Make Your LLM Fully Utilize the Context
{kind=link}
Abstract
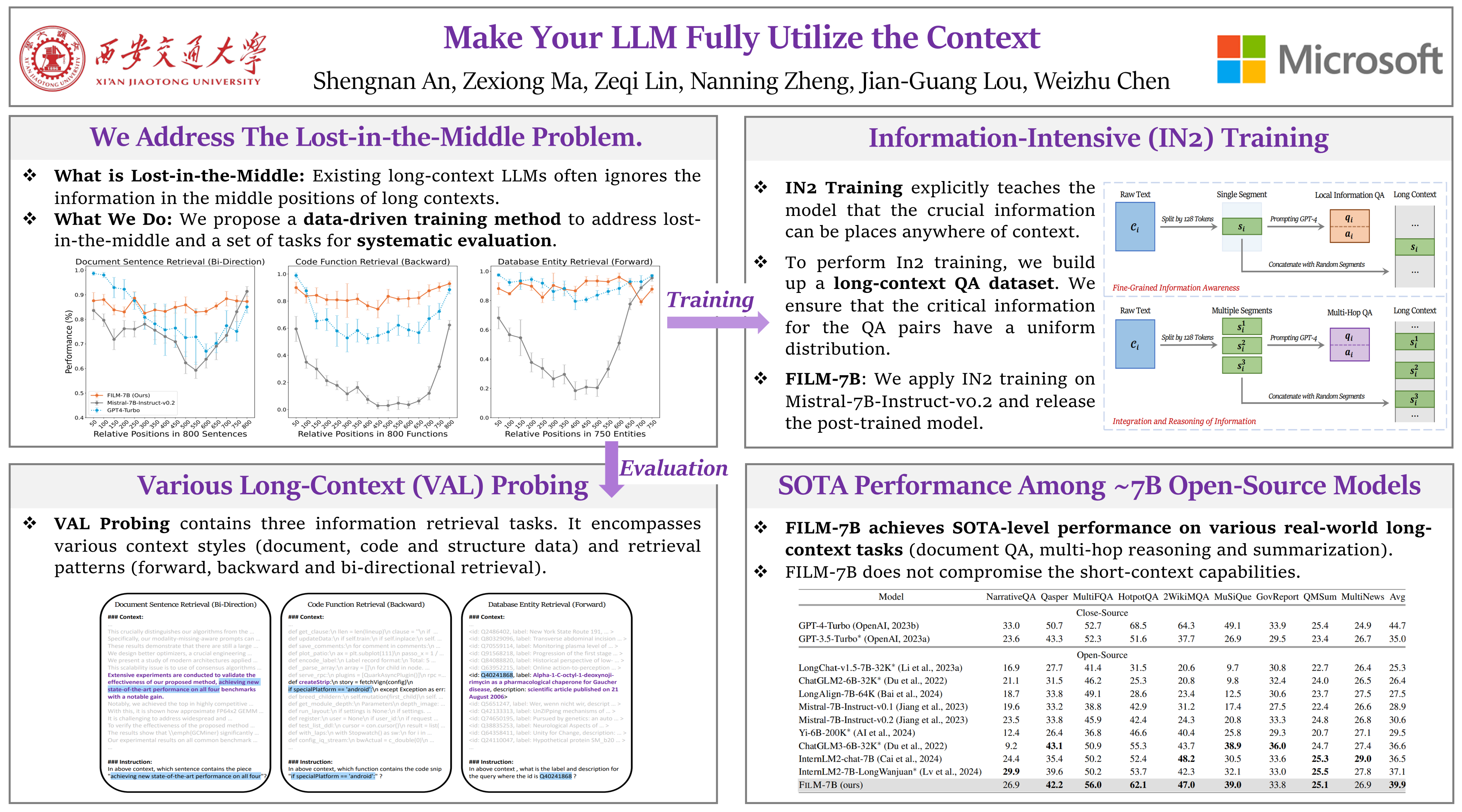
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge.We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information.Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle.Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments.Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FIll-in-the-Middle).To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval).The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window.Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU).