Geometry-aware training of factorized layers in tensor Tucker format
{kind=link}
Abstract
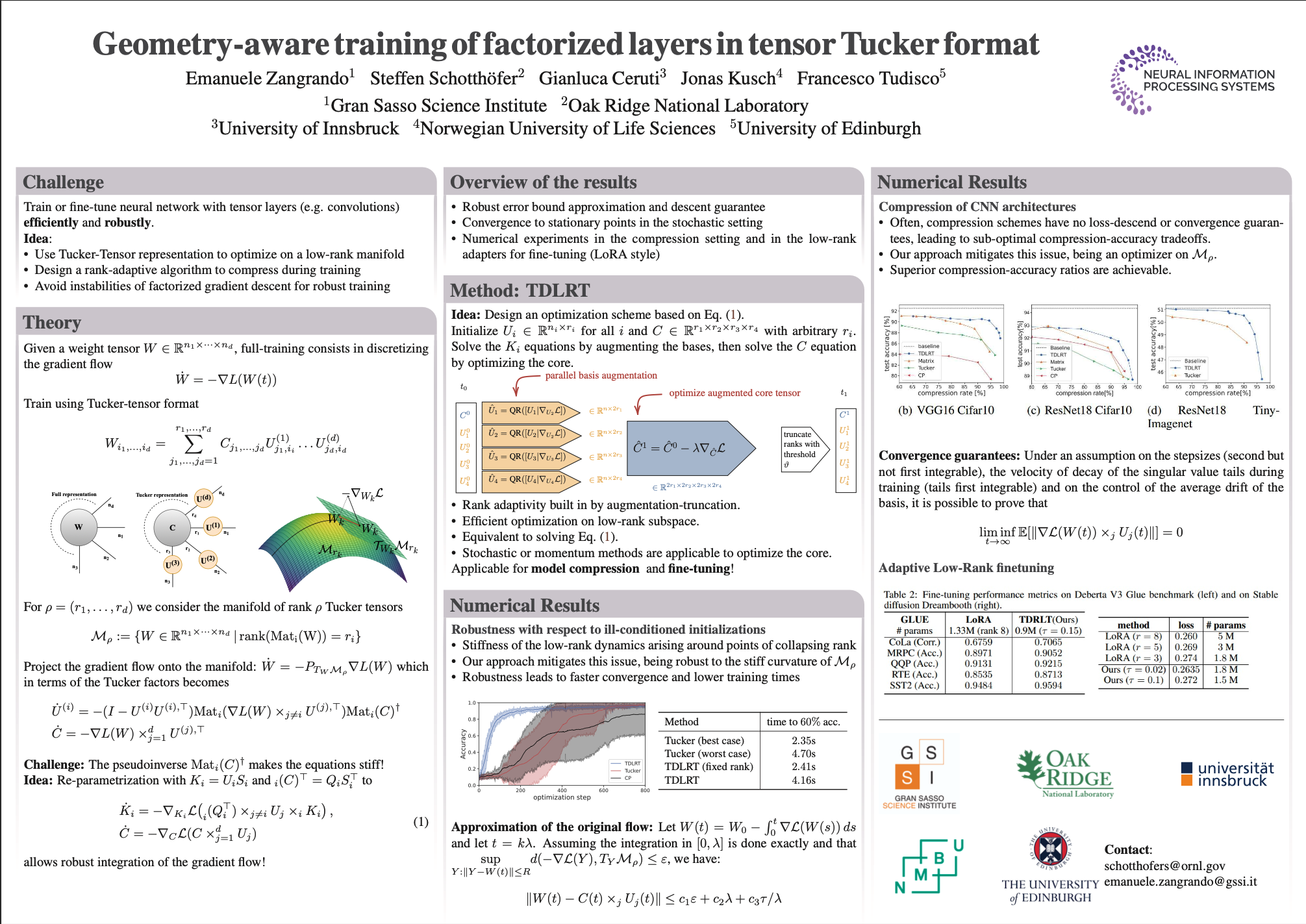
Reducing parameter redundancies in neural network architectures is crucial for achieving feasible computational and memory requirements during train and inference of large networks. Given its easy implementation and flexibility, one promising approach is layer factorization, which reshapes weight tensors into a matrix format and parameterizes it as the product of two rank-r matrices. However, this family of approaches often requires an initial full-model warm-up phase, prior knowledge of a feasible rank, and it is sensitive to parameter initialization.In this work, we introduce a novel approach to train the factors of a Tucker decomposition of the weight tensors. Our training proposal proves to be optimal in locally approximating the original unfactorized dynamics and stable for the initialization. Furthermore, the rank of each mode is dynamically updated during training.We provide a theoretical analysis of the algorithm, showing convergence, approximation and local descent guarantees. The method's performance is further illustrated through a variety of experiments, showing remarkable training compression rates and comparable or even better performance than the full baseline and alternative layer factorization strategies.