Understanding Hallucinations in Diffusion Models through Mode Interpolation
{kind=link}
Abstract
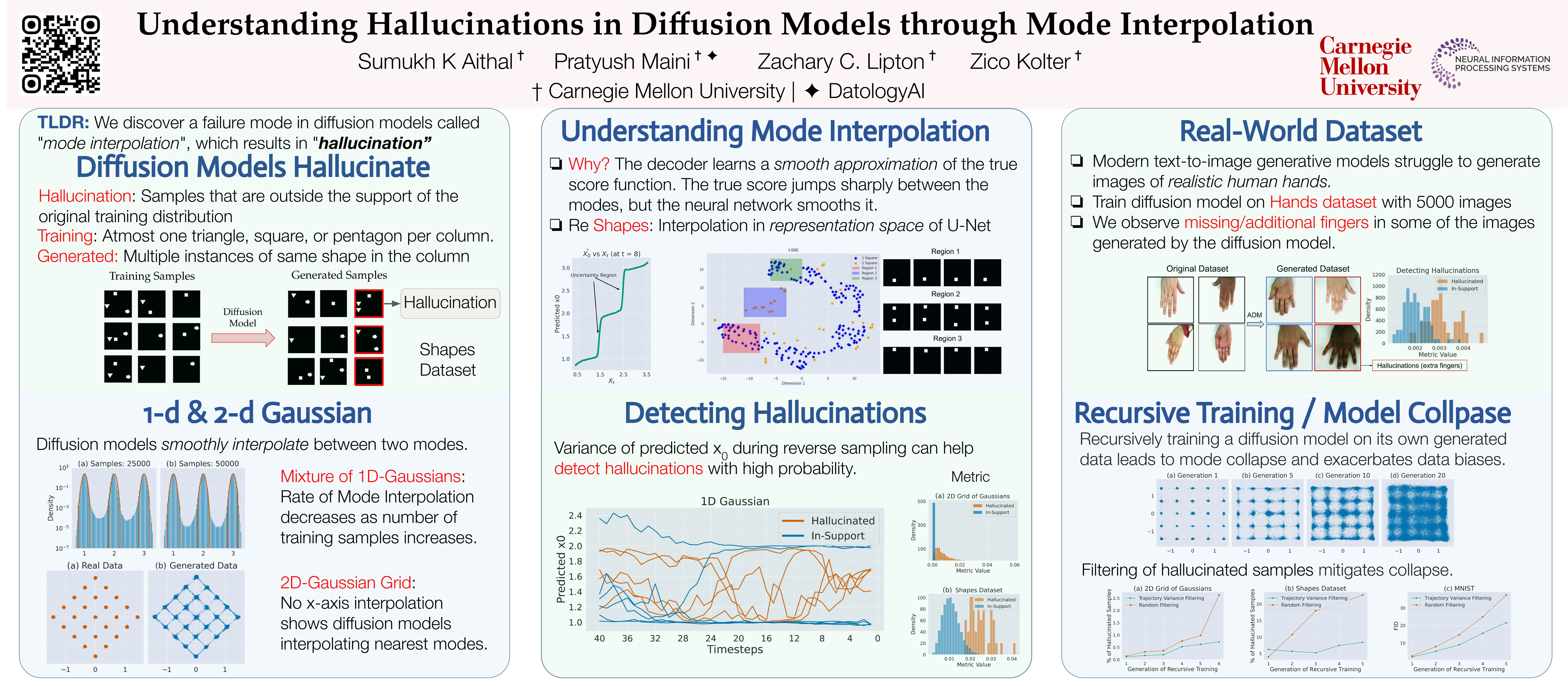
Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit ''hallucinations'' samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly ``interpolate'' between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. We extend the validity of mode interpolation in real-world datasets by explaining the unexpected generation of images with additional or missing fingers similar to those produced by popular text-to-image generative models. Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95\% of hallucinations at generation time. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on datasets like MNIST .