Enhancing LLM Reasoning via Vision-Augmented Prompting
{kind=link}
Abstract
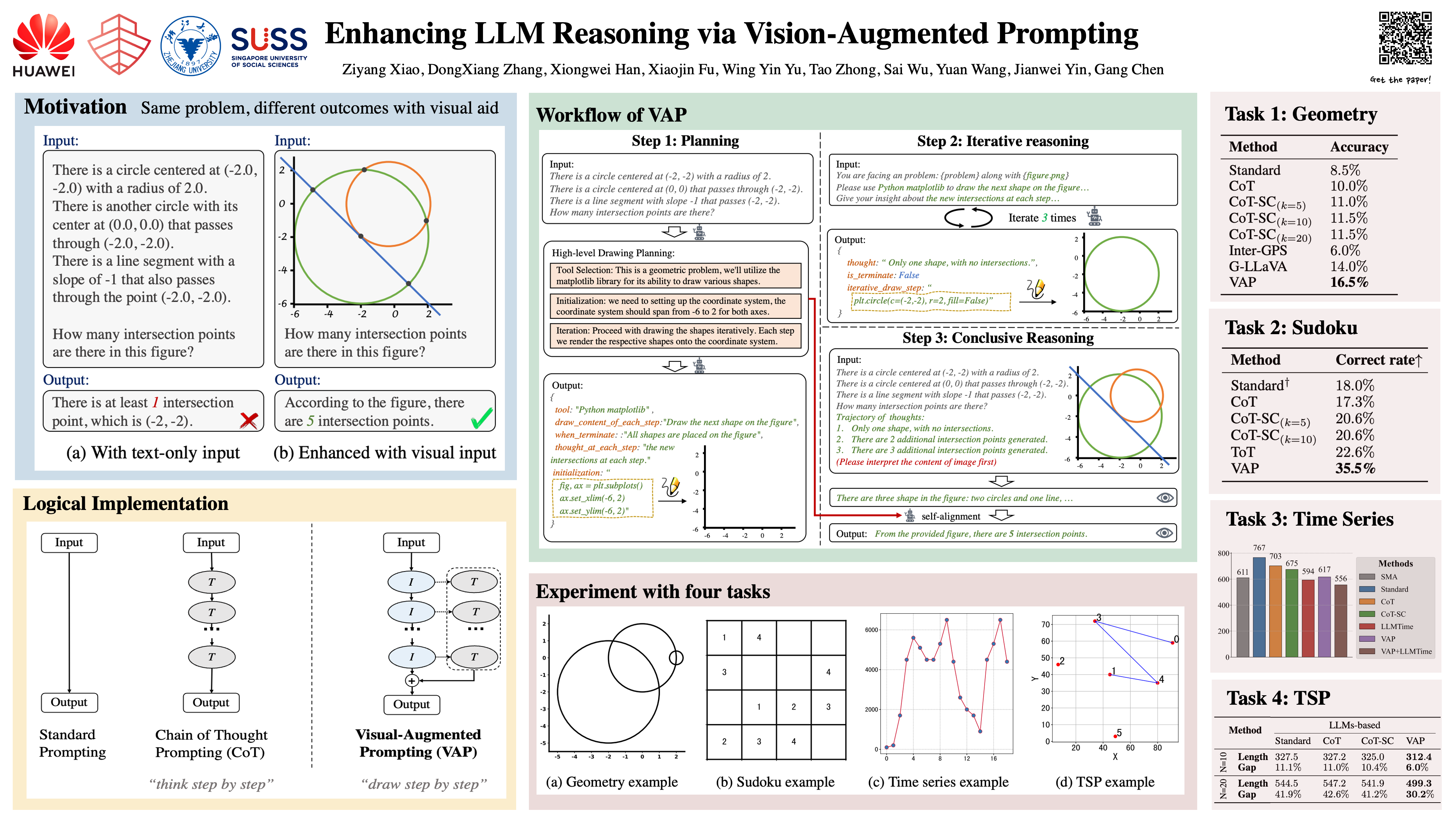
Verbal and visual-spatial information processing are two critical subsystems that activate different brain regions and often collaborate together for cognitive reasoning. Despite the rapid advancement of LLM-based reasoning, the mainstream frameworks, such as Chain-of-Thought (CoT) and its variants, primarily focus on the verbal dimension, resulting in limitations in tackling reasoning problems with visual and spatial clues. To bridge the gap, we propose a novel dual-modality reasoning framework called Vision-Augmented Prompting (VAP). Upon receiving a textual problem description, VAP automatically synthesizes an image from the visual and spatial clues by utilizing external drawing tools. Subsequently, VAP formulates a chain of thought in both modalities and iteratively refines the synthesized image. Finally, a conclusive reasoning scheme based on self-alignment is proposed for final result generation. Extensive experiments are conducted across four versatile tasks, including solving geometry problems, Sudoku, time series prediction, and travelling salesman problem. The results validated the superiority of VAP over existing LLMs-based reasoning frameworks.