Beyond Prompts: Dynamic Conversational Benchmarking of Large Language Models
David Castillo-Bolado ⋅ Joseph Davidson ⋅ Finlay Gray ⋅ Marek Rosa
2024 Poster
{kind=link}
Abstract
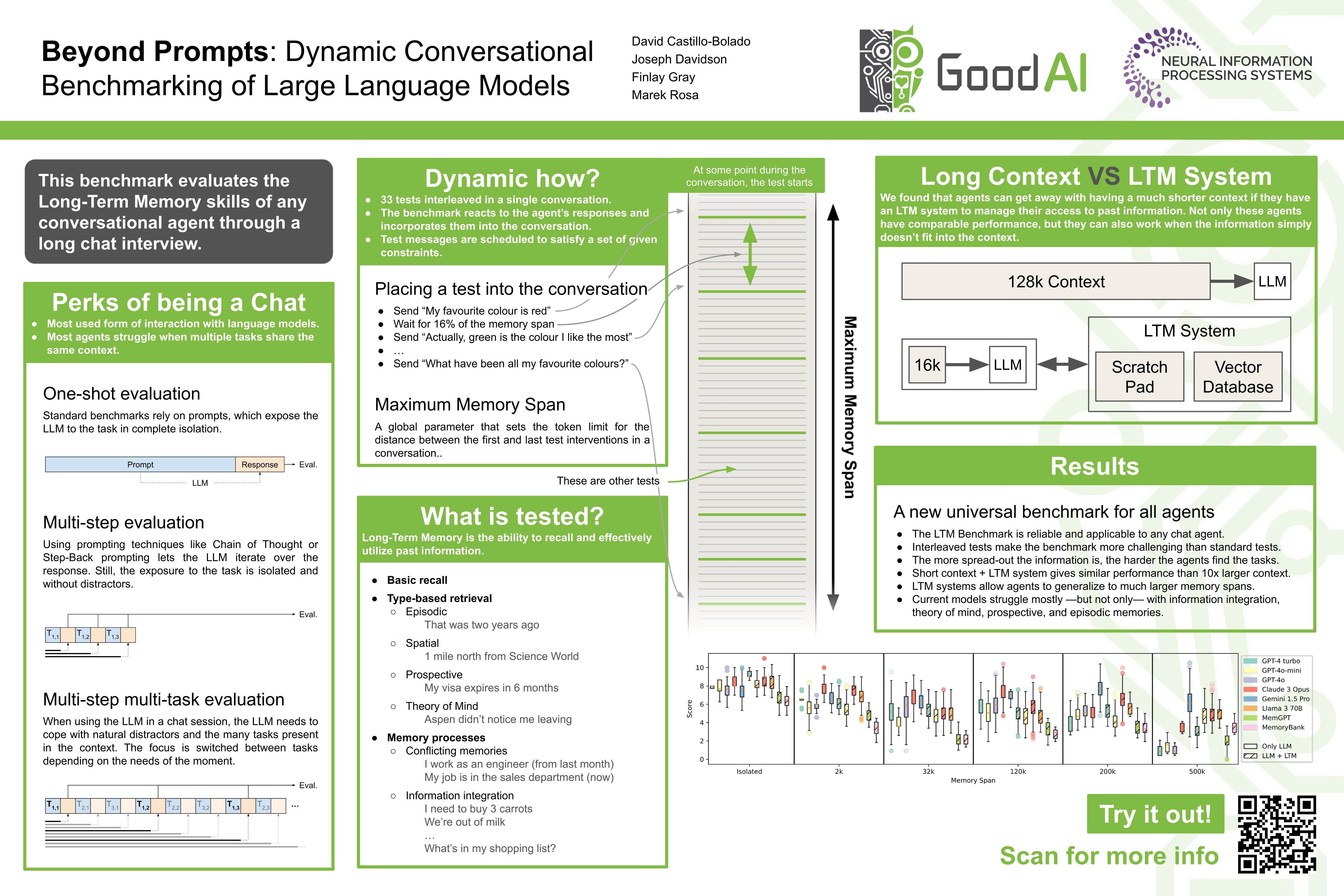
We introduce a dynamic benchmarking system for conversational agents that evaluates their performance through a single, simulated, and lengthy user$\leftrightarrow$agent interaction. The interaction is a conversation between the user and agent, where multiple tasks are introduced and then undertaken concurrently. We context switch regularly to interleave the tasks, which constructs a realistic testing scenario in which we assess the Long-Term Memory, Continual Learning, and Information Integration capabilities of the agents. Results from both proprietary and open-source Large-Language Models show that LLMs in general perform well on single-task interactions, but they struggle on the same tasks when they are interleaved. Notably, short-context LLMs supplemented with an LTM system perform as well as or better than those with larger contexts. Our benchmark suggests that there are other challenges for LLMs responding to more natural interactions that contemporary benchmarks have heretofore not been able to capture.
Video
Chat is not available.
Successful Page Load