Diffusion-DICE: In-Sample Diffusion Guidance for Offline Reinforcement Learning
{kind=link}
Abstract
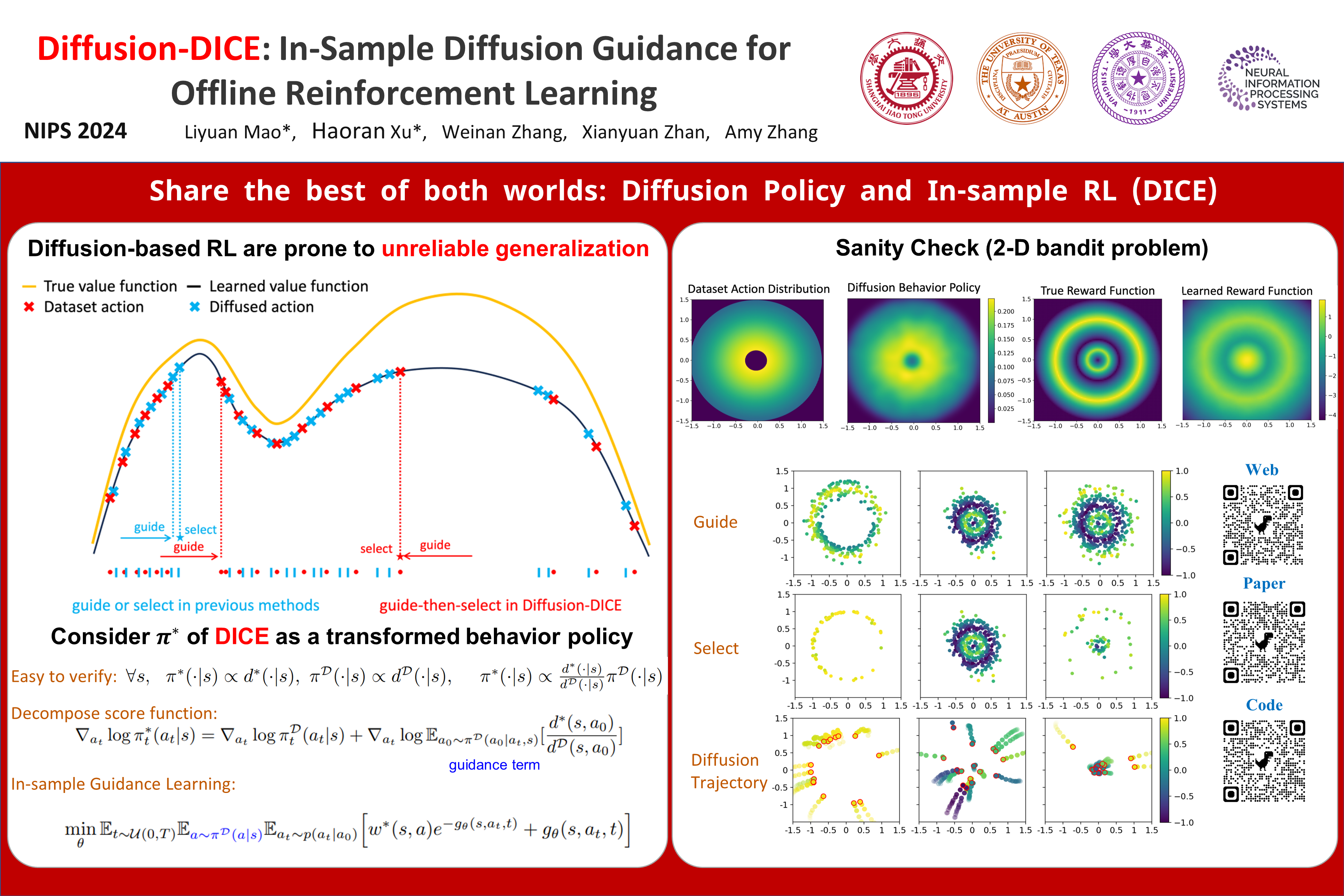
One important property of DIstribution Correction Estimation (DICE) methods is that the solution is the optimal stationary distribution ratio between the optimized and data collection policy. In this work, we show that DICE-based methods can be viewed as a transformation from the behavior distribution to the optimal policy distribution. Based on this, we propose a novel approach, Diffusion-DICE, that directly performs this transformation using diffusion models. We find that the optimal policy's score function can be decomposed into two terms: the behavior policy's score function and the gradient of a guidance term which depends on the optimal distribution ratio. The first term can be obtained from a diffusion model trained on the dataset and we propose an in-sample learning objective to learn the second term. Due to the multi-modality contained in the optimal policy distribution, the transformation in Diffusion-DICE may guide towards those local-optimal modes. We thus generate a few candidate actions and carefully select from them to achieve global-optimum. Different from all other diffusion-based offline RL methods, the \textit{guide-then-select} paradigm in Diffusion-DICE only uses in-sample actions for training and brings minimal error exploitation in the value function. We use a didatic toycase example to show how previous diffusion-based methods fail to generate optimal actions due to leveraging these errors and how Diffusion-DICE successfully avoid that. We then conduct extensive experiments on benchmark datasets to show the strong performance of Diffusion-DICE.