IMAGPose: A Unified Conditional Framework for Pose-Guided Person Generation
{kind=link}
Abstract
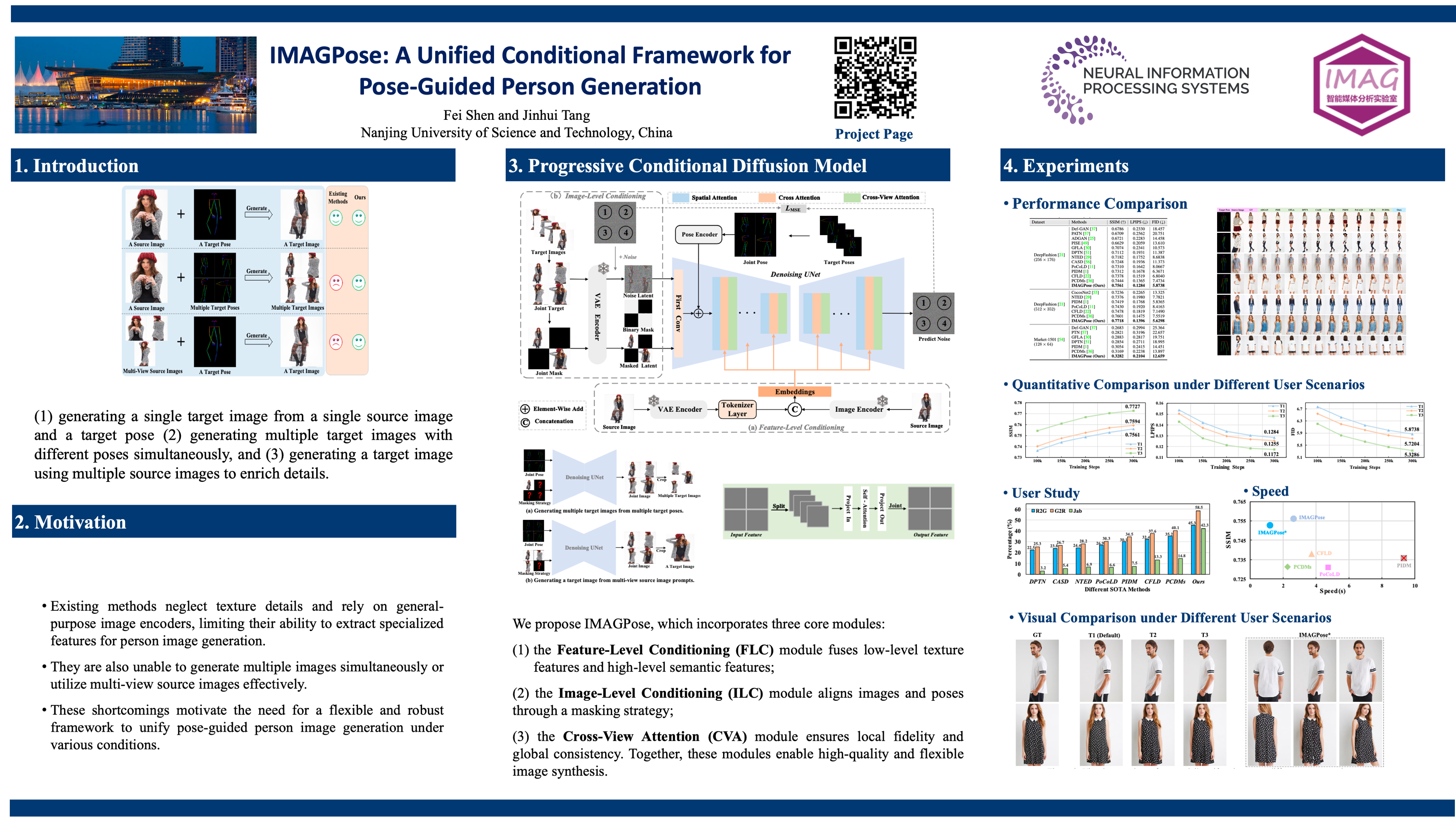
Diffusion models represent a promising avenue for image generation, having demonstrated competitive performance in pose-guided person image generation. However, existing methods are limited to generating target images from a source image and a target pose, overlooking two critical user scenarios: generating multiple target images with different poses simultaneously and generating target images from multi-view source images.To overcome these limitations, we propose IMAGPose, a unified conditional framework for pose-guided image generation, which incorporates three pivotal modules: a feature-level conditioning (FLC) module, an image-level conditioning (ILC) module, and a cross-view attention (CVA) module. Firstly, the FLC module combines the low-level texture feature from the VAE encoder with the high-level semantic feature from the image encoder, addressing the issue of missing detail information due to the absence of a dedicated person image feature extractor. Then, the ILC module achieves an alignment of images and poses to adapt to flexible and diverse user scenarios by injecting a variable number of source image conditions and introducing a masking strategy.Finally, the CVA module introduces decomposing global and local cross-attention, ensuring local fidelity and global consistency of the person image when multiple source image prompts. The three modules of IMAGPose work together to unify the task of person image generation under various user scenarios.Extensive experiment results demonstrate the consistency and photorealism of our proposed IMAGPose under challenging user scenarios. The code and model will be available at https://github.com/muzishen/IMAGPose.