3DCoMPaT200: Language Grounded Large-Scale 3D Vision Dataset for Compositional Recognition
{kind=link}
Abstract
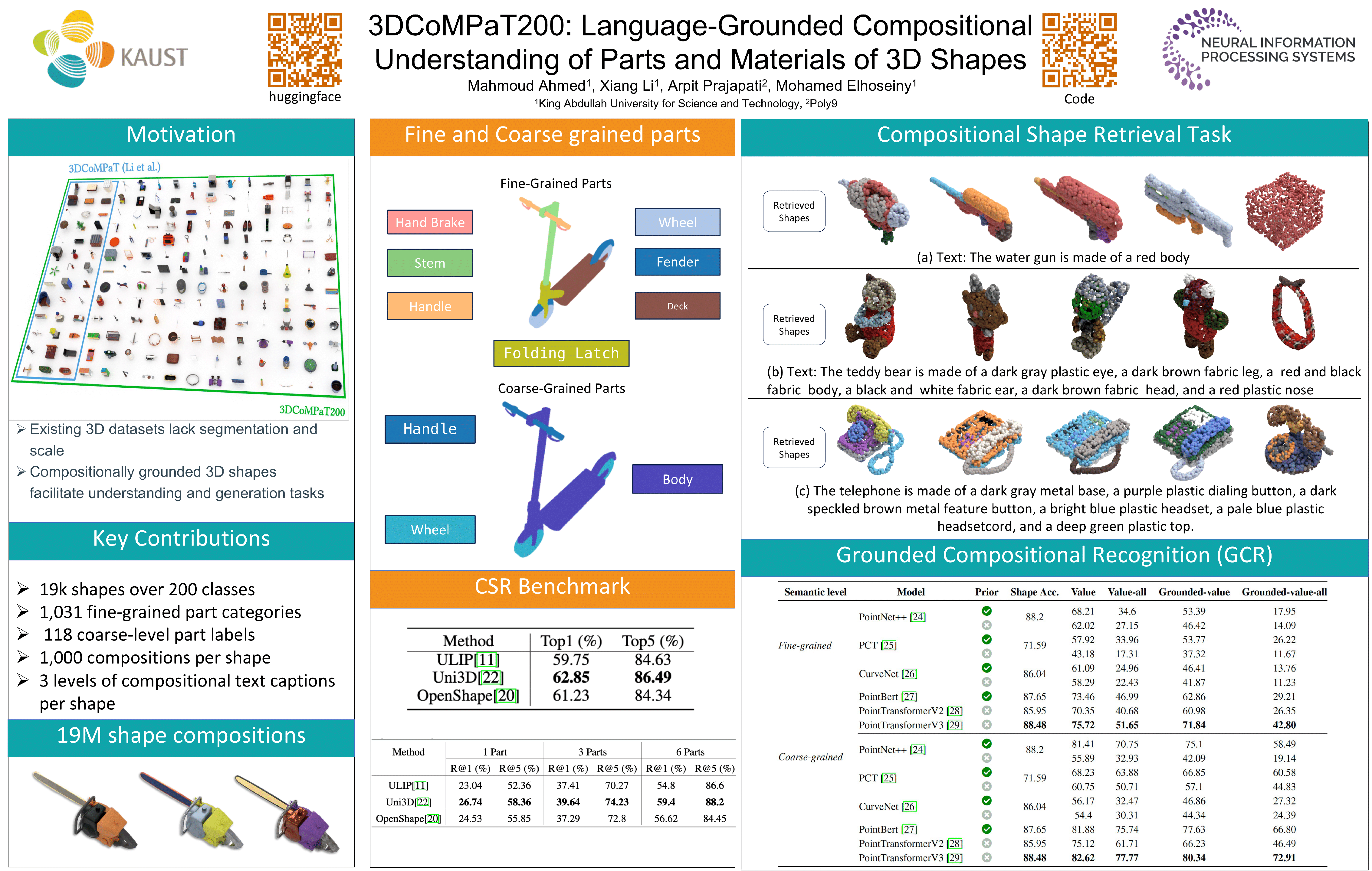
Understanding objects in 3D at the part level is essential for humans and robots to navigate and interact with the environment. Current datasets for part-level 3D object understanding encompass a limited range of categories. For instance, the ShapeNet-Part and PartNet datasets only include 16, and 24 object categories respectively. The 3DCoMPaT dataset, specifically designed for compositional understanding of parts and materials, contains only 42 object categories. To foster richer and fine-grained part-level 3D understanding, we introduce 3DCoMPaT200, a large-scale dataset tailored for compositional understanding of object parts and materials, with 200 object categories with approximately 5 times larger object vocabulary compared to 3DCoMPaT and almost 4 times larger part categories. Concretely, 3DCoMPaT200 significantly expands upon 3DCoMPaT, featuring 1,031 fine-grained part categories and 293 distinct material classes for compositional application to 3D object parts. Additionally, to address the complexities of compositional 3D modeling, we propose a novel task of Compositional Part Shape Retrieval using ULIP to provide a strong 3D foundational model for 3D Compositional Understanding. This method evaluates the model shape retrieval performance given one, three, or six parts described in text format. These results show that the model's performance improves with an increasing number of style compositions, highlighting the critical role of the compositional dataset. Such results underscore the dataset's effectiveness in enhancing models' capability to understand complex 3D shapes from a compositional perspective. Code and Data can be found here: https://github.com/3DCoMPaT200/3DCoMPaT200/