WikiDBs: A Large-Scale Corpus Of Relational Databases From Wikidata
{kind=link}
Abstract
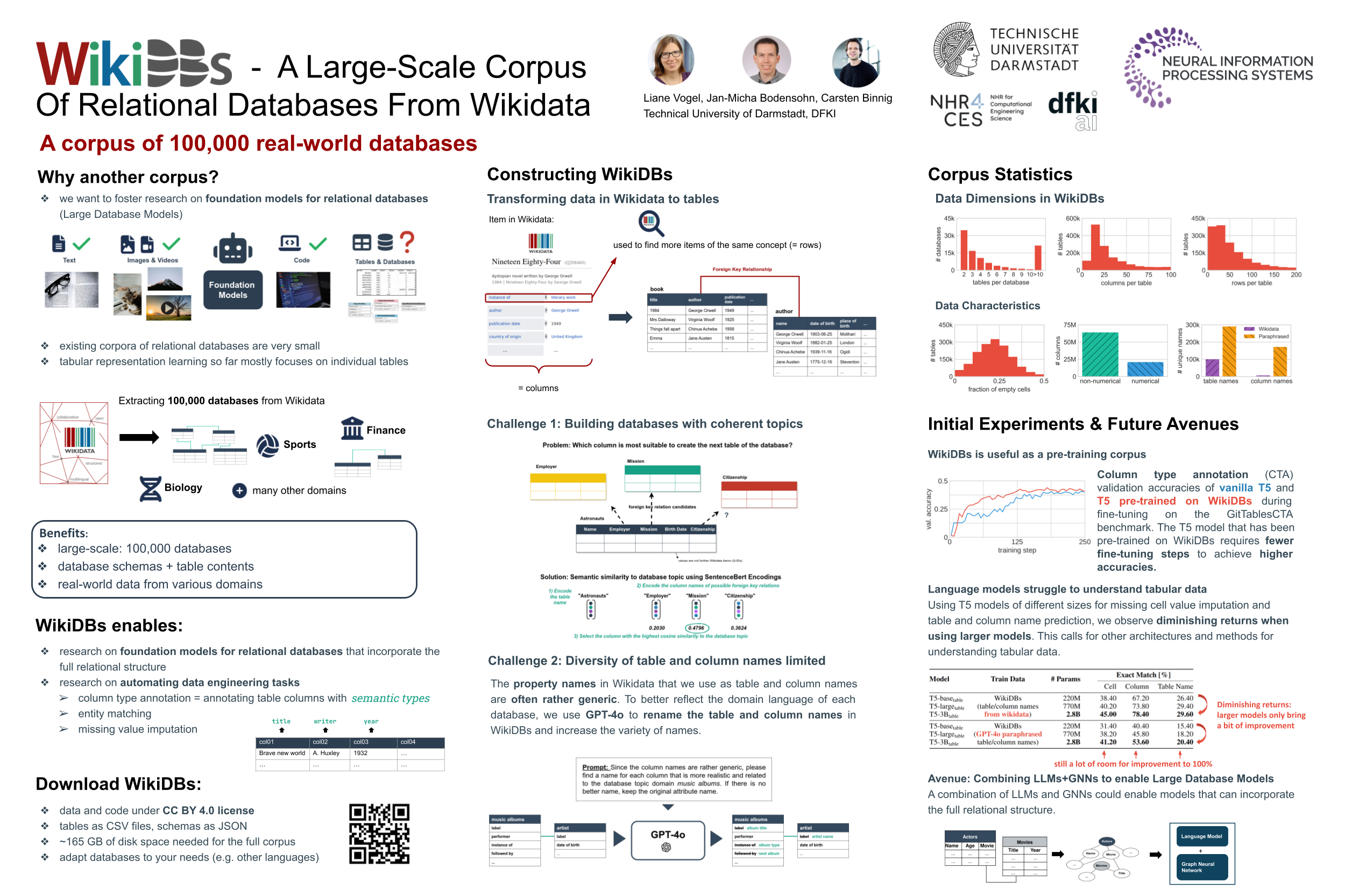
Deep learning on tabular data, and particularly tabular representation learning, has recently gained growing interest. However, representation learning for relational databases with multiple tables is still an underexplored area, which may be attributed to the lack of openly available resources. To support the development of foundation models for tabular data and relational databases, we introduce WikiDBs, a novel open-source corpus of 100,000 relational databases. Each database consists of multiple tables connected by foreign keys. The corpus is based on Wikidata and aims to follow certain characteristics of real-world databases. In this paper, we describe the dataset and our method for creating it. By making our code publicly available, we enable others to create tailored versions of the dataset, for example, by creating databases in different languages. Finally, we conduct a set of initial experiments to showcase how WikiDBs can be used to train for data engineering tasks, such as missing value imputation and column type annotation.