Causal Deciphering and Inpainting in Spatio-Temporal Dynamics via Diffusion Model
{kind=link}
Abstract
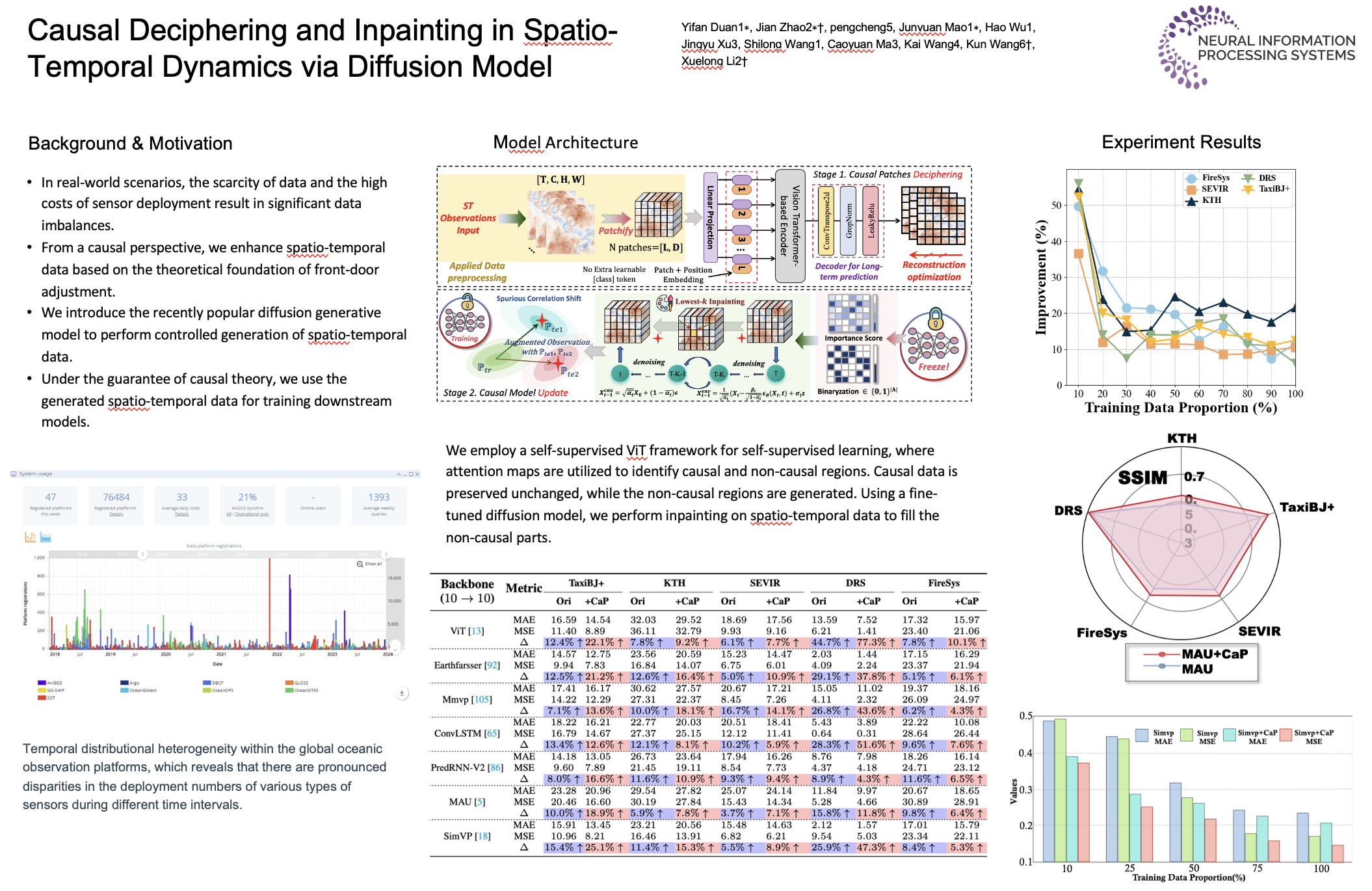
Spatio-temporal (ST) prediction has garnered a De facto attention in earth sciences, such as meteorological prediction, human mobility perception. However, the scarcity of data coupled with the high expenses involved in sensor deployment results in notable data imbalances. Furthermore, models that are excessively customized and devoid of causal connections further undermine the generalizability and interpretability. To this end, we establish a causal framework for ST predictions, termed CaPaint, which targets to identify causal regions in data and endow model with causal reasoning ability in a two-stage process. Going beyond this process, we utilize the back-door adjustment to specifically address the sub-regions identified as non-causal in the upstream phase. Specifically, we employ a novel image inpainting technique. By using a fine-tuned unconditional Diffusion Probabilistic Model (DDPM) as the generative prior, we in-fill the masks defined as environmental parts, offering the possibility of reliable extrapolation for potential data distributions. CaPaint overcomes the high complexity dilemma of optimal ST causal discovery models by reducing the data generation complexity from exponential to quasi-linear levels. Extensive experiments conducted on five real-world ST benchmarks demonstrate that integrating the CaPaint concept allows models to achieve improvements ranging from 4.3% to 77.3%. Moreover, compared to traditional mainstream ST augmenters, CaPaint underscores the potential of diffusion models in ST enhancement, offering a novel paradigm for this field. Our project is available at https://anonymous.4open.science/r/12345-DFCC.