WATT: Weight Average Test Time Adaptation of CLIP
{kind=link}
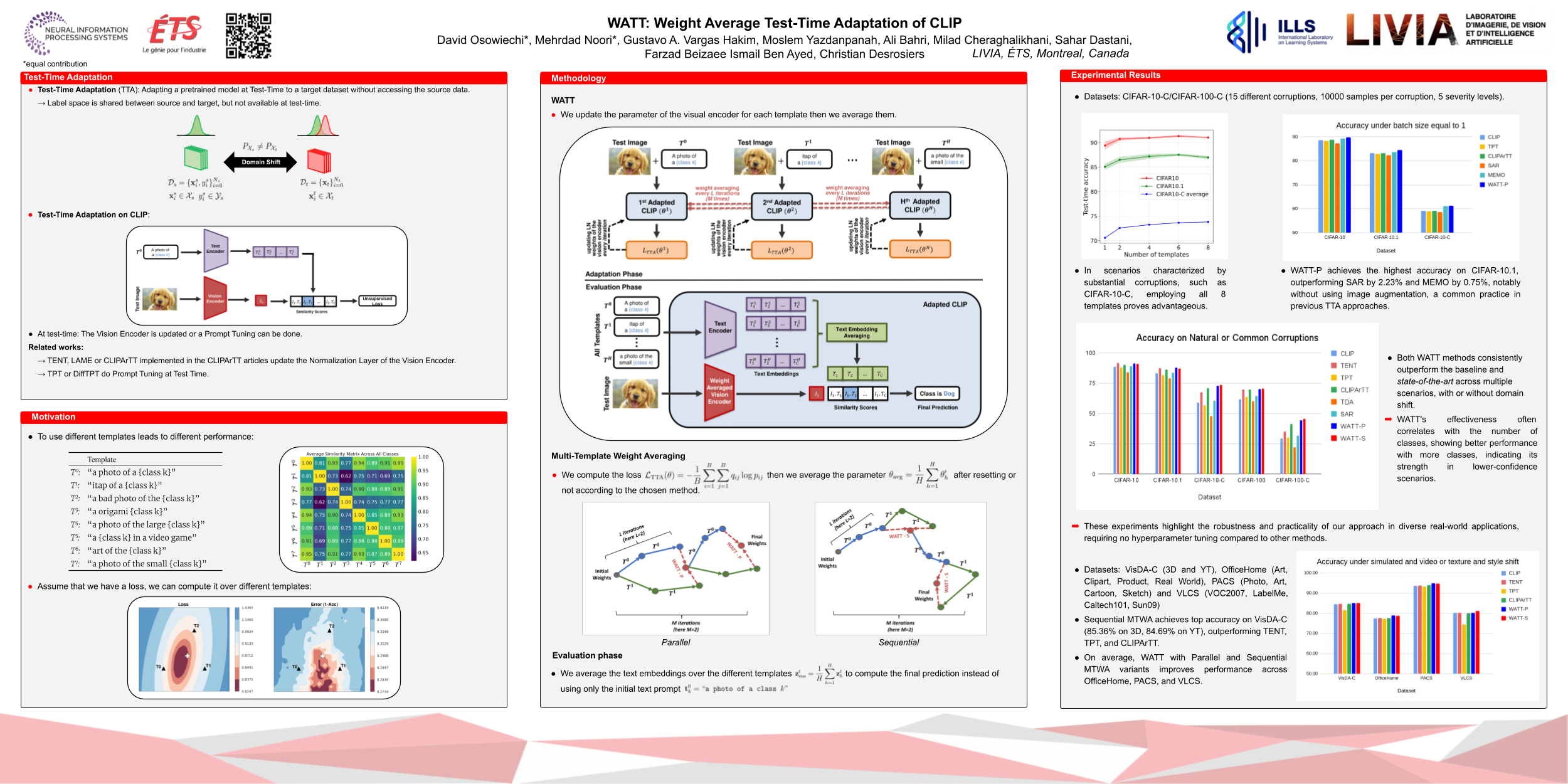
Abstract
Vision-Language Models (VLMs) such as CLIP have yielded unprecedented performances for zero-shot image classification, yet their generalization capability may still be seriously challenged when confronted to domain shifts. In response, we present Weight Average Test-Time Adaptation (WATT) of CLIP, a new approach facilitating full test-time adaptation (TTA) of this VLM. Our method employs a diverse set of templates for text prompts, augmenting the existing framework of CLIP. Predictions are utilized as pseudo labels for model updates, followed by weight averaging to consolidate the learned information globally. Furthermore, we introduce a text ensemble strategy, enhancing the overall test performance by aggregating diverse textual cues.Our findings underscore the effectiveness of WATT across diverse datasets, including CIFAR-10-C, CIFAR-10.1, CIFAR-100-C, VisDA-C, and several other challenging datasets, effectively covering a wide range of domain shifts. Notably, these enhancements are achieved without the need for additional model transformations or trainable modules. Moreover, compared to other TTA methods, our approach can operate effectively with just a single image. The code is available at: https://github.com/Mehrdad-Noori/WATT.