TrAct: Making First-layer Pre-Activations Trainable
{kind=link}
Abstract
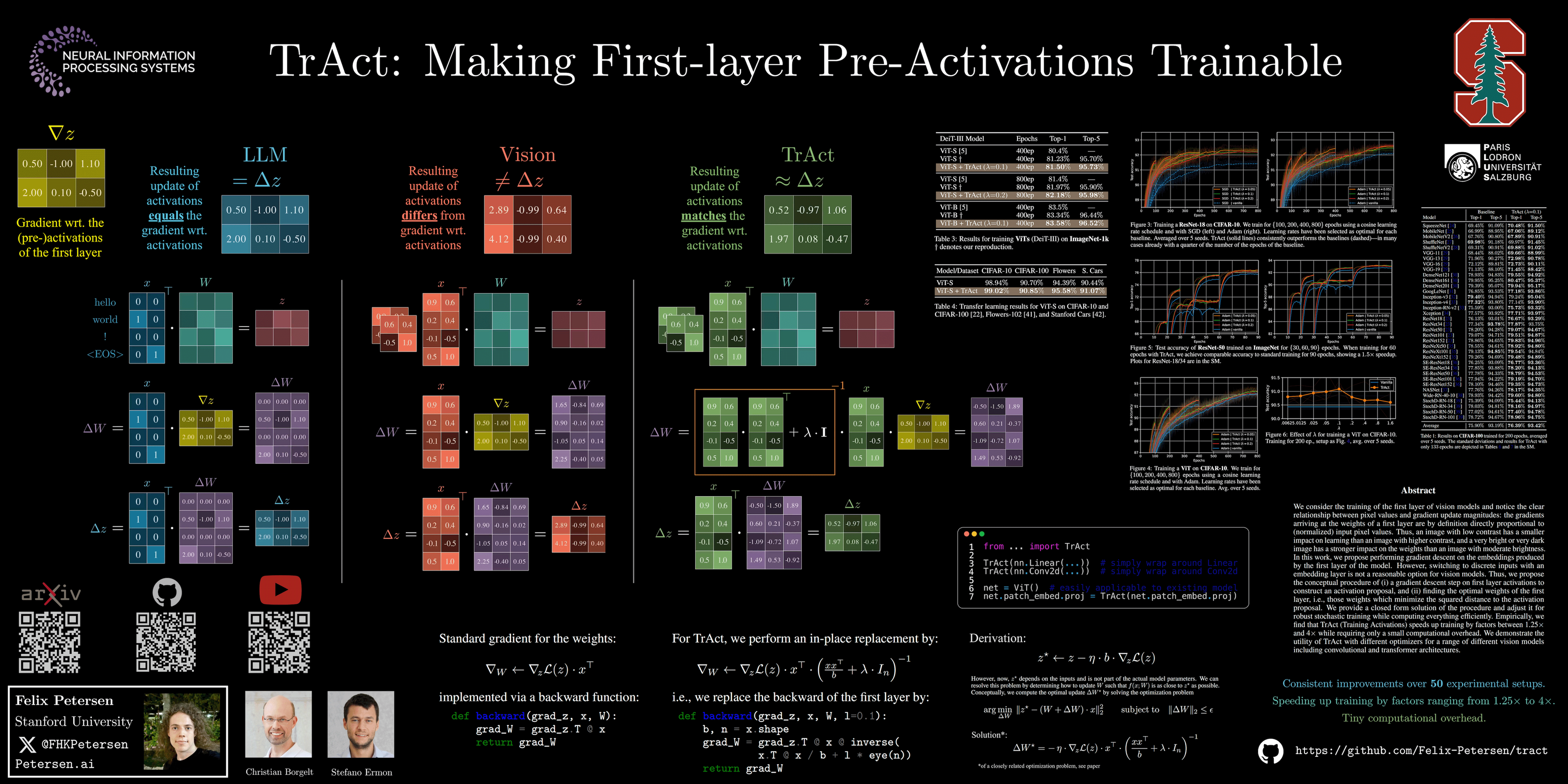
We consider the training of the first layer of vision models and notice the clear relationship between pixel values and gradient update magnitudes: the gradients arriving at the weights of a first layer are by definition directly proportional to (normalized) input pixel values. Thus, an image with low contrast has a smaller impact on learning than an image with higher contrast, and a very bright or very dark image has a stronger impact on the weights than an image with moderate brightness. In this work, we propose performing gradient descent on the embeddings produced by the first layer of the model. However, switching to discrete inputs with an embedding layer is not a reasonable option for vision models. Thus, we propose the conceptual procedure of (i) a gradient descent step on first layer activations to construct an activation proposal, and (ii) finding the optimal weights of the first layer, i.e., those weights which minimize the squared distance to the activation proposal. We provide a closed form solution of the procedure and adjust it for robust stochastic training while computing everything efficiently. Empirically, we find that TrAct (Training Activations) speeds up training by factors between 1.25x and 4x while requiring only a small computational overhead. We demonstrate the utility of TrAct with different optimizers for a range of different vision models including convolutional and transformer architectures.