Even Sparser Graph Transformers
{kind=link}
Abstract
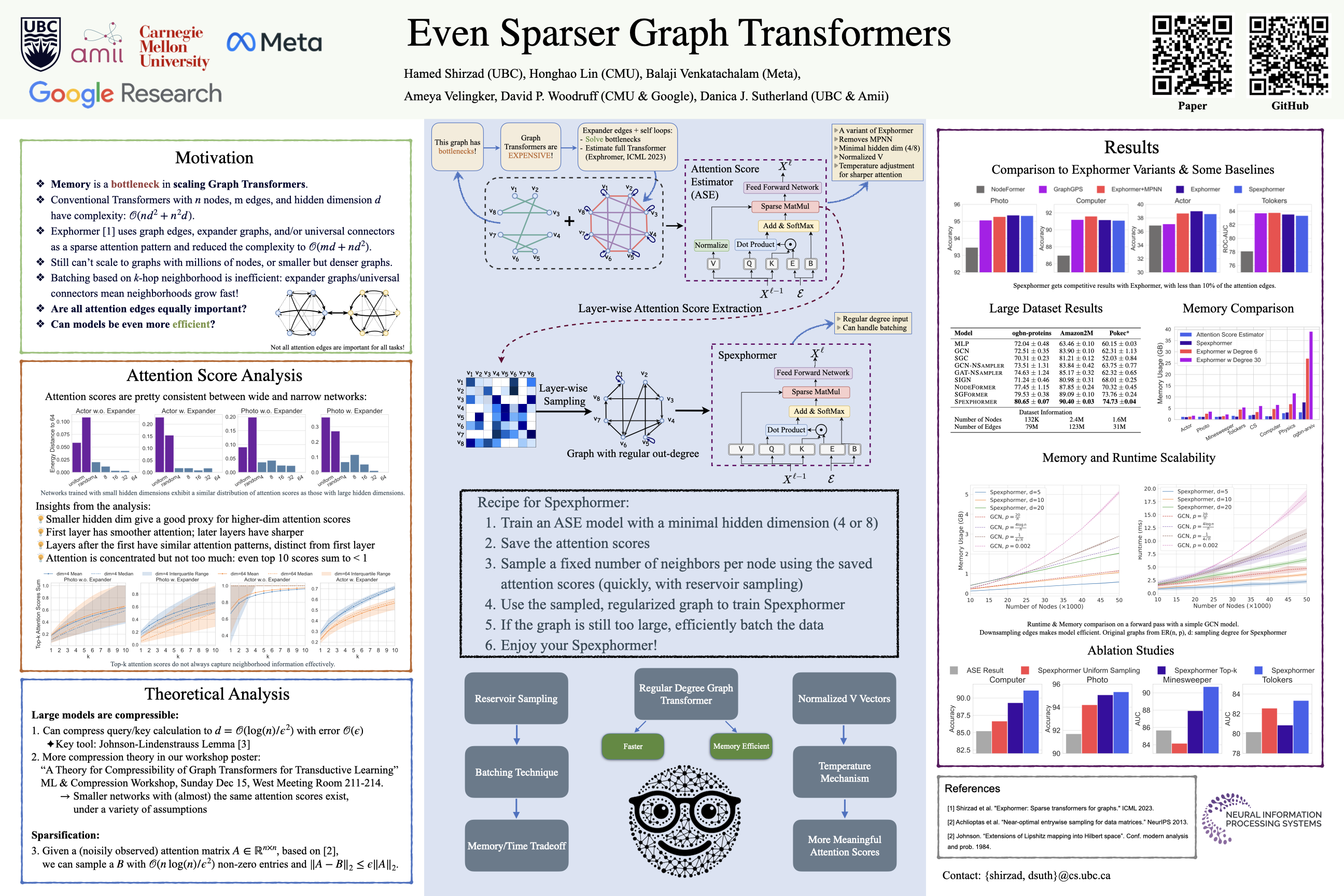
Graph Transformers excel in long-range dependency modeling, but generally require quadratic memory complexity in the number of nodes in an input graph, and hence have trouble scaling to large graphs. Sparse attention variants such as Exphormer can help, but may require high-degree augmentations to the input graph for good performance, and do not attempt to sparsify an already-dense input graph. As the learned attention mechanisms tend to use few of these edges, however, such high-degree connections may be unnecessary. We show (empirically and with theoretical backing) that attention scores on graphs are usually quite consistent across network widths, and use this observation to propose a two-stage procedure, which we call Spexphormer: first, train a narrow network on the full augmented graph. Next, use only the active connections to train a wider network on a much sparser graph. We establish theoretical conditions when a narrow network's attention scores can match those of a wide network, and show that Spexphormer achieves good performance with drastically reduced memory requirements on various graph datasets.