Geometric Exploitation for Indoor Panoramic Semantic Segmentation
{kind=link}
Abstract
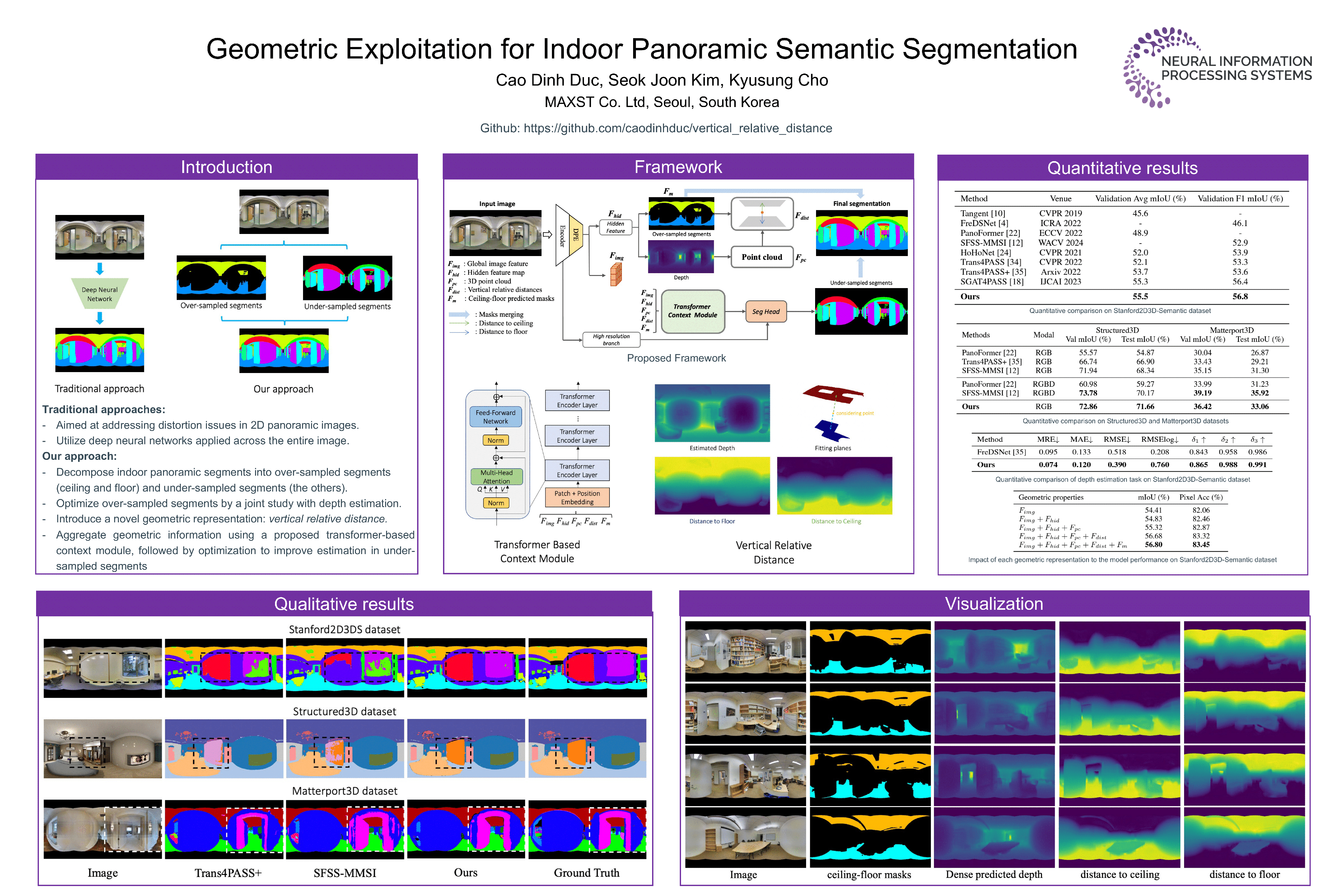
PAnoramic Semantic Segmentation (PASS) is an important task in computer vision,as it enables semantic understanding of a 360° environment. Currently,most of existing works have focused on addressing the distortion issues in 2Dpanoramic images without considering spatial properties of indoor scene. Thisrestricts PASS methods in perceiving contextual attributes to deal with the ambiguitywhen working with monocular images. In this paper, we propose a novelapproach for indoor panoramic semantic segmentation. Unlike previous works,we consider the panoramic image as a composition of segment groups: oversampledsegments, representing planar structures such as floors and ceilings, andunder-sampled segments, representing other scene elements. To optimize eachgroup, we first enhance over-sampled segments by jointly optimizing with a densedepth estimation task. Then, we introduce a transformer-based context modulethat aggregates different geometric representations of the scene, combinedwith a simple high-resolution branch, it serves as a robust hybrid decoder forestimating under-sampled segments, effectively preserving the resolution of predictedmasks while leveraging various indoor geometric properties. Experimentalresults on both real-world (Stanford2D3DS, Matterport3D) and synthetic (Structured3D)datasets demonstrate the robustness of our framework, by setting newstate-of-the-arts in almost evaluations, The code and updated results are availableat: https://github.com/caodinhduc/verticalrelativedistance.