Navigating the Maze of Explainable AI: A Systematic Approach to Evaluating Methods and Metrics
{kind=link}
Abstract
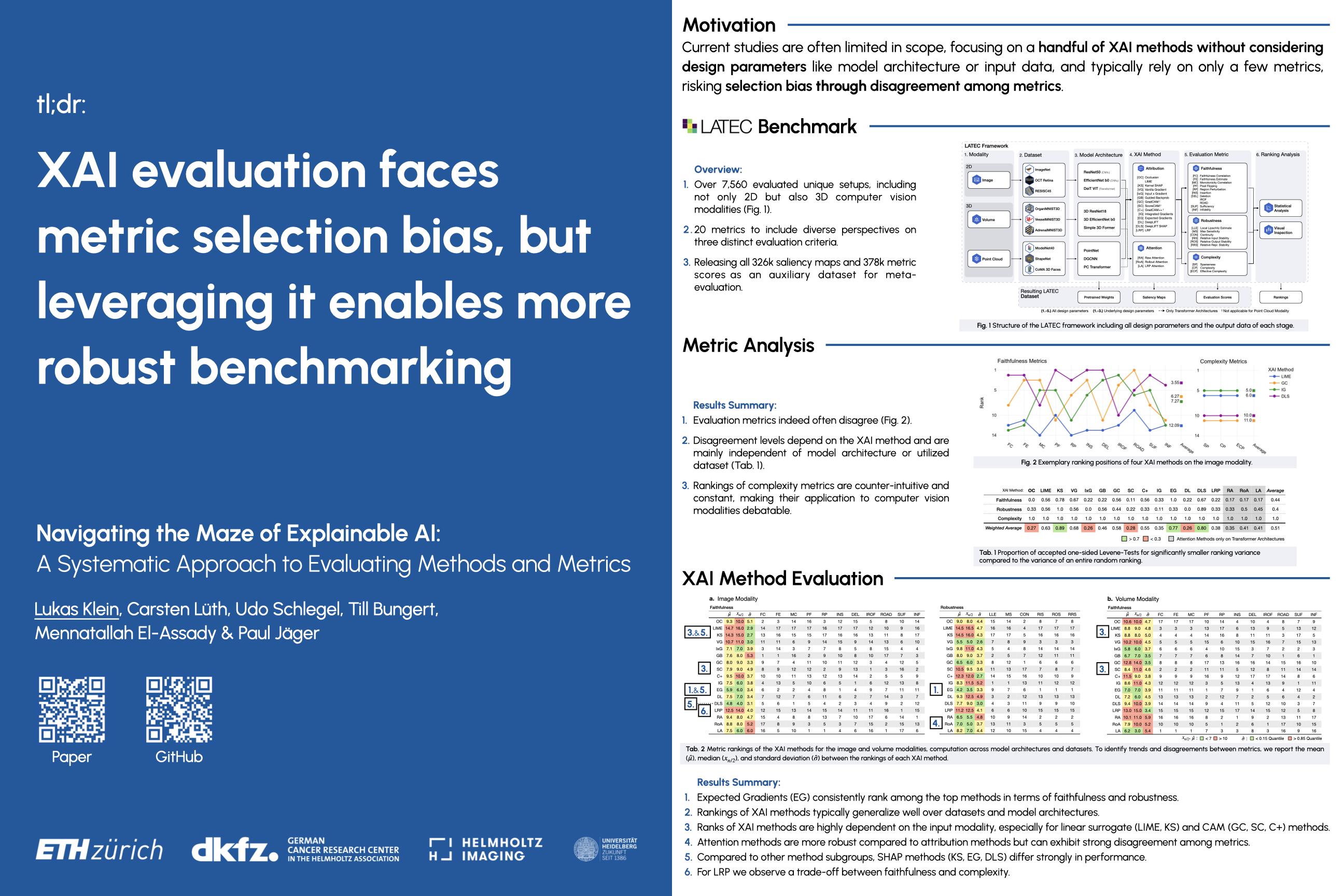
Explainable AI (XAI) is a rapidly growing domain with a myriad of proposed methods as well as metrics aiming to evaluate their efficacy. However, current studies are often of limited scope, examining only a handful of XAI methods and ignoring underlying design parameters for performance, such as the model architecture or the nature of input data. Moreover, they often rely on one or a few metrics and neglect thorough validation, increasing the risk of selection bias and ignoring discrepancies among metrics. These shortcomings leave practitioners confused about which method to choose for their problem. In response, we introduce LATEC, a large-scale benchmark that critically evaluates 17 prominent XAI methods using 20 distinct metrics. We systematically incorporate vital design parameters like varied architectures and diverse input modalities, resulting in 7,560 examined combinations. Through LATEC, we showcase the high risk of conflicting metrics leading to unreliable rankings and consequently propose a more robust evaluation scheme. Further, we comprehensively evaluate various XAI methods to assist practitioners in selecting appropriate methods aligning with their needs. Curiously, the emerging top-performing method, Expected Gradients, is not examined in any relevant related study. LATEC reinforces its role in future XAI research by publicly releasing all 326k saliency maps and 378k metric scores as a (meta-)evaluation dataset. The benchmark is hosted at: https://github.com/IML-DKFZ/latec.