Stepwise Alignment for Constrained Language Model Policy Optimization
{kind=link}
Abstract
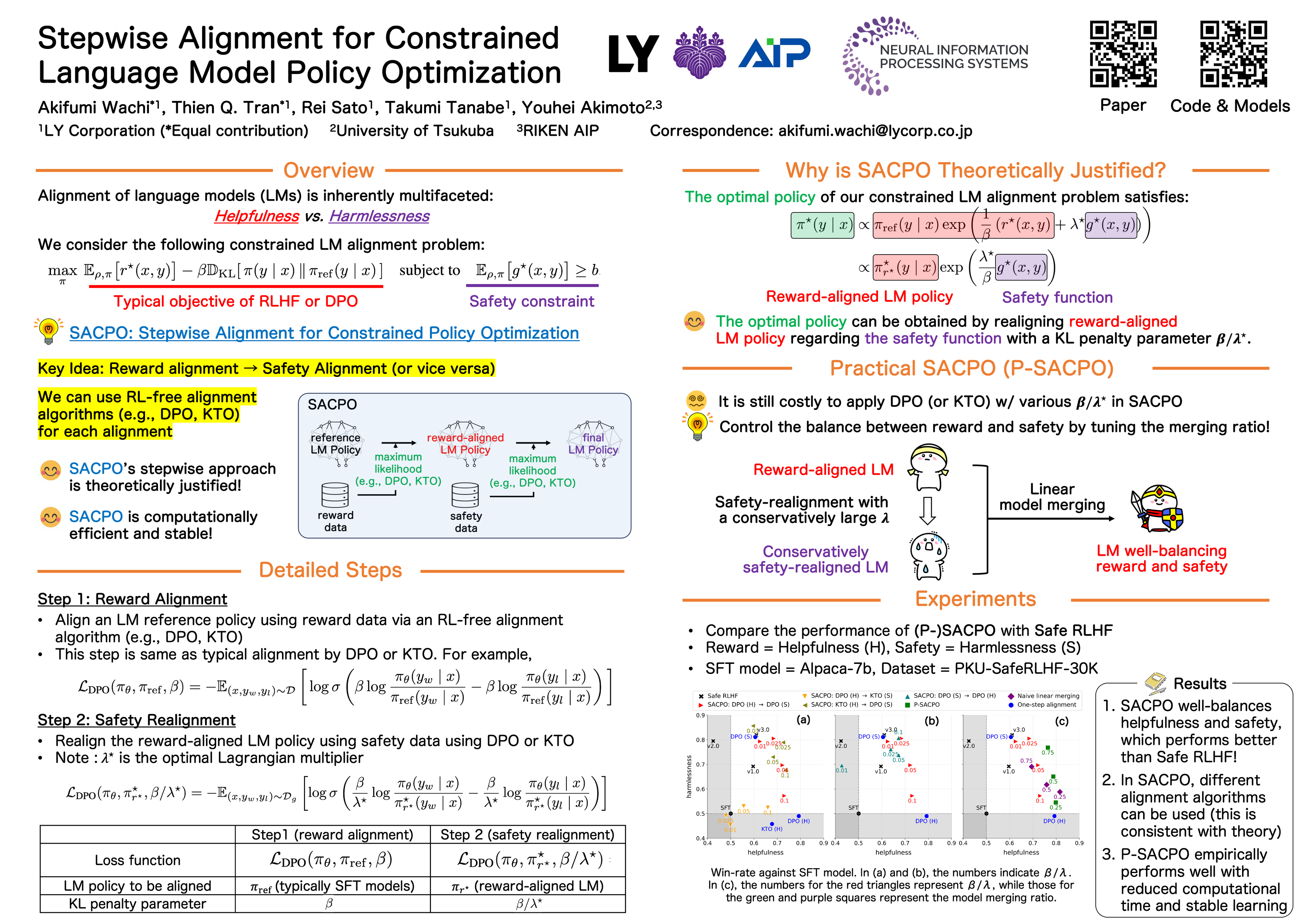
Safety and trustworthiness are indispensable requirements for real-world applications of AI systems using large language models (LLMs). This paper formulates human value alignment as an optimization problem of the language model policy to maximize reward under a safety constraint, and then proposes an algorithm, Stepwise Alignment for Constrained Policy Optimization (SACPO). One key idea behind SACPO, supported by theory, is that the optimal policy incorporating reward and safety can be directly obtained from a reward-aligned policy. Building on this key idea, SACPO aligns LLMs step-wise with each metric while leveraging simple yet powerful alignment algorithms such as direct preference optimization (DPO). SACPO offers several advantages, including simplicity, stability, computational efficiency, and flexibility of algorithms and datasets. Under mild assumptions, our theoretical analysis provides the upper bounds on optimality and safety constraint violation. Our experimental results show that SACPO can fine-tune Alpaca-7B better than the state-of-the-art method in terms of both helpfulness and harmlessness.