LoQT: Low-Rank Adapters for Quantized Pretraining
{kind=link}
Abstract
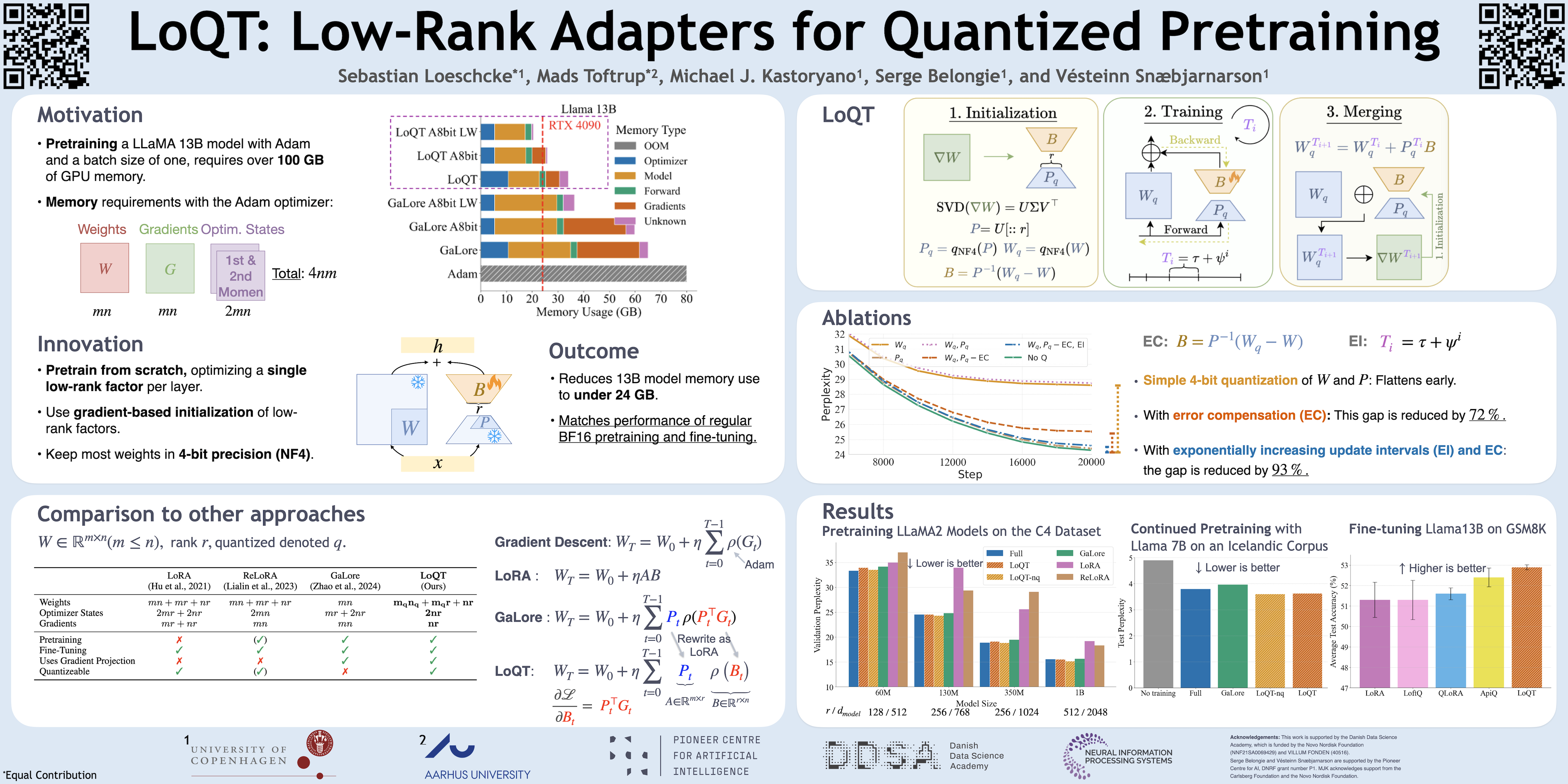
Despite advances using low-rank adapters and quantization, pretraining of large models on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose Low-Rank Adapters for Quantized Training (LoQT), a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning models. We demonstrate this for language modeling and downstream task adaptation, finding that LoQT enables efficient training of models up to 7B parameters on a 24GB GPU. We also demonstrate the feasibility of training a 13B model using per-layer gradient updates on the same hardware.