Text-space Graph Foundation Models: Comprehensive Benchmarks and New Insights
{kind=link}
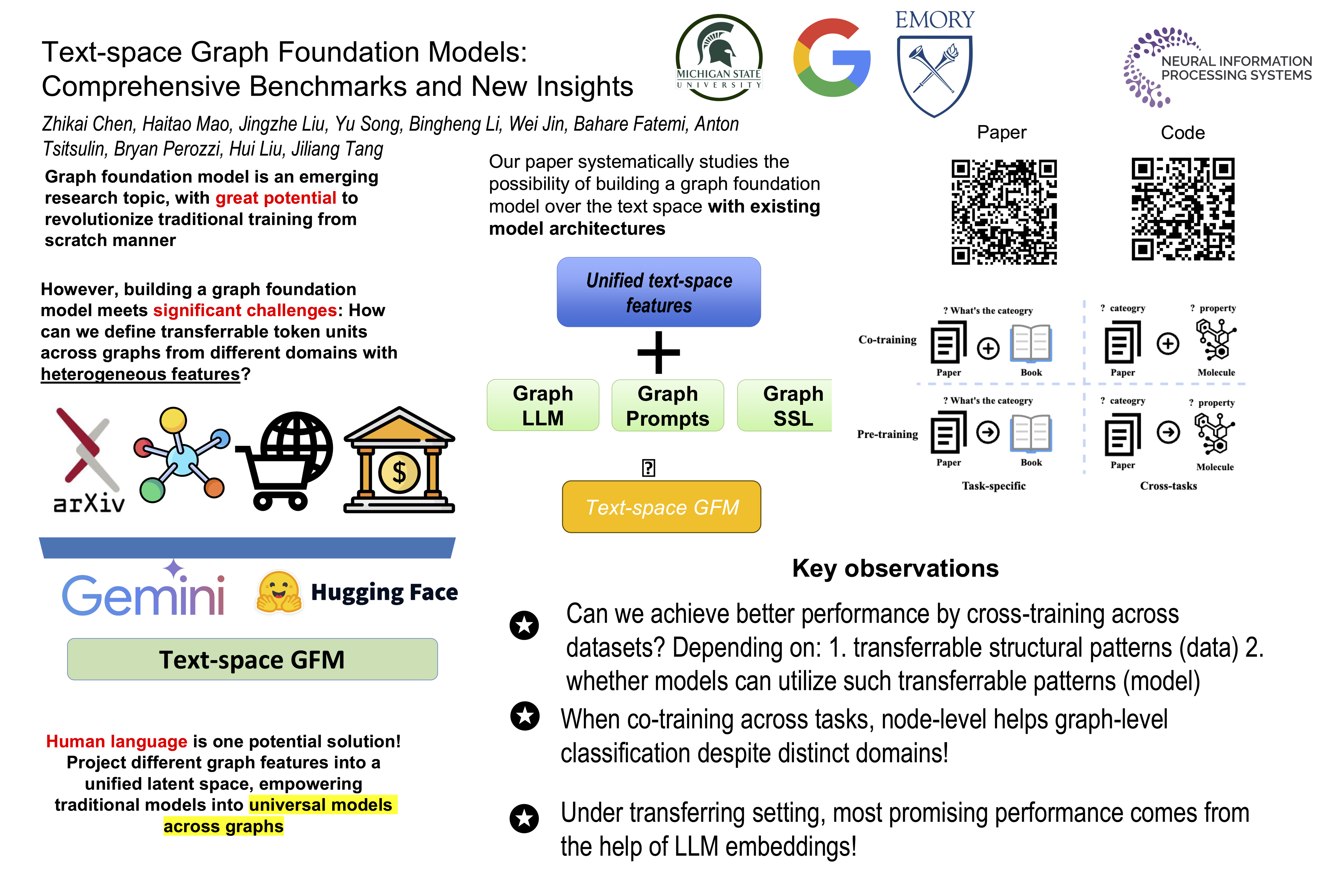
Abstract
Given the ubiquity of graph data and its applications in diverse domains, building a Graph Foundation Model (GFM) that can work well across different graphs and tasks with a unified backbone has recently garnered significant interests. A major obstacle to achieving this goal stems from the fact that graphs from different domains often exhibit diverse node features. Inspired by multi-modal models that align different modalities with natural language, the text has recently been adopted to provide a unified feature space for diverse graphs. Despite the great potential of these text-space GFMs, current research in this field is hampered by two problems. First, the absence of a comprehensive benchmark with unified problem settings hinders a clear understanding of the comparative effectiveness and practical value of different text-space GFMs. Second, there is a lack of sufficient datasets to thoroughly explore the methods' full potential and verify their effectiveness across diverse settings. To address these issues, we conduct a comprehensive benchmark providing novel text-space datasets and comprehensive evaluation under unified problem settings. Empirical results provide new insights and inspire future research directions. Our code and data are publicly available from https://github.com/CurryTang/TSGFM.