Enhancing Robustness in Deep Reinforcement Learning: A Lyapunov Exponent Approach
{kind=link}
Abstract
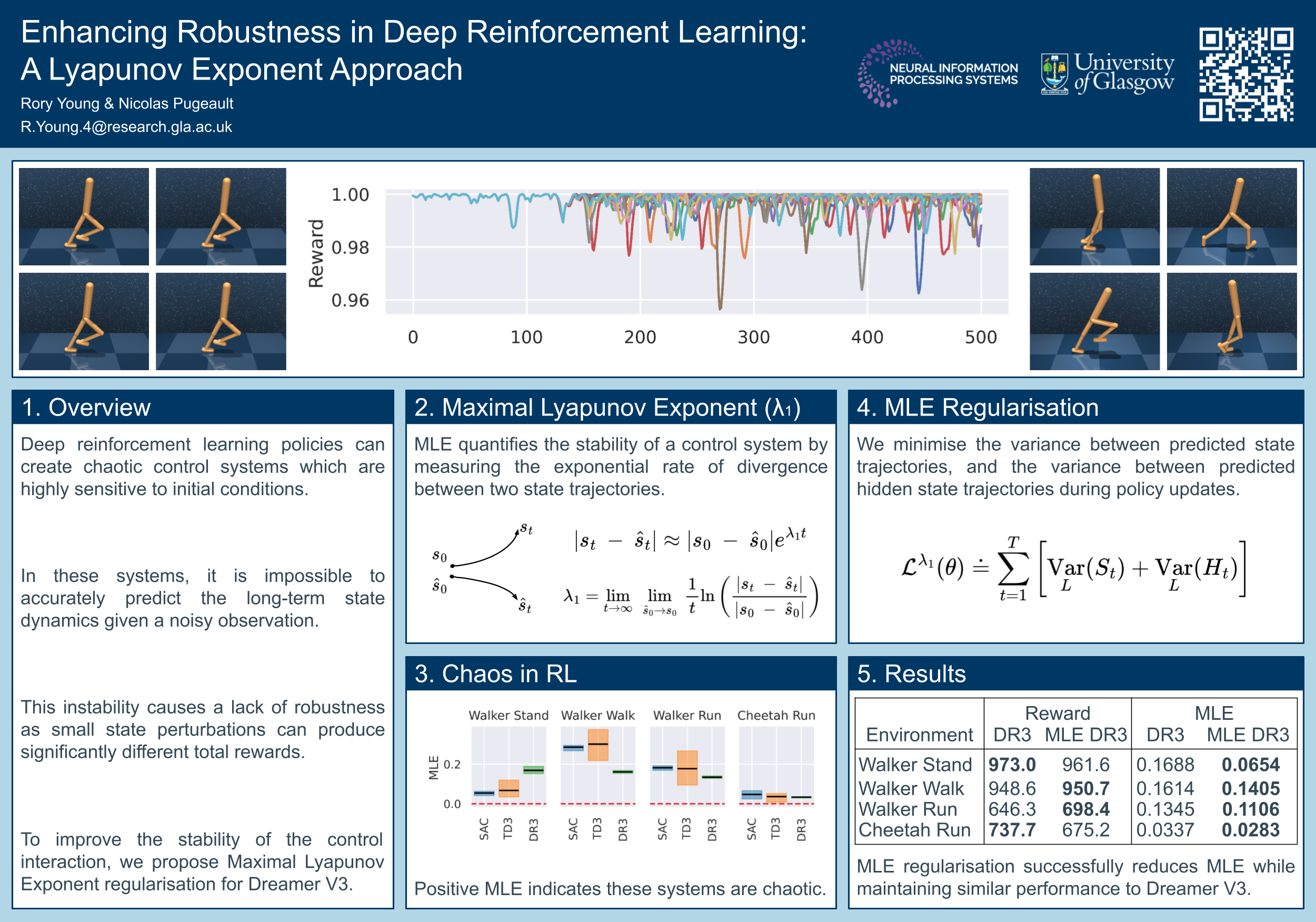
Deep reinforcement learning agents achieve state-of-the-art performance in a wide range of simulated control tasks. However, successful applications to real-world problems remain limited. One reason for this dichotomy is because the learnt policies are not robust to observation noise or adversarial attacks. In this paper, we investigate the robustness of deep RL policies to a single small state perturbation in deterministic continuous control tasks. We demonstrate that RL policies can be deterministically chaotic, as small perturbations to the system state have a large impact on subsequent state and reward trajectories. This unstable non-linear behaviour has two consequences: first, inaccuracies in sensor readings, or adversarial attacks, can cause significant performance degradation; second, even policies that show robust performance in terms of rewards may have unpredictable behaviour in practice. These two facets of chaos in RL policies drastically restrict the application of deep RL to real-world problems. To address this issue, we propose an improvement on the successful Dreamer V3 architecture, implementing Maximal Lyapunov Exponent regularisation. This new approach reduces the chaotic state dynamics, rendering the learnt policies more resilient to sensor noise or adversarial attacks and thereby improving the suitability of deep reinforcement learning for real-world applications.