Benign overfitting in leaky ReLU networks with moderate input dimension
Kedar Karhadkar ⋅ Erin George ⋅ Michael Murray ⋅ Guido Montufar ⋅ Deanna Needell
2024 Spotlight Poster
{kind=link}
Abstract
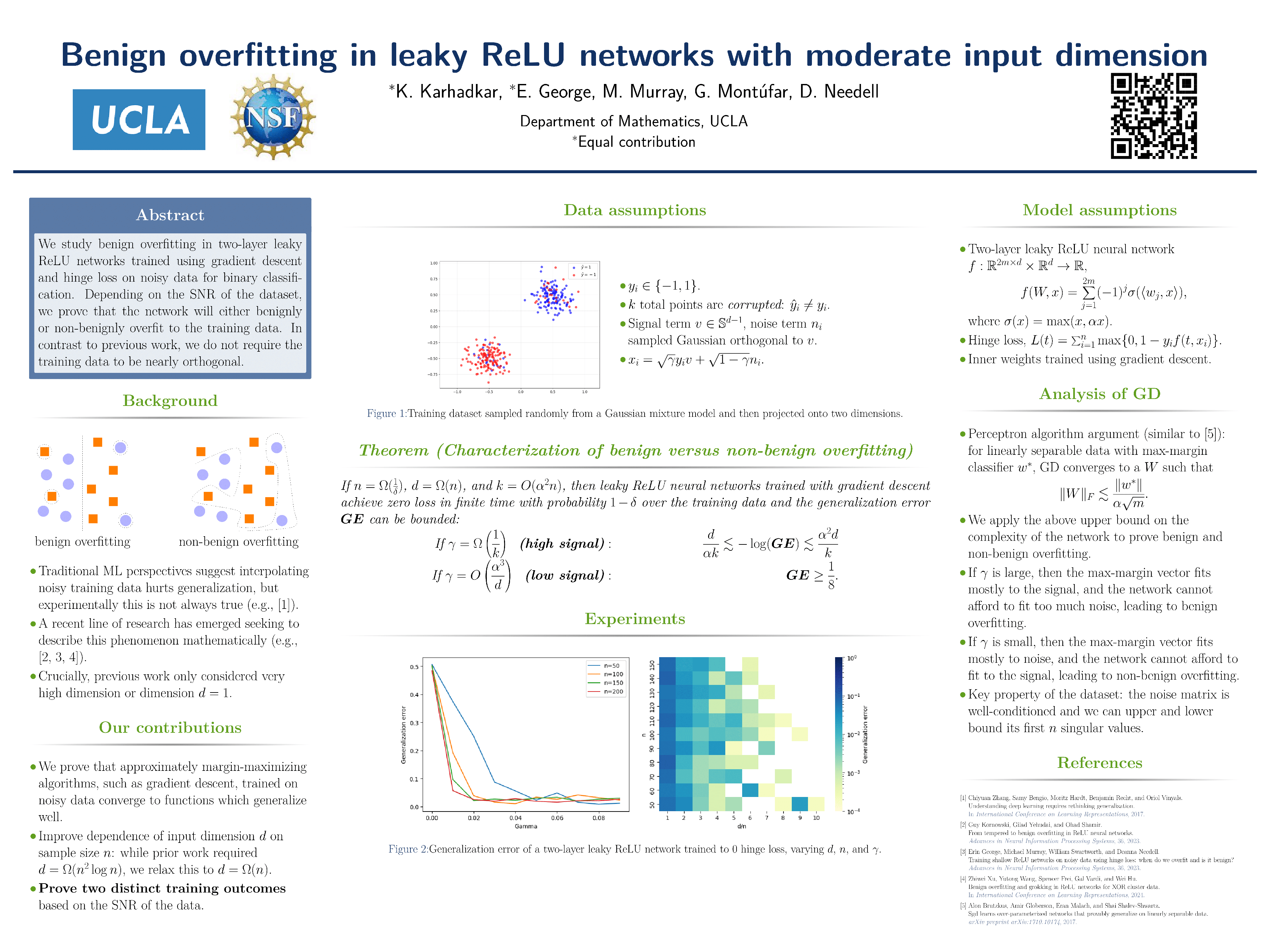
The problem of benign overfitting asks whether it is possible for a model to perfectly fit noisy training data and still generalize well. We study benign overfitting in two-layer leaky ReLU networks trained with the hinge loss on a binary classification task. We consider input data which can be decomposed into the sum of a common signal and a random noise component, which lie on subspaces orthogonal to one another. We characterize conditions on the signal to noise ratio (SNR) of the model parameters giving rise to benign versus non-benign, or harmful, overfitting: in particular, if the SNR is high then benign overfitting occurs, conversely if the SNR is low then harmful overfitting occurs. We attribute both benign and non-benign overfitting to an approximate margin maximization property and show that leaky ReLU networks trained on hinge loss with gradient descent (GD) satisfy this property. In contrast to prior work we do not require the training data to be nearly orthogonal. Notably, for input dimension $d$ and training sample size $n$, while results in prior work require $d = \Omega(n^2 \log n)$, here we require only $d = \Omega(n)$.
Video
Chat is not available.
Successful Page Load