Weak-eval-Strong: Evaluating and Eliciting Lateral Thinking of LLMs with Situation Puzzles
{kind=link}
Abstract
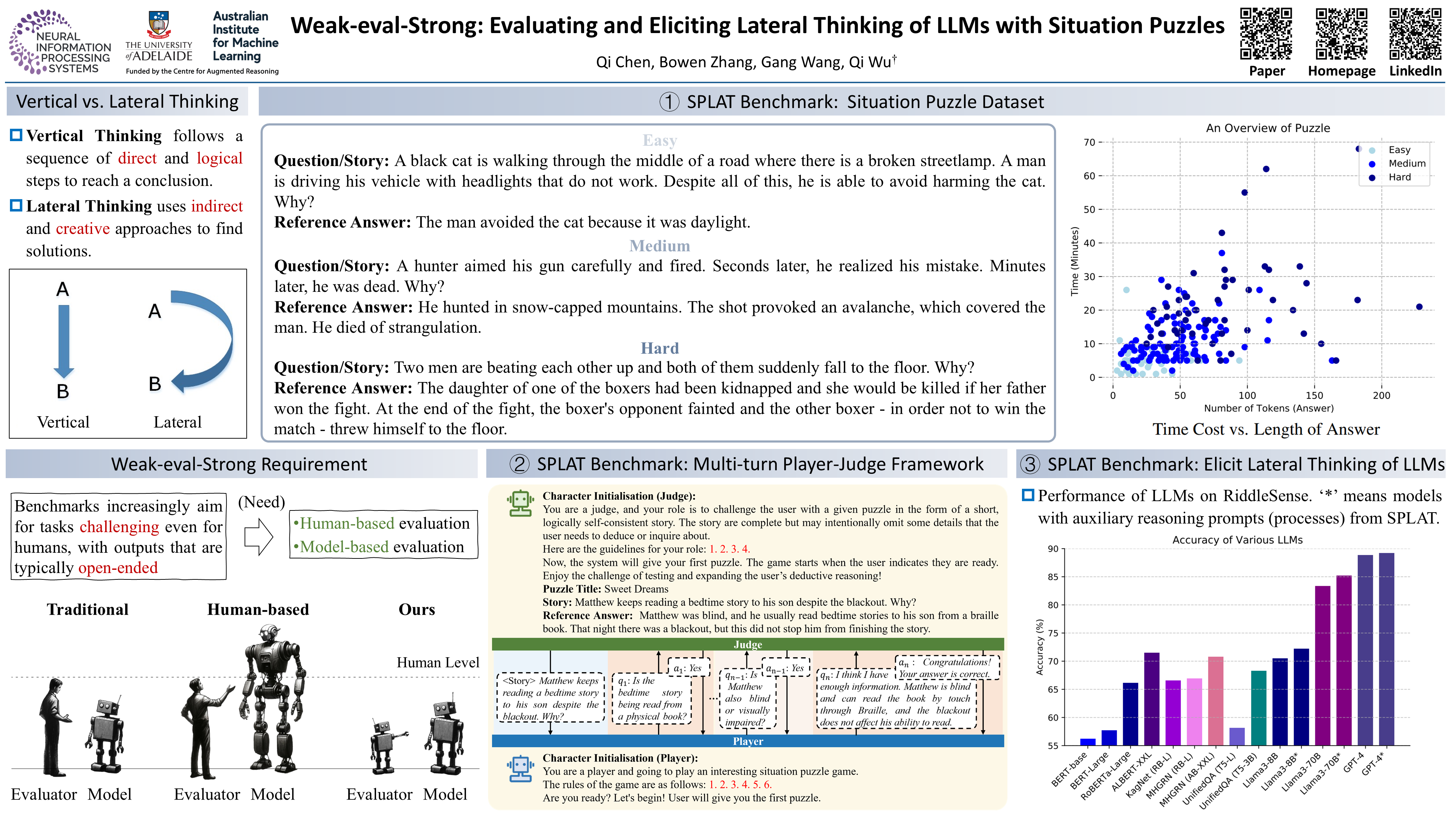
While advancements in NLP have significantly improved the performance of Large Language Models (LLMs) on tasks requiring vertical thinking, their lateral thinking capabilities remain under-explored and challenging to measure due to the complexity of assessing creative thought processes and the scarcity of relevant data. To address these challenges, we introduce SPLAT, a benchmark leveraging Situation Puzzles to evaluate and elicit LAteral Thinking of LLMs. This benchmark, containing 975 graded situation puzzles across three difficulty levels, employs a new multi-turn player-judge framework instead of the traditional model-based evaluation, which often necessitates a stronger evaluation model. This framework simulates an interactive game where the model (player) asks the evaluation model (judge) questions about an incomplete story to infer the full scenario. The judge answers based on a detailed reference scenario or evaluates if the player's predictions align with the reference one. This approach lessens dependence on more robust evaluation models, enabling the assessment of state-of-the-art LLMs. The experiments demonstrate that a robust evaluation model, such as WizardLM-2, closely matches human judgements in both intermediate question-answering and final scenario accuracy, achieving over 80% agreement--similar to the agreement levels among humans. Furthermore, applying data and reasoning processes from our benchmark to other lateral thinking-related benchmarks, e.g., RiddleSense and BrainTeaser, leads to performance enhancements. This suggests that our benchmark effectively evaluates and elicits the lateral thinking abilities of LLMs.