Benchmarking LLMs via Uncertainty Quantification
{kind=link}
Abstract
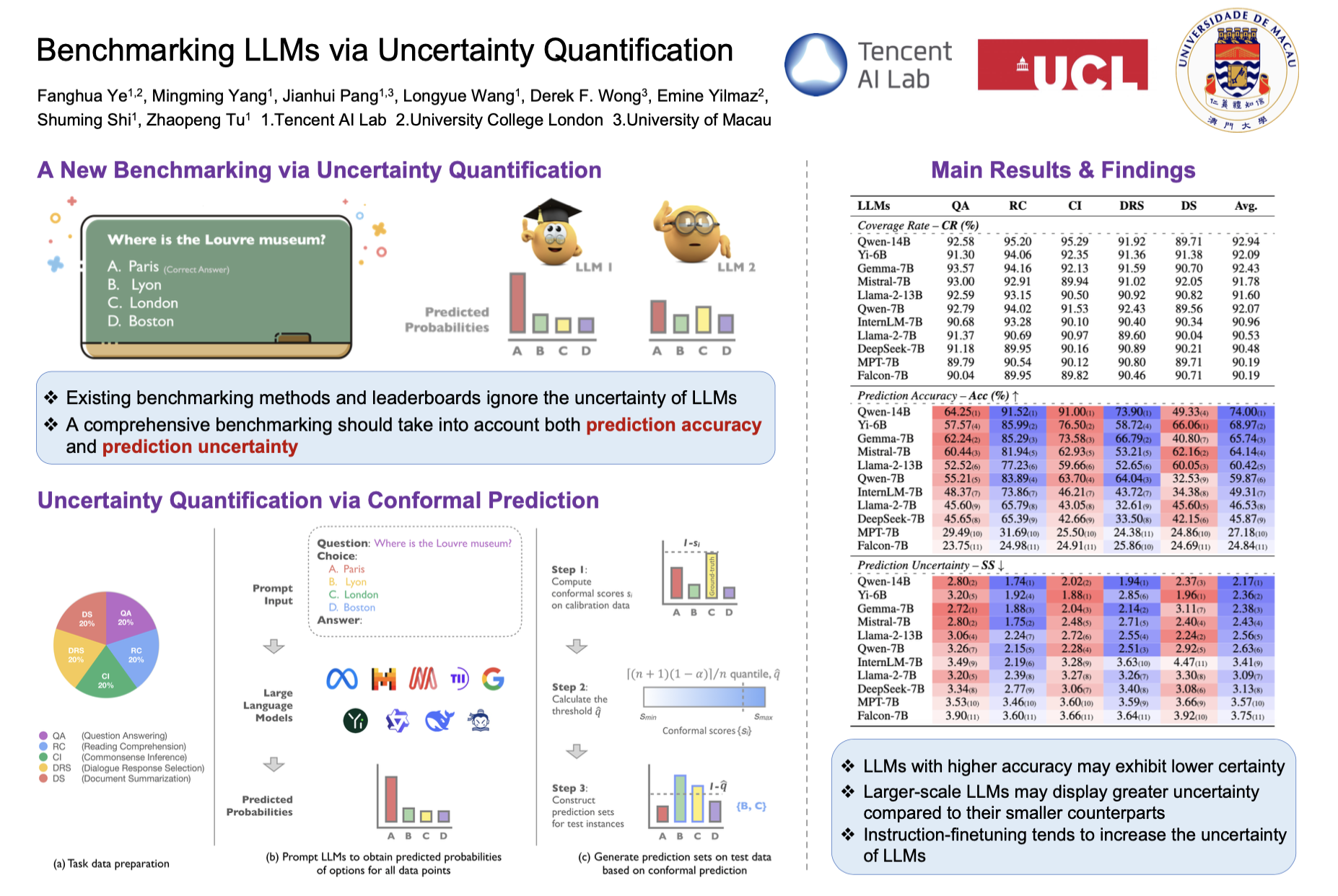
The proliferation of open-source Large Language Models (LLMs) from various institutions has highlighted the urgent need for comprehensive evaluation methods. However, current evaluation platforms, such as the widely recognized HuggingFace open LLM leaderboard, neglect a crucial aspect -- uncertainty, which is vital for thoroughly assessing LLMs. To bridge this gap, we introduce a new benchmarking approach for LLMs that integrates uncertainty quantification. Our examination involves nine LLMs (LLM series) spanning five representative natural language processing tasks. Our findings reveal that: I) LLMs with higher accuracy may exhibit lower certainty; II) Larger-scale LLMs may display greater uncertainty compared to their smaller counterparts; and III) Instruction-finetuning tends to increase the uncertainty of LLMs. These results underscore the significance of incorporating uncertainty in the evaluation of LLMs. Our implementation is available at https://github.com/smartyfh/LLM-Uncertainty-Bench.