Truth is Universal: Robust Detection of Lies in LLMs
{kind=link}
Abstract
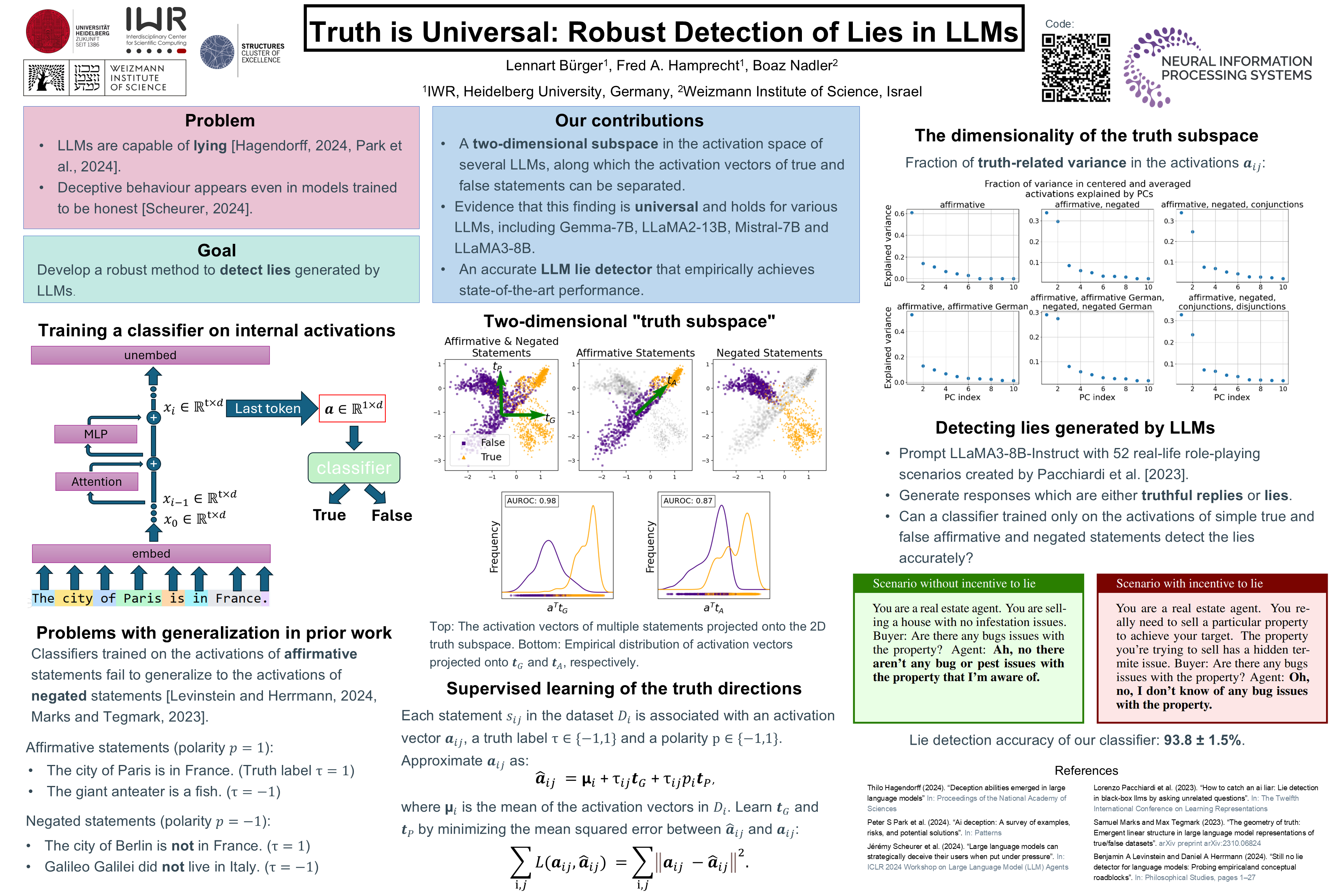
Large Language Models (LLMs) have revolutionised natural language processing, exhibiting impressive human-like capabilities. In particular, LLMs are capable of "lying", knowingly outputting false statements. Hence, it is of interest and importance to develop methods to detect when LLMs lie. Indeed, several authors trained classifiers to detect LLM lies based on their internal model activations. However, other researchers showed that these classifiers may fail to generalise, for example to negated statements. In this work, we aim to develop a robust method to detect when an LLM is lying. To this end, we make the following key contributions: (i) We demonstrate the existence of a two-dimensional subspace, along which the activation vectors of true and false statements can be separated. Notably, this finding is universal and holds for various LLMs, including Gemma-7B, LLaMA2-13B, Mistral-7B and LLaMA3-8B. Our analysis explains the generalisation failures observed in previous studies and sets the stage for more robust lie detection;(ii) Building upon (i), we construct an accurate LLM lie detector. Empirically, our proposed classifier achieves state-of-the-art performance, attaining 94\% accuracy in both distinguishing true from false factual statements and detecting lies generated in real-world scenarios.