Fine-grained Image-to-LiDAR Contrastive Distillation with Visual Foundation Models
{kind=link}
Abstract
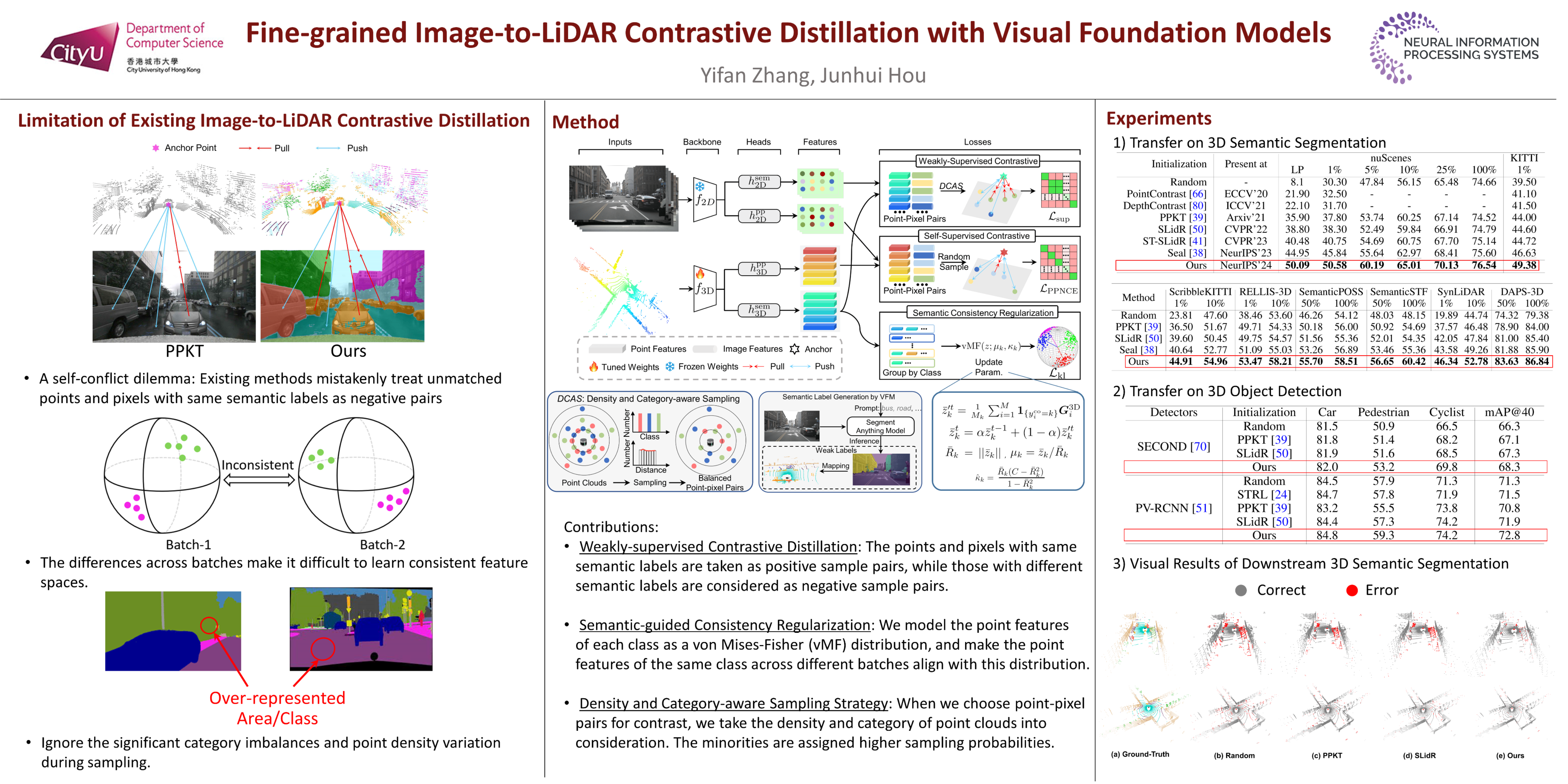
Contrastive image-to-LiDAR knowledge transfer, commonly used for learning 3D representations with synchronized images and point clouds, often faces a self-conflict dilemma. This issue arises as contrastive losses unintentionally dissociate features of unmatched points and pixels that share semantic labels, compromising the integrity of learned representations. To overcome this, we harness Visual Foundation Models (VFMs), which have revolutionized the acquisition of pixel-level semantics, to enhance 3D representation learning. Specifically, we utilize off-the-shelf VFMs to generate semantic labels for weakly-supervised pixel-to-point contrastive distillation. Additionally, we employ von Mises-Fisher distributions to structure the feature space, ensuring semantic embeddings within the same class remain consistent across varying inputs. Furthermore, we adapt sampling probabilities of points to address imbalances in spatial distribution and category frequency, promoting comprehensive and balanced learning. Extensive experiments demonstrate that our approach mitigates the challenges posed by traditional methods and consistently surpasses existing image-to-LiDAR contrastive distillation methods in downstream tasks. We have included the code in supplementary materials.