Privacy without Noisy Gradients: Slicing Mechanism for Generative Model Training
Kristjan Greenewald ⋅ Yuancheng Yu ⋅ Hao Wang ⋅ Kai Xu
2024 Poster
{kind=link}
Abstract
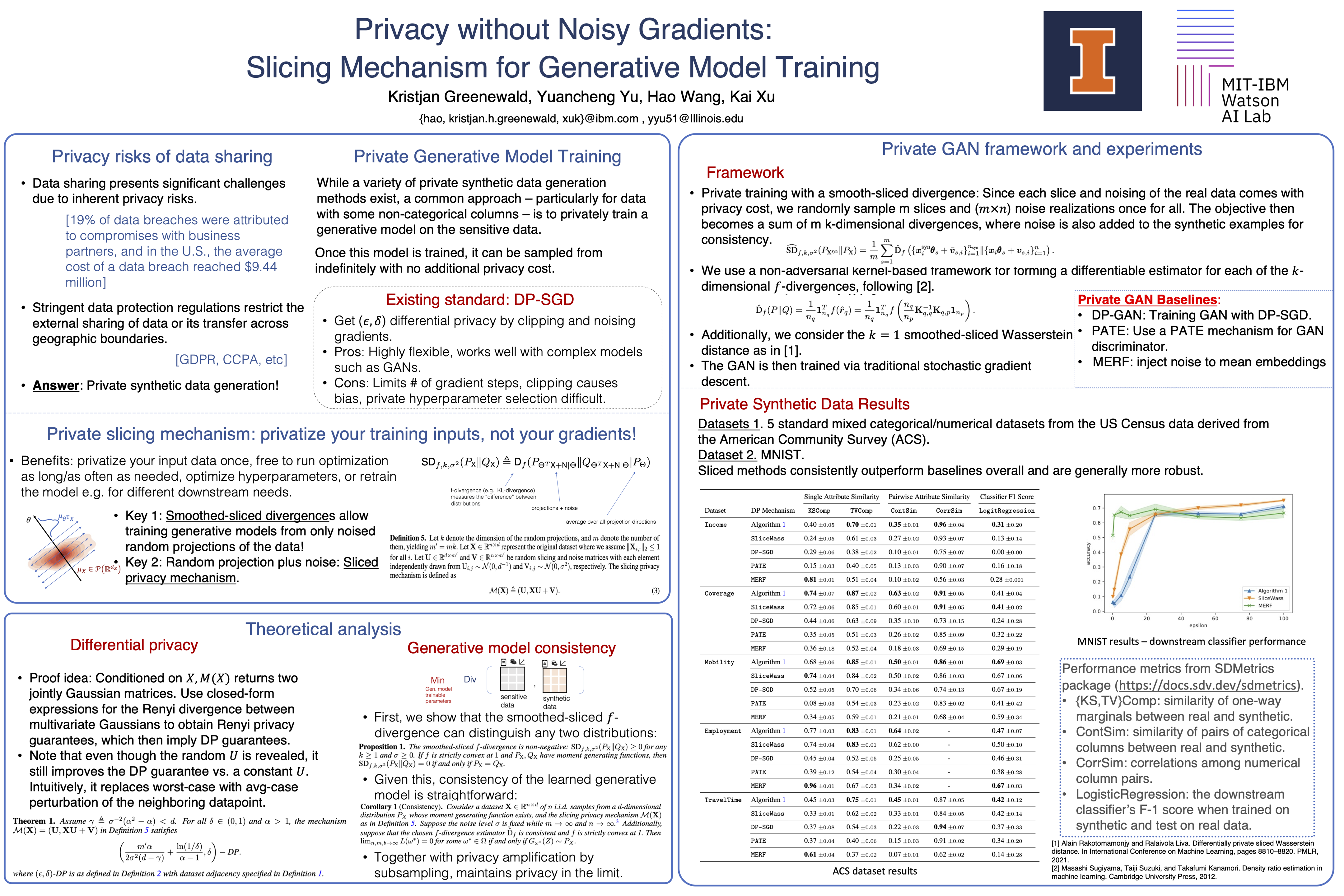
Training generative models with differential privacy (DP) typically involves injecting noise into gradient updates or adapting the discriminator's training procedure. As a result, such approaches often struggle with hyper-parameter tuning and convergence. We consider the \emph{slicing privacy mechanism} that injects noise into random low-dimensional projections of the private data, and provide strong privacy guarantees for it. These noisy projections are used for training generative models.To enable optimizing generative models using this DP approach, we introduce the \emph{smoothed-sliced $f$-divergence} and show it enjoys statistical consistency. Moreover, we present a kernel-based estimator for this divergence, circumventing the need for adversarial training. Extensive numerical experiments demonstrate that our approach can generate synthetic data of higher quality compared with baselines. Beyond performance improvement, our method, by sidestepping the need for noisy gradients, offers data scientists the flexibility to adjust generator architecture and hyper-parameters, run the optimization over any number of epochs, and even restart the optimization process---all without incurring additional privacy costs.
Video
Chat is not available.
Successful Page Load