Accuracy is Not All You Need
{kind=link}
Abstract
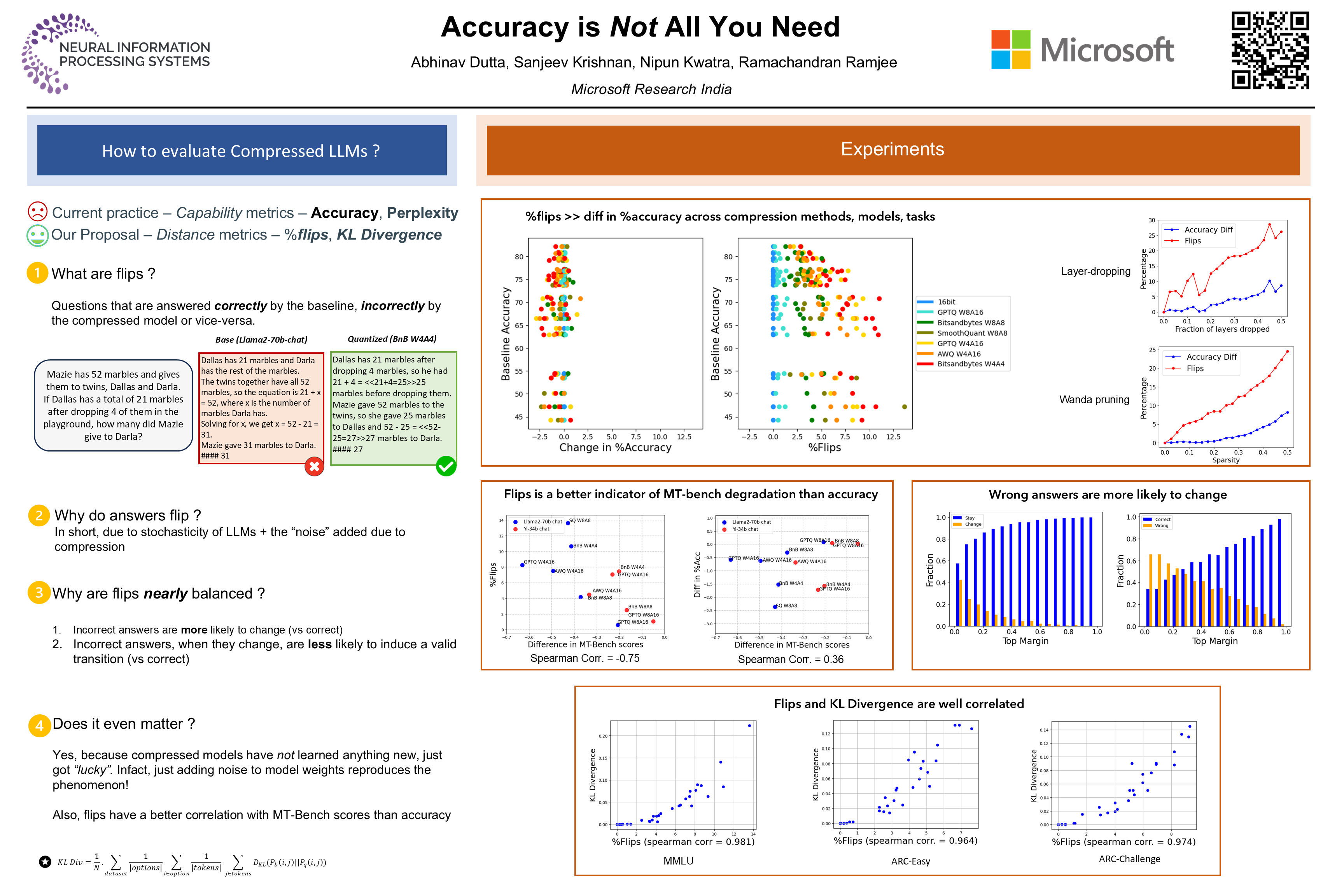
When Large Language Models (LLMs) are compressed using techniques such as quantization, the predominant way to demonstrate the validity of such techniques is by measuring the model's accuracy on various benchmarks. If the accuracies of the baseline model and the compressed model are close, it is assumed that there was negligible degradation in quality. However, even when the accuracy of baseline and compressed model are similar, we observe the phenomenon of flips, wherein answers change from correct to incorrect and vice versa in proportion. We conduct a detailed study of metrics across multiple compression techniques, models and datasets, demonstrating that the behavior of compressed models as visible to end-users is often significantly different from the baseline model, even when accuracy is similar. We further evaluate compressed models qualitatively and quantitatively using MT-Bench and show that compressed models exhibiting high flips are worse than baseline models in this free-form generative task. Thus, we argue that accuracy and perplexity are necessary but not sufficient for evaluating compressed models, since these metrics hide large underlying changes that have not been observed by previous work. Hence, compression techniques should also be evaluated using distance metrics. We propose two such distance metrics, KL-Divergence and flips, and show that they are well correlated.