Human-3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion Models
{kind=link}
Abstract
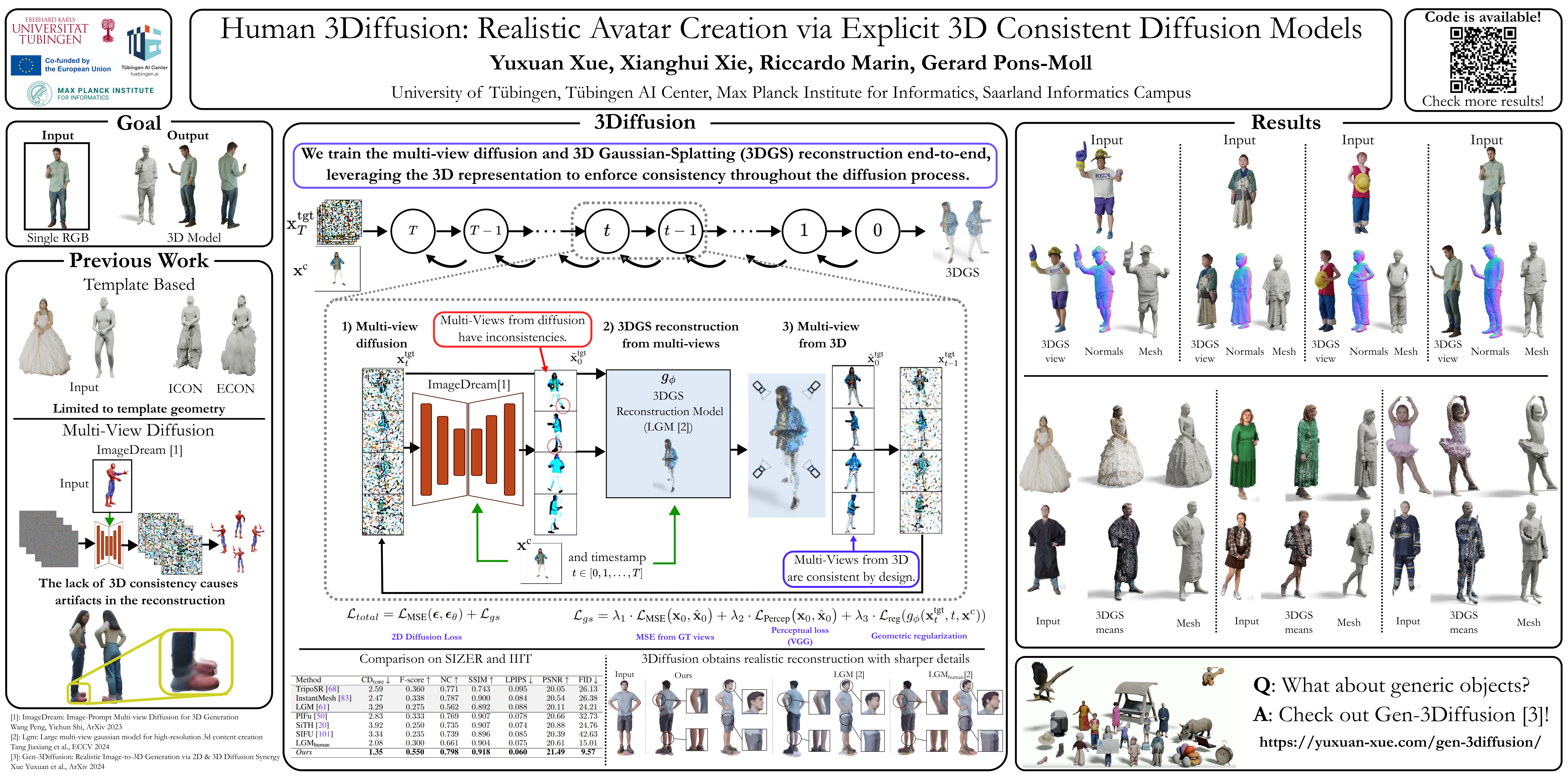
Creating realistic avatars from a single RGB image is an attractive yet challenging problem. To deal with challenging loose clothing or occlusion by interaction objects, we leverage powerful shape prior from 2D diffusion models pretrained on large datasets. Although 2D diffusion models demonstrate strong generalization capability, they cannot provide multi-view shape priors with guaranteed 3D consistency. We propose Human-3Diffusion: Realistic Avatar Creation via Explicit 3D Consistent Diffusion. Our key insight is that 2D multi-view diffusion and 3D reconstruction models provide complementary information for each other. By coupling them in a tight manner, we can fully leverage the potential of both models. We introduce a novel image-conditioned generative 3D Gaussian Splats reconstruction model that leverages the prior from 2D multi-view diffusion models, and provides an explicit 3D representation, which further guides the 2D reverse sampling processto have better 3D consistency. Experiments show that our proposed framework outperforms state-of-the-art methods and enables the creation of realistic avatars from a single RGB image, achieving high-fidelity in both geometry and appearance. Extensive ablations also validate the efficacy of our design, (1) multi-view 2D priors conditioning in generative 3D reconstruction and (2) consistency refinement of sampling trajectory via the explicit 3D representation. Our code and models are released at https://yuxuan-xue.com/human-3diffusion/.