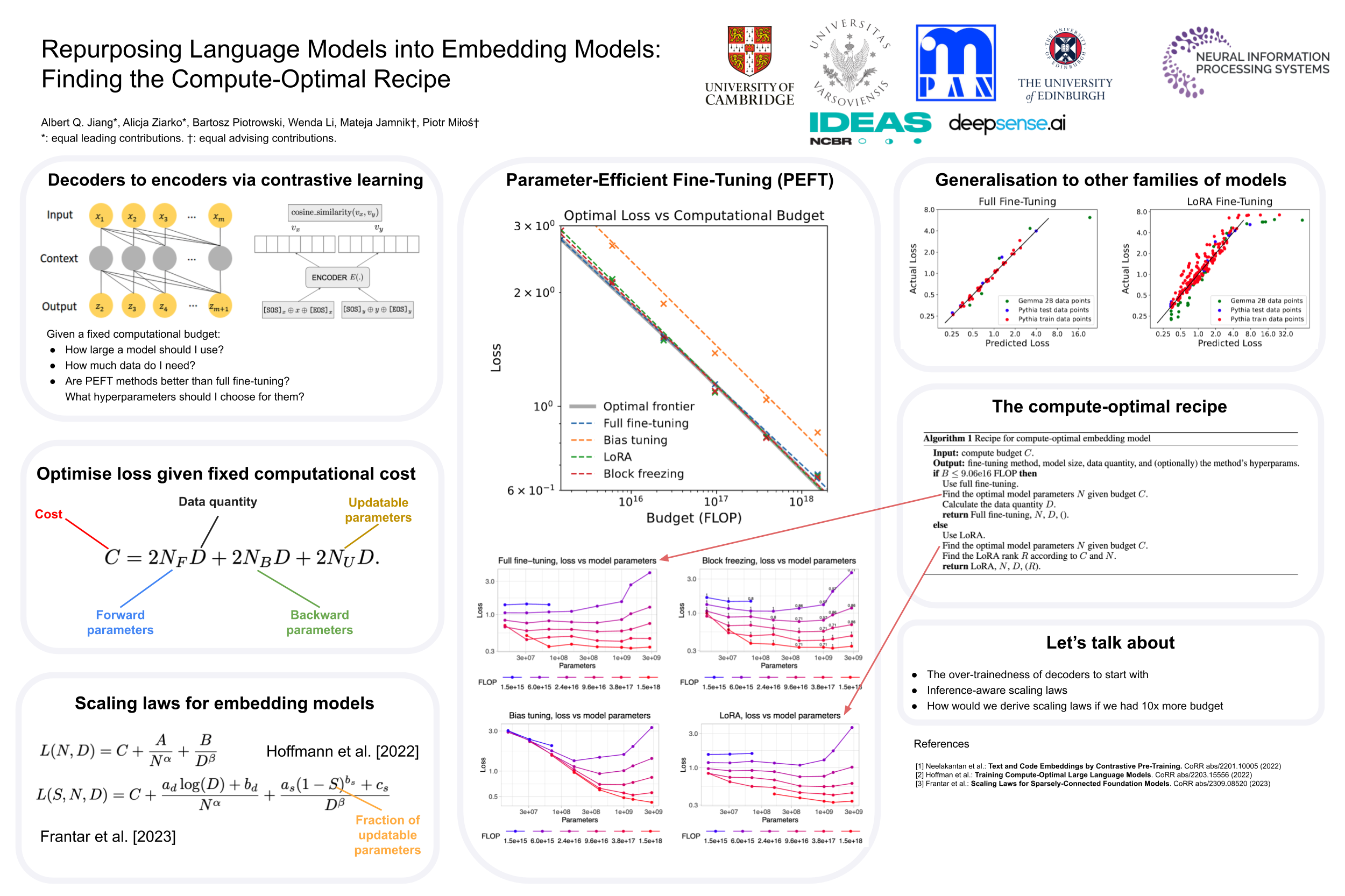
Text embeddings are essential for tasks such as document retrieval, clustering, and semantic similarity assessment. In this paper, we study how to contrastively train text embedding models in a compute-optimal fashion, given a suite of pretrained decoder-only language models. Our innovation is an algorithm that produces optimal configurations of model sizes, data quantities, and fine-tuning methods for text-embedding models at different computational budget levels. The resulting recipe, which we obtain through extensive experiments, can be used by practitioners to make informed design choices for their embedding models. Specifically, our findings suggest that full fine-tuning and Low-Rank Adaptation fine-tuning produce optimal models at lower and higher computational budgets respectively.