BECAUSE: Bilinear Causal Representation for Generalizable Offline Model-based Reinforcement Learning
{kind=link}
Abstract
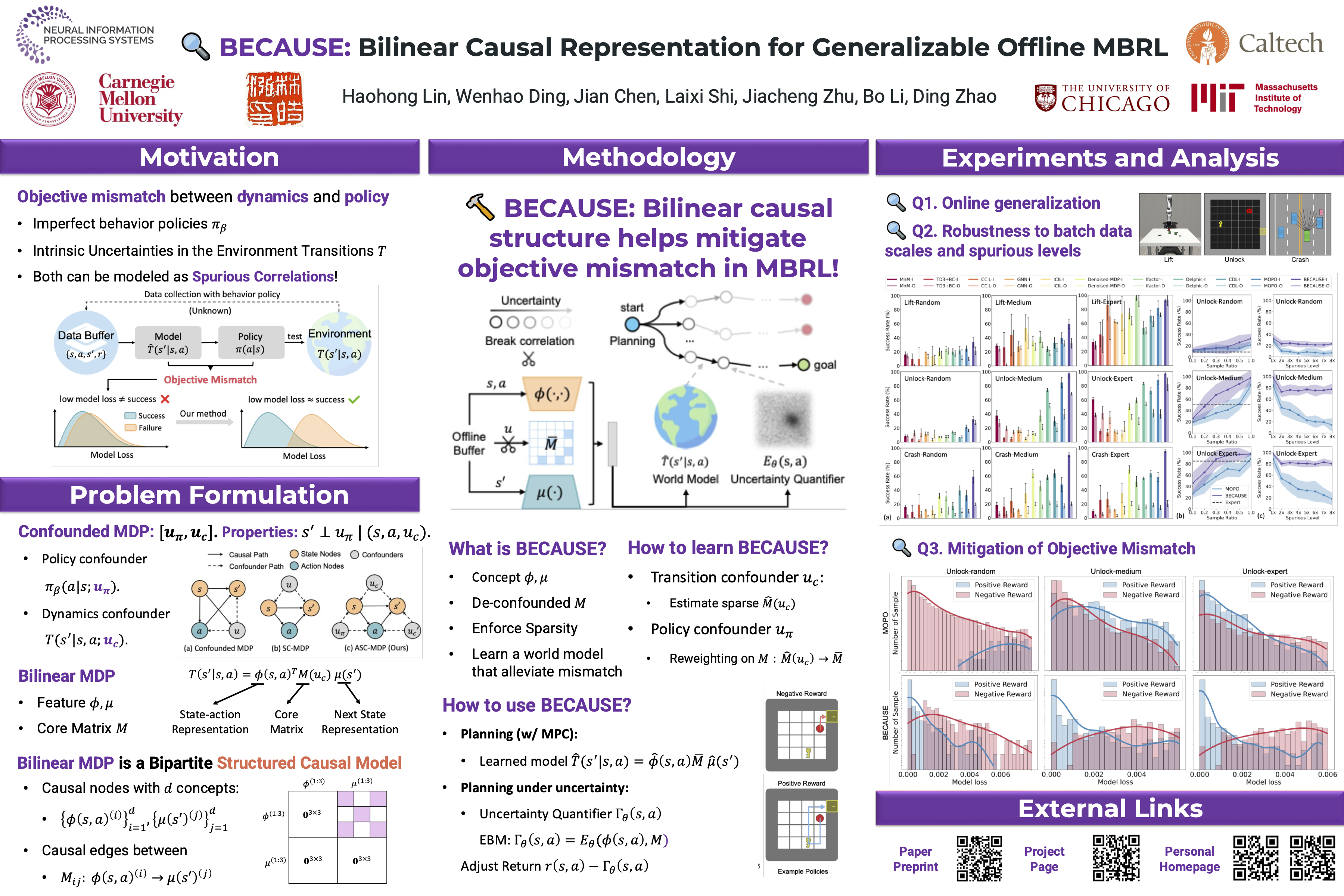
Offline model-based reinforcement learning (MBRL) enhances data efficiency by utilizing pre-collected datasets to learn models and policies, especially in scenarios where exploration is costly or infeasible. Nevertheless, its performance often suffers from the objective mismatch between model and policy learning, resulting in inferior performance despite accurate model predictions. This paper first identifies the primary source of this mismatch comes from the underlying confounders present in offline data for MBRL. Subsequently, we introduce BilinEar CAUSal rEpresentation (BECAUSE), an algorithm to capture causal representation for both states and actions to reduce the influence of the distribution shift, thus mitigating the objective mismatch problem. Comprehensive evaluations on 18 tasks that vary in data quality and environment context demonstrate the superior performance of BECAUSE over existing offline RL algorithms. We show the generalizability and robustness of BECAUSE under fewer samples or larger numbers of confounders. Additionally, we offer theoretical analysis of BECAUSE to prove its error bound and sample efficiency when integrating causal representation into offline MBRL. See more details in our project page: https://sites.google.com/view/be-cause.