On the Effects of Data Scale on UI Control Agents
{kind=link}
Abstract
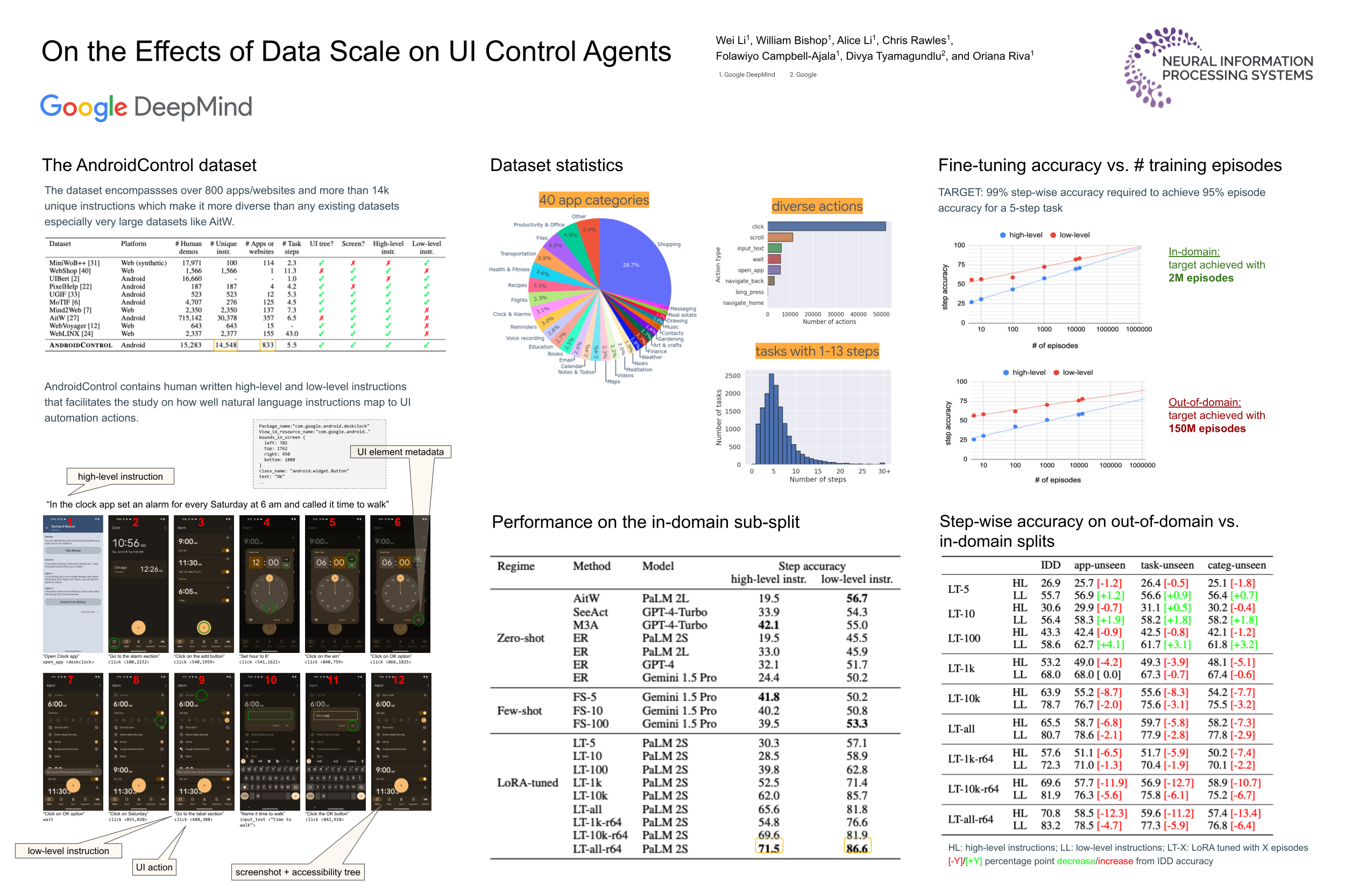
Autonomous agents that control user interfaces to accomplish human tasks are emerging. Leveraging LLMs to power such agents has been of special interest, but unless fine-tuned on human-collected task demonstrations, performance is still relatively low. In this work we study whether fine-tuning alone is a viable approach for building real-world UI control agents. To this end we collect and release a new dataset, AndroidControl, consisting of 15,283 demonstrations of everyday tasks with Android apps. Compared to existing datasets, each AndroidControl task instance includes both high and low-level human-generated instructions, allowing us to explore the level of task complexity an agent can handle. Moreover, AndroidControl is the most diverse computer control dataset to date, including 14,548 unique tasks over 833 Android apps, thus allowing us to conduct in-depth analysis of the model performance in and out of the domain of the training data. Using the dataset, we find that when tested in domain fine-tuned models outperform zero and few-shot baselines and scale in such a way that robust performance might feasibly be obtained simply by collecting more data. Out of domain, performance scales significantly more slowly and suggests that in particular for high-level tasks, fine-tuning on more data alone may be insufficient for achieving robust out-of-domain performance.