Differentiable Hierarchical Visual Tokenization
Marius Aasan ⋅ Martine Hjelkrem Tan ⋅ Nico Catalano ⋅ Changkyu Choi ⋅ Adín Ramírez Rivera
2025 Spotlight Poster
{kind=link}
Abstract
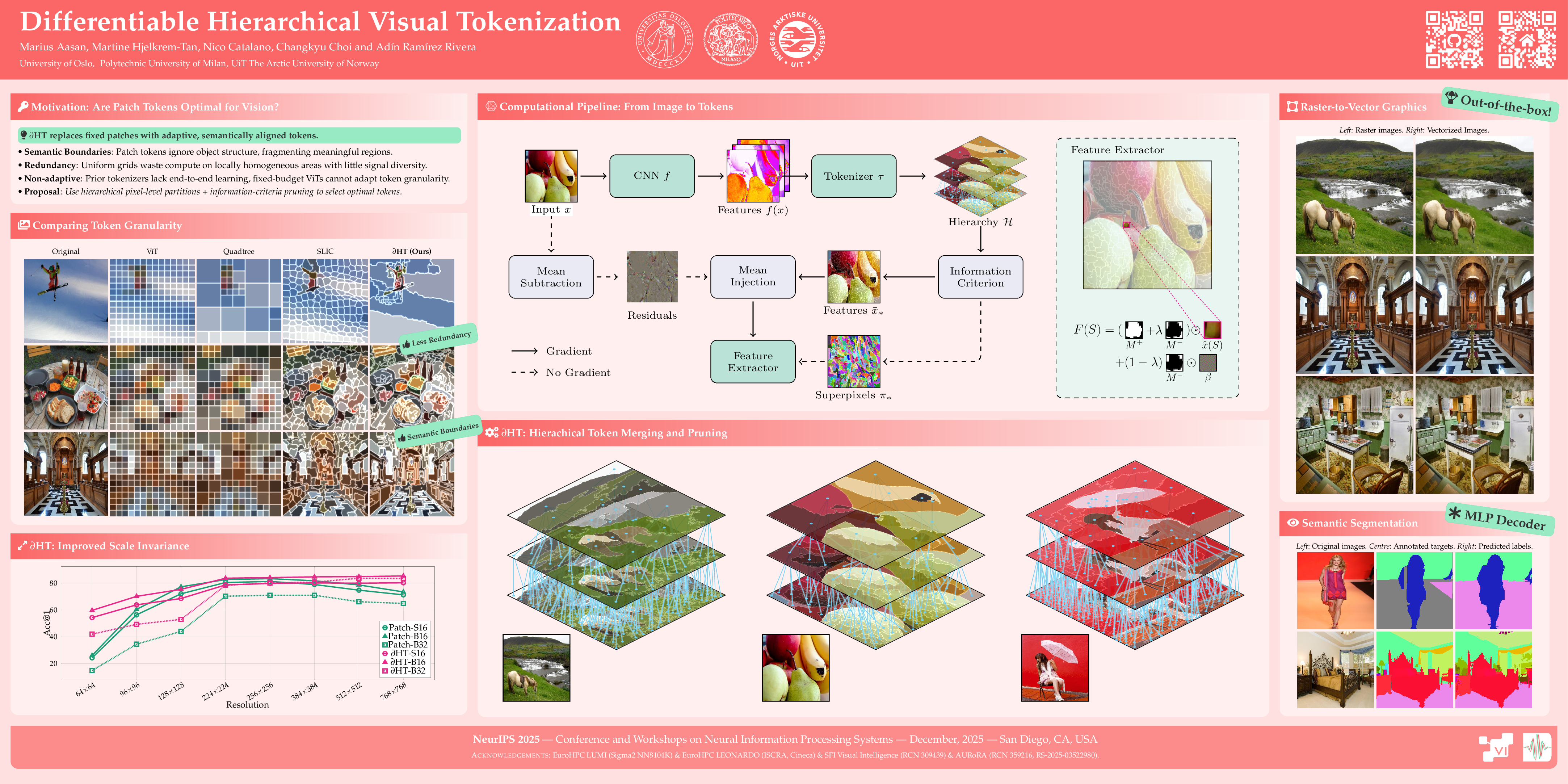
Vision Transformers rely on fixed patch tokens that ignore the spatial and semantic structure of images. In this work, we introduce an end-to-end differentiable tokenizer that adapts to image content with pixel-level granularity while remaining backward-compatible with existing architectures for retrofitting pretrained models. Our method uses hierarchical model selection with information criteria to provide competitive performance in both image-level classification and dense-prediction tasks, and even supports out-of-the-box raster-to-vector conversion.
Video
Chat is not available.
Successful Page Load