Robot Policy Learning with Temporal Optimal Transport Reward
{kind=link}
Abstract
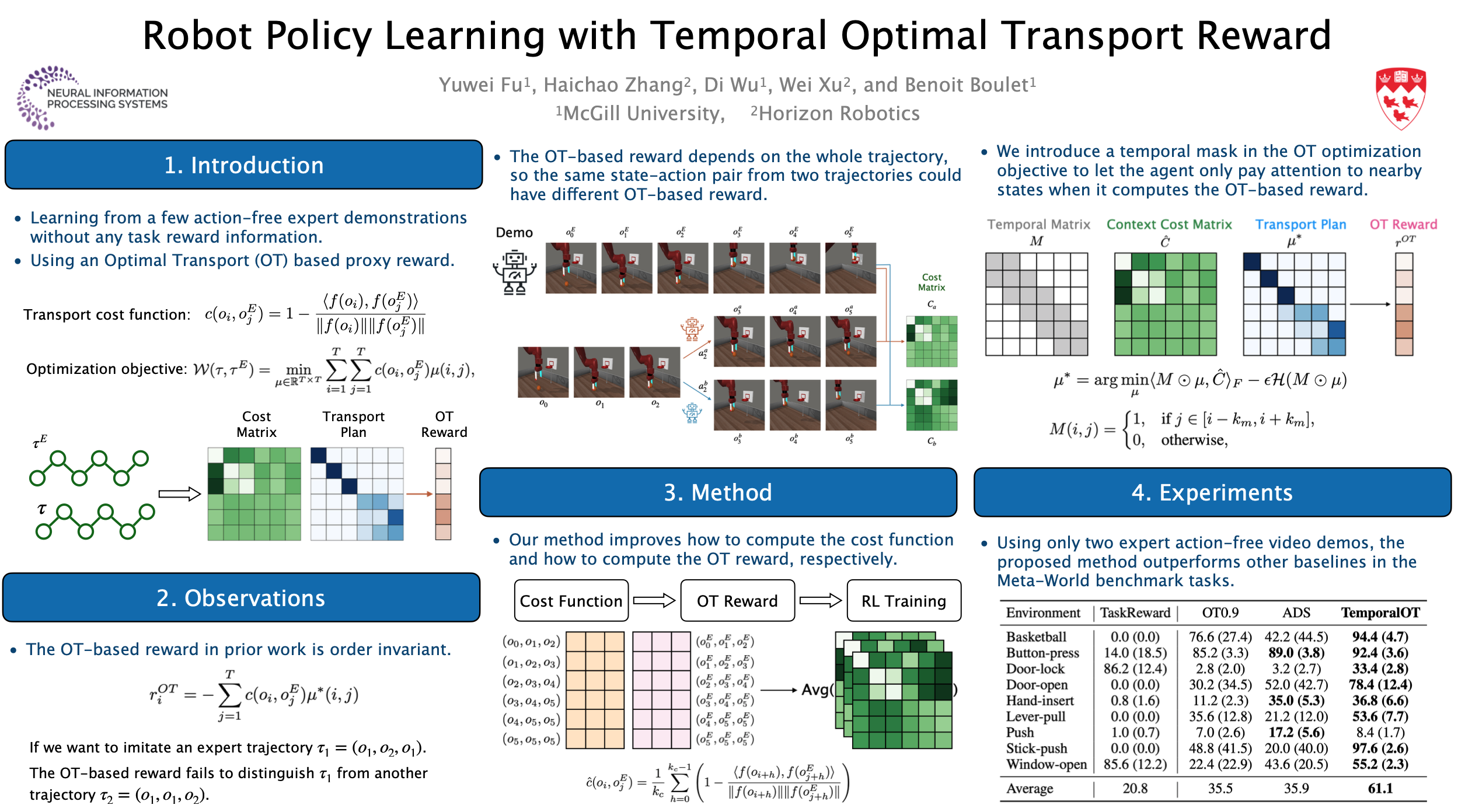
Reward specification is one of the most tricky problems in Reinforcement Learning, which usually requires tedious hand engineering in practice. One promising approach to tackle this challenge is to adopt existing expert video demonstrations for policy learning. Some recent work investigates how to learn robot policies from only a single/few expert video demonstrations. For example, reward labeling via Optimal Transport (OT) has been shown to be an effective strategy to generate a proxy reward by measuring the alignment between the robot trajectory and the expert demonstrations. However, previous work mostly overlooks that the OT reward is invariant to temporal order information, which could bring extra noise to the reward signal. To address this issue, in this paper, we introduce the Temporal Optimal Transport (TemporalOT) reward to incorporate temporal order information for learning a more accurate OT-based proxy reward. Extensive experiments on the Meta-world benchmark tasks validate the efficacy of the proposed method. Our code is available at: https://github.com/fuyw/TemporalOT.