Banded Square Root Matrix Factorization for Differentially Private Model Training
{kind=link}
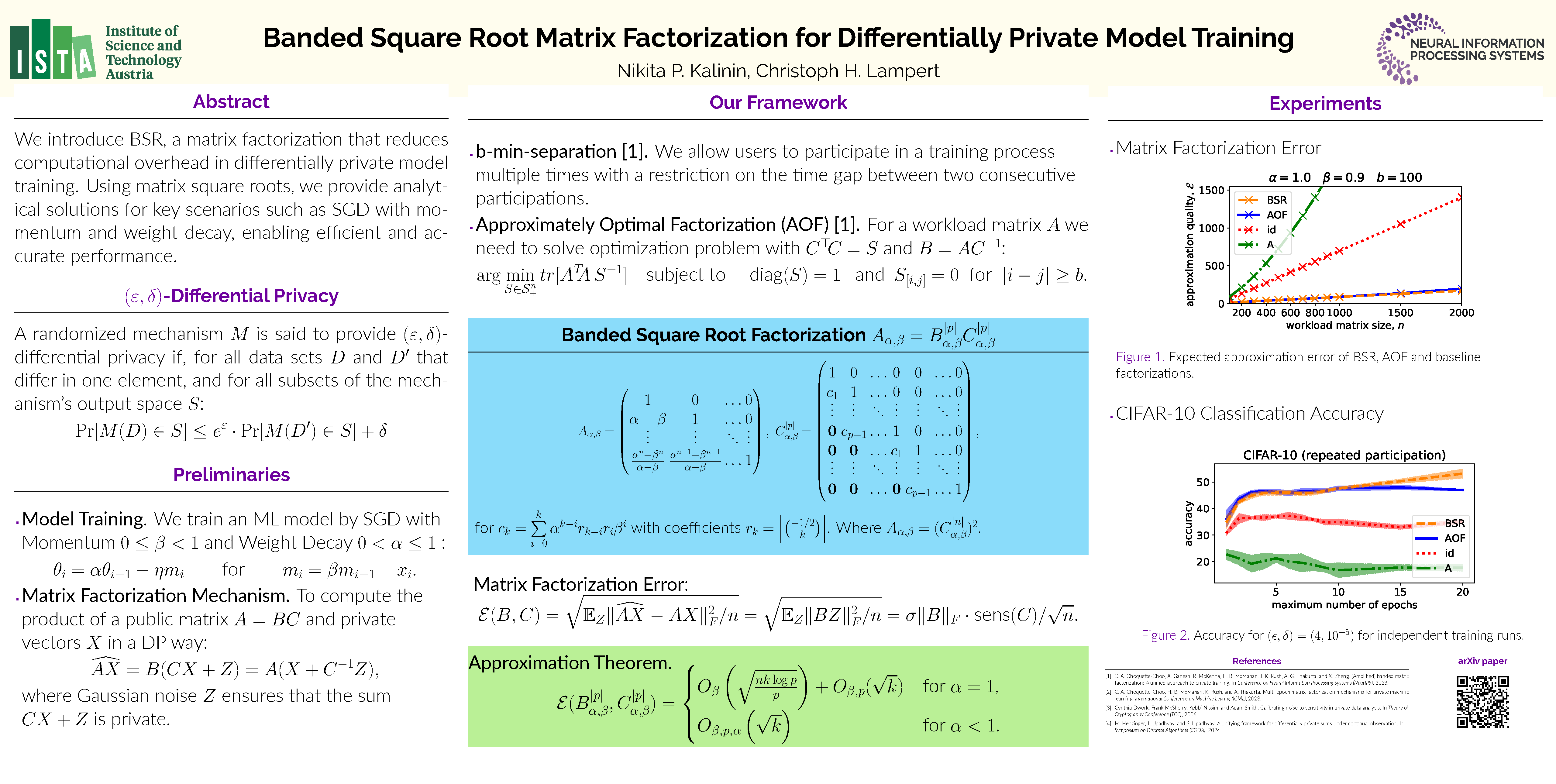
Abstract
Current state-of-the-art methods for differentially private model training are based on matrix factorization techniques. However, these methods suffer from high computational overhead because they require numerically solving a demanding optimization problem to determine an approximately optimal factorization prior to the actual model training. In this work, we present a new matrix factorization approach, BSR, which overcomes this computational bottleneck. By exploiting properties of the standard matrix square root, BSR allows to efficiently handle also large-scale problems. For the key scenario of stochastic gradient descent with momentum and weight decay, we even derive analytical expressions for BSR that render the computational overhead negligible. We prove bounds on the approximation quality that hold both in the centralized and in the federated learning setting. Our numerical experiments demonstrate that models trained using BSR perform on par with the best existing methods, while completely avoiding their computational overhead.