Preference Alignment with Flow Matching
{kind=link}
Abstract
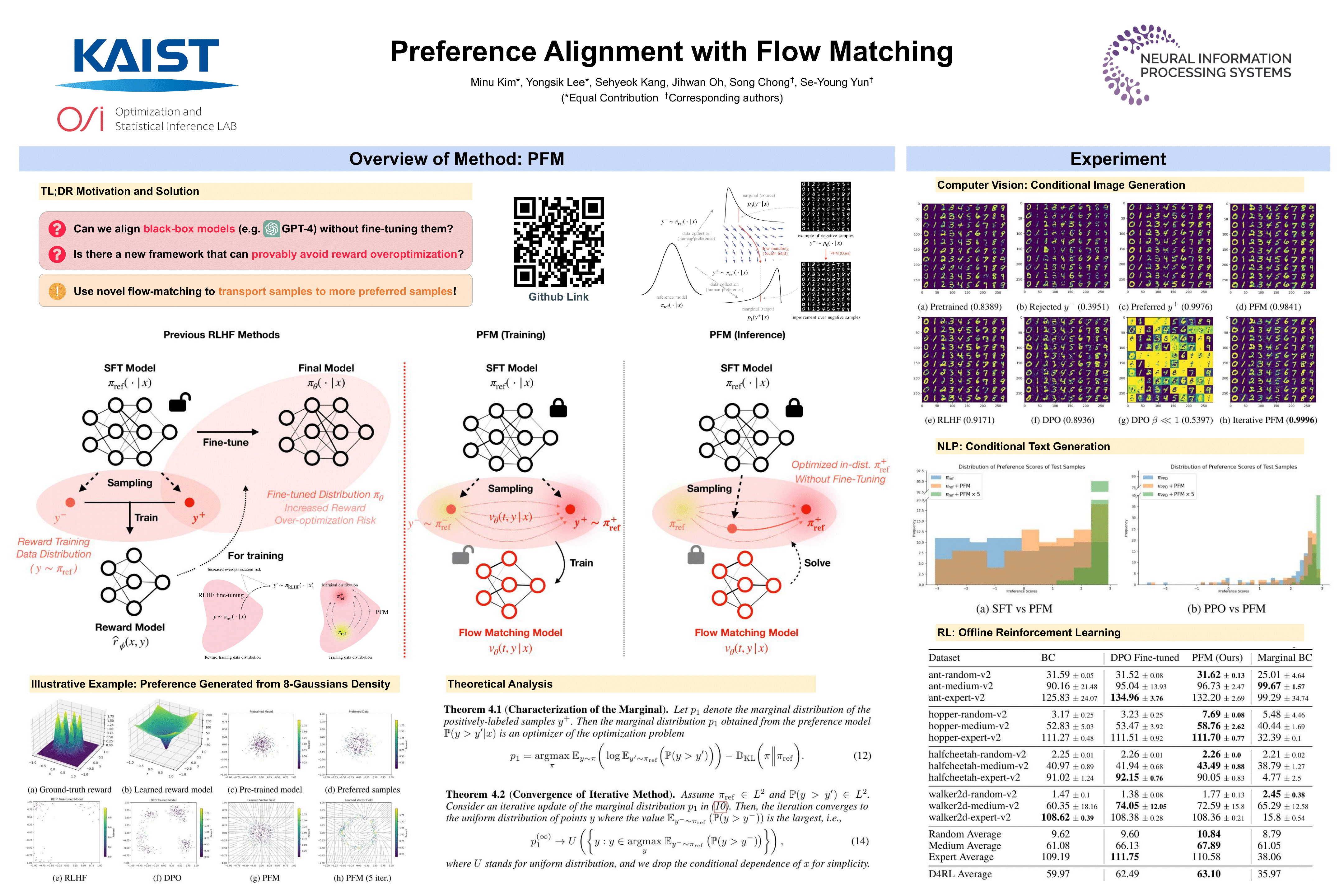
We present Preference Flow Matching (PFM), a new framework for preference alignment that streamlines the integration of preferences into an arbitrary class of pre-trained models. Existing alignment methods require fine-tuning pre-trained models, which presents challenges such as scalability, inefficiency, and the need for model modifications, especially with black-box APIs like GPT-4. In contrast, PFM utilizes flow matching techniques to directly learn from preference data, thereby reducing the dependency on extensive fine-tuning of pre-trained models. By leveraging flow-based models, PFM transforms less preferred data into preferred outcomes, and effectively aligns model outputs with human preferences without relying on explicit or implicit reward function estimation, thus avoiding common issues like overfitting in reward models. We provide theoretical insights that support our method’s alignment with standard preference alignment objectives. Experimental results indicate the practical effectiveness of our method, offering a new direction in aligning a pre-trained model to preference. Our code is available at https://github.com/jadehaus/preference-flow-matching.