RL-GPT: Integrating Reinforcement Learning and Code-as-policy
{kind=link}
Abstract
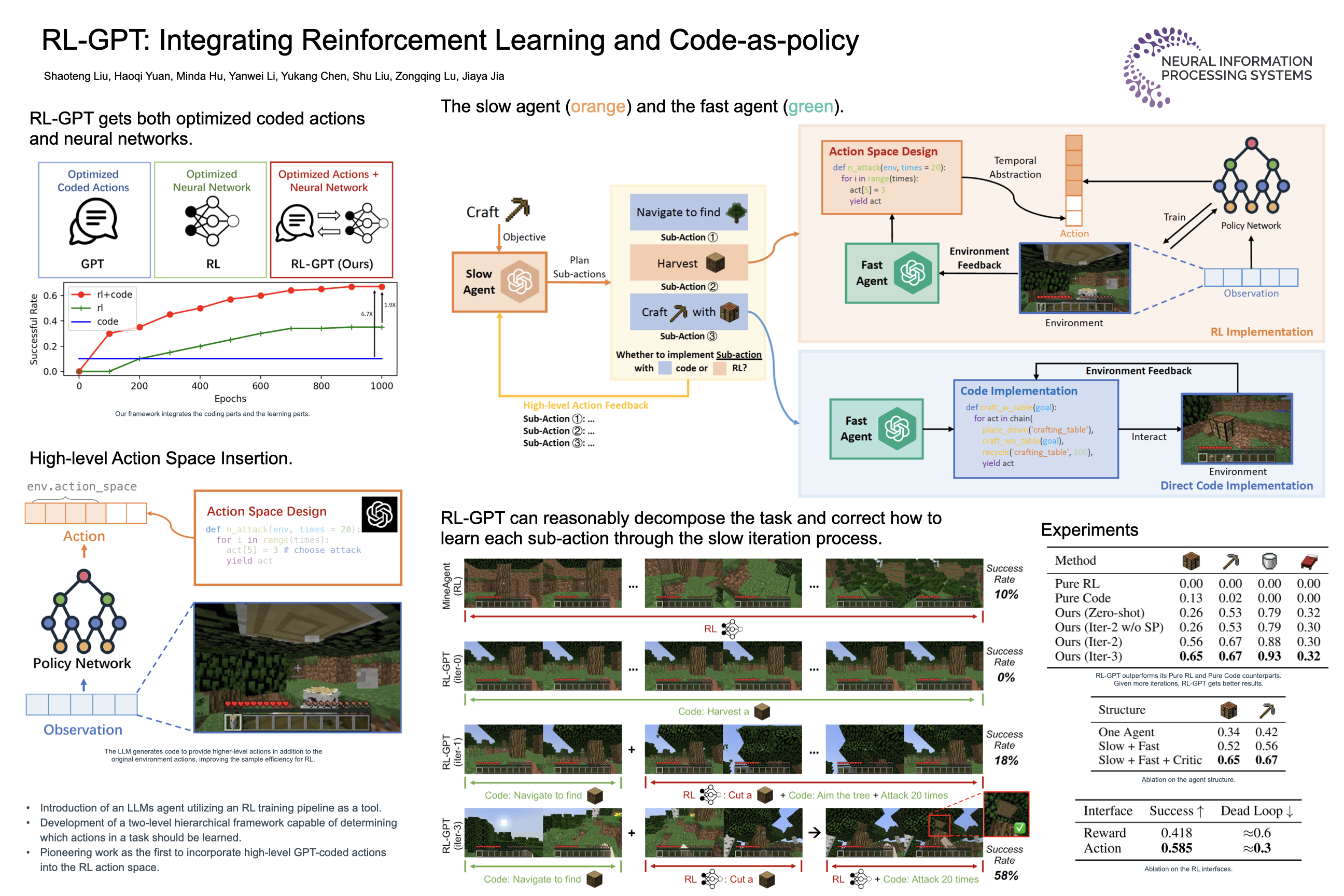
Large Language Models (LLMs) have demonstrated proficiency in utilizing various tools by coding, yet they face limitations in handling intricate logic and precise control. In embodied tasks, high-level planning is amenable to direct coding, while low-level actions often necessitate task-specific refinement, such as Reinforcement Learning (RL). To seamlessly integrate both modalities, we introduce a two-level hierarchical framework, RL-GPT, comprising a slow agent and a fast agent. The slow agent analyzes actions suitable for coding, while the fast agent executes coding tasks. This decomposition effectively focuses each agent on specific tasks, proving highly efficient within our pipeline. Our approach outperforms traditional RL methods and existing GPT agents, demonstrating superior efficiency. In the Minecraft game, it rapidly obtains diamonds within a single day on an RTX3090. Additionally, it achieves SOTA performance across all designated MineDojo tasks.