NeurIPS 2020 Competition Track
NeurIPS 2020 Accepted competitions
Below you will find a brief summary of accepted competitions for NeurIPS 2020. Regular competitions take place before the NeurIPS, whereas live competitions will have their final phase during the competition session @NeurIPS2020. Competitions are listed in alphabetical order, all prizes are tentative and depend solely on the organizing team of each competition and the corresponding sponsors. Please note that all information is subject to change, please contact the organizers of each competition directly for more information.
2020 ChaLearn 3D+Texture Garment Reconstruction
(May 13 - October 3)
Sergio Escalera (CVC and University of Barcelona), Meysam Madadi (CVC), Hugo Bertiche (University of Barcelona)

In this competition we plan to push the research to better understand human dynamics in 2D and 3D, with special attention to garments. We provide a large-scale dataset (more than 2M frames) of animated garments with variable topology and type and special care to garment dynamics and realistic rendering. The dataset contains paired RGB images with 3D garment vertices in a sequence. We designed three tracks so participants can compete to develop the best method to perform 3D garment reconstruction and texture estimation in a sequence from (1) 3D garments, and (2) RGB images.
Black-Box Optimization for Machine Learning
(July 1-October 15)
Ryan Turner (Twitter), David Eriksson (Uber AI), Serim Park (Twitter), Mike Mccourt (SigOpt), Zhen Xu (4Paradigm), Isabelle Guyon (ChaLearn), Eero Laaksonen (Valohai) and Juha Kiili (Valohai)
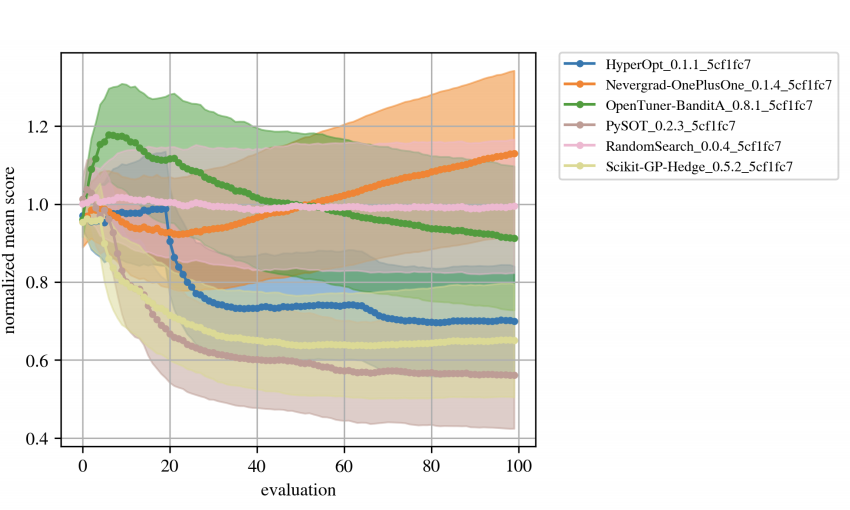
This challenge is about the optimization of black-box functions arising when tuning ML models. The configuration of the search space (function inputs) will be provided to the algorithms, but everything else about the objectives remains hidden. Submissions built from open source Bayesian optimization and/or evolutionary algorithms packages are highly encouraged.
Diagnostic Questions: Predicting Student Responses and Measuring Question Quality
(July 15-October 23)
Simon Woodhead (Eedi), Craig Barton (Eedi), José Miguel Hernández-Lobato (University of Cambridge), Richard Turner (University of Cambridge), Jack Wang (Rice University), Richard G. Baraniuk (Rice University), Angus Lamb (Microsoft Research), Evgeny Saveliev (Microsoft Research), Camilla Longden (Microsoft Research), Pashmina Cameron (Microsoft Research), Yordan Zaykov (Microsoft Research), Simon Peyton-Jones (Microsoft Research), Chen Zhang (Microsoft Research)

In the personalisation of education, the questions used to assess students’ learning is paramount, we aim to learn as much as we can from each interaction with the student. Diagnostic questions are designed to elicit not just if a student understands a concept but why they do not understand it. In this competition, participants will aim to predict students’ answers to diagnostic questions, provide a measure of question quality, and determine which sequence of diagnostic questions best predicts students’ answers.
Efficient Open-Domain Question Answering
(June 15 - October 31)
Tom Kwiatkowski (Google), Chris Alberti (Google), Jordan Boyd-Graber (University of Maryland), Danqi Chen (Princeton University), Eunsol Choi (UT Austin), Michael Collins (Google), Kelvin Guu (Google), Hannaneh Hajishirzi (University of Washinton), Kenton Lee (Google), Jennimaria Palomaki (Google), Colin Raffel (Google), Adam Roberts (Google)
You will develop a question answering system that contains all of the knowledge required to answer open-domain questions. There are no constraints on how the knowledge is stored within your system---it could be in documents, databases, the parameters of a neural network, or any other form. However, prizes will be awarded for the best performing systems that store and access this knowledge using the smallest number of bytes, including code, corpora, and model parameters. There will also be an unconstrained track, in which the goal is to achieve the best possible question answering performance with no constraints. The best performing systems from each of the tracks will be put to test in a live competition against trivia experts at NeurIPS 2020.
(June 1 - October 16)
Sharada Mohanty (AICrowd), Erik Nygren (SBB), Christian Eichenberger (SBB), Christian Baumberger (SBB), Adrian Egli ( SBB), Giacomo Spigler (University of Tilburg), Jeremy Watson(AICrowd), Florian Laurent (AICrowd), Christian Scheller (FHNW), Nilabha Bhattacharya, Guillaume Sartoretti (National University of Singapore), Irene Sturm ( DB), Sven Koenig (University of Southern California)
Multi Agent Reinforcement Learning on Trains. Flatland is a competition to facilitate the progress of multi-agent reinforcement learning for many vehicle re-scheduling problems. Using reinforcement learning (or operations research methods) the participants must schedule and re-schedule hundreds of trains in different simulated railway networks.
(July 1 - October 1)
James Jordon (University of Oxford), Daniel Jarrett (University of Cambridge), Jinsung Yoon (University of California, Los Angeles), Paul Elbers (Amsterdam UMC), Patrick Thoral (Amsterdam UMC), Ari Ercole (University of Cambridge), Cheng Zhang (Microsoft), Danielle Belgrave (Microsoft Research / Imperial), Mihaela van der Schaar (University of Cambridge, The Alan Turing Institute, UCLA), Nick Maxfield (University of Cambridge)
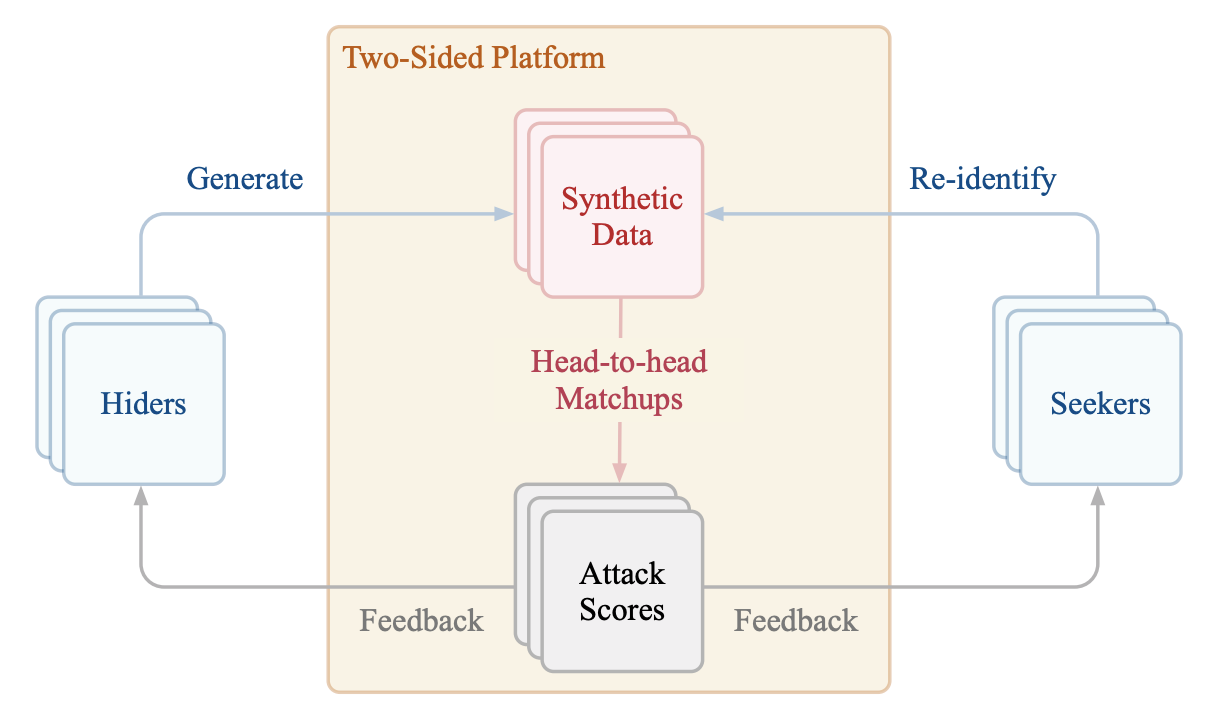
The NeurIPS 2020 Hide-and-Seek Privacy Challenge is a novel two-tracked competition to simultaneously accelerate progress in tackling both generation of private synthetic data and membership inference attacks. In our head-to-head format, participants in the synthetic data generation track (i.e. “hiders”) and the patient re-identification track (i.e. “seekers”) are directly pitted against each other by way of a new, high-quality intensive care time-series dataset: the AmsterdamUMCdb dataset. Ultimately, we seek to advance generative techniques for dense and high-dimensional temporal data streams that are (1) clinically meaningful in terms of fidelity and predictivity, as well as (2) capable of minimizing membership privacy risks in terms of the concrete notion of patient re-identification.
INTERPRET: INTERACTION-Dataset-based PREdicTion Challenge
(June 15 - October 31)
Wei Zhan (University of California, Berkeley), Liting Sun (University of California, Berkeley), Hengbo Ma (UC Berkeley), Masayoshi TOMIZUKA (MSC Lab)
It is a consensus in both academia and industry that behavior prediction is one of the most challenging problems blocking the realization of fully autonomous vehicles. One of the reasons is the lack of benchmarks and appropriate evaluation metrics. Therefore, we organize a prediction challenge based on the INTERACTION dataset, i.e., the INTERACTION - Dataset-based PREdicTion Challenge (INTERPRET) which offers multiple evaluation metrics. The competition offers multiple tracks, including for instance, a regular track, a data-efficiency track, and a fatality-aware test track. Participants are welcome to attend competitions via multiple tracks.
Learning to run a power network in a sustainable world
(July 9 - October 29)
Antoine Marot (RTE France), Isabelle Guyon (ChaLearn/INRIA/U. Paris-Saclay), Benjamin Donnot (RTE France), Gabriel Dulac-Arnold (Google), Patrick Panciatici (RTE France), Mariette Awad (American University of Beirut, Beirut, Lebanon), Aidan O’Sullivan (UCL), Adrian Kelly (EPRI), Zigfried Hampel-Arias (IQT Labs - Lab 41).
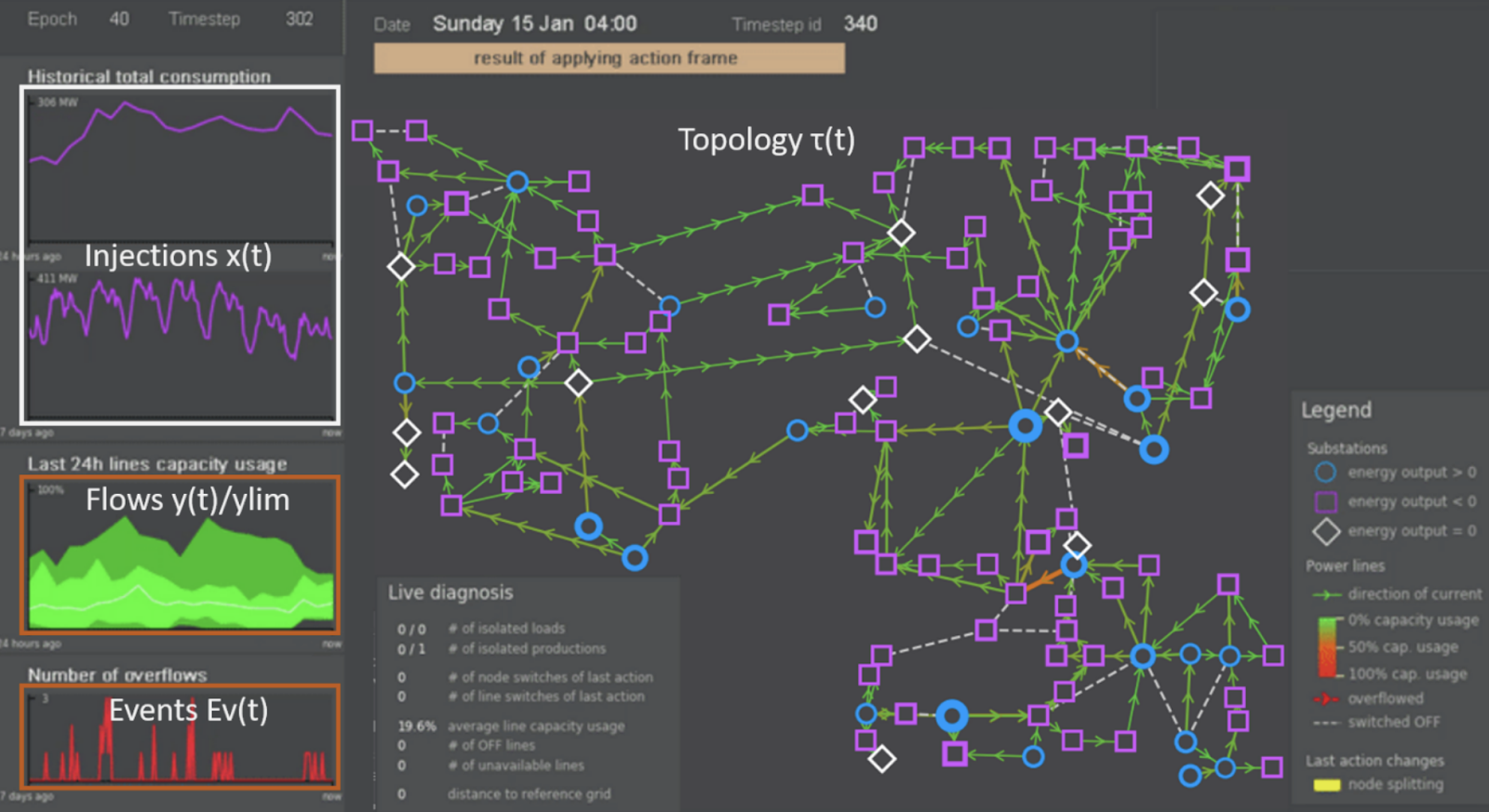
On the way towards a sustainable future, this competition aims at unleashing the power of reinforcement learning for a real-world industrial application: controlling electricity power transmission and moving closer to truly “smart” grids using underutilized flexibilities. In track 1, develop your agent to be robust to unexpected events and keep delivering reliable electricity everywhere even in difficult circumstances. In track 2, develop your agent to adapt to new energy productions in the grid with an increasing share of less controllable renewable energies over years. Keywords: Reinforcement Learning, Control problems, Safe Machine Learning, Representation and Transfer learning, Sample Efficient Learning.
(May 31- October 31)
Mayank Agarwal (IBM Research (MIT-IBM Watson AI Lab)), Jorge Barroso Carmona(IBM Research), Tathagata Chakraborti (IBM Research AI), Eli Dow (IBM Research), Oren Etzioni (Allen Institute for AI (AI2)), Borja Godoy (IBM Research), Victoria Lin (Salesforce), Kartik Talamadupula (IBM Research)
The NLC2CMD competition brings the power of natural language processing to the command line interface. Participants will be tasked with building models that can transform descriptions of command-line tasks in English to their Bash syntax.
Predicting Generalization in Deep Learning
(July 15 - October 8)
YiDing Jiang (Google), Pierre Foret (Google), Scott Yak (Google Inc.), Daniel Roy (University of Toronto), Hossein Mobahi (Google Research), Gintare Karolina Dziugaite (Element AI), Samy Bengio (Google Research, Brain Team), Suriya Gunasekar (TTI Chicago), Behnam Neyshabur (Google)
In this competition, we invite competitors to design metrics that accurately predict the generalization performance of deep neural networks without using a test set. The competitors will be asked to implement a function that takes a trained model and its training data, and returns a single scalar that correlates with the generalization ability of the model. The function will be evaluated on a wide range of models and datasets using rigorous protocols.
(June 1 - October 16)
Sharada Mohanty (AICrowd), Karl Cobbe (OpenAI), Christopher Hesse (OpenAI), Jacob Hilton (OpenAI), Jeremy Watson (AICrowd), William Guss (OpenAI) John Schulman (OpenAI)

Procgen Benchmark is a suite of 16 procedurally generated game-like environments designed to benchmark both sample efficiency and generalization in reinforcement learning. In this competition, participants submit their code which we use to train on all of the 16 publicly available procgen environments, and also on 4 private procgen environments. The same codebase (when trained separately) is expected to generalize across all the public and private environments while still respecting a sampling budget of 8 Million timesteps during each of the training phases.
SpaceNet 7: Multi-Temporal Urban Development Challenge
(August 31- October 23)
Adam Van Etten (CosmiQ Works, In-Q-Tel), Jesus Martinez Manso (Planet), Daniel Hogan (CosmiQ Works, In-Q-Tel), Ryan Lewis (CosmiQ Works), Jacob Shermeyer (CosmiQ Works, In-Q-Tel), Christyn Zehnder (In-Q-Tel)

The SpaceNet 7 Multi-Temporal Urban Development Challenge will seek to identify and track buildings in satellite imagery time series collected over rapidly urbanizing areas. The competition centers around a brand new open source dataset of Planet Labs satellite imagery mosaics, which will include 24 images (one per month) covering ≈100 unique geographies, 40,000 km2 of imagery, and exhaustive polygon labels of building footprints totalling over 3M individual annotations. We will ask participants to track building construction over time using the established Multi-Object Tracking Accuracy (MOTA) metric, thereby directly assessing urbanization. This task has broad implications for disaster preparedness, the environment, infrastructure development, and epidemic prevention.
The 2020 MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors (June 15 - Nov 21)
William Guss (Carnegie Mellon University, OpenAI), Sam Devlin (Microsoft Research), Brandon Houghton (OpenAI Inc.), Noboru Kuno (Microsoft Research), Stephanie Milani (Carnegie Mellon University), Sharada Mohanty (AICrowd), Ruslan Salakhutdinov (Carnegie Mellon University), John Schulman (OpenAI), Nicholay Topin (Carnegie Mellon University), Oriol Vinyals ( DeepMind)

In the second MineRL competition, participants develop sample efficient reinforcement and imitation learning algorithms to solve a complex task in Minecraft, a rich open-world environment featuring: sparse-rewards, long-term planning, vision, navigation, and explicit and implicit sub-task hierarchies. The competition features the MineRL-v0 dataset, a large-scale collection of over 60 million frames of human demonstrations for developing sample efficient algorithms. Participants will compete to develop systems that solve the task with a limited number of samples (4-days worth) from a new Minecraft simulator. Submissions will be evaluated by being trained and then run from scratch by the competition organizers in a fixed cloud-computing environment to ensure that truly sample-efficient algorithms are developed.
(August 15 - Dec (live competition))
Liam Paull (MILA, UOM), Andrea Censi (ETH), Jacopo Tani (ETH), Andrea F. Daniele (Toyota TI), Anne Kirsten Bowser (Duckietown), Holger Caesar (nuTonomy), Oscar Beijbom (nuTonomy), Matthew R. Walter (nuTonomy), Emilio Frazzoli (ETH, nuTonomy)
The AI Driving Olympics is a biannual competition held at NeurIPS and ICRA designed to probe the state of the art in all areas of autonomous vehicles. This time we will have two leagues: 1) Urban Driving, with several events (lane following, lane following with obstacles, and lane following with intersections) using the Duckietown autonomous driving platform and culminating in a live finals at NeurIPS 2020, and 2) Advanced Sensing, based on the nuScenes dataset, which will contain the object detection, object tracking, and object prediction events. For each event we provide the necessary tools in the form of simulators, datasets, code templates, baseline implementations, and in the case of the Urban Driving league, access to low-cost robotics hardware for testing and development.

(May 12- November 1)
Douwe Kiela (Facebook AI Research), Hamed Firooz ( Facebook), Aravind Mohan ( Facebook), Austin Reiter (Facebook AI), Tony Nelli (Facebook AI), Umut Ozertem (Facebook AI), Lucia Specia (Imperial College London), Patrick Pantel (Facebook), Devi Parikh (Georgia Tech & Facebook AI Research)
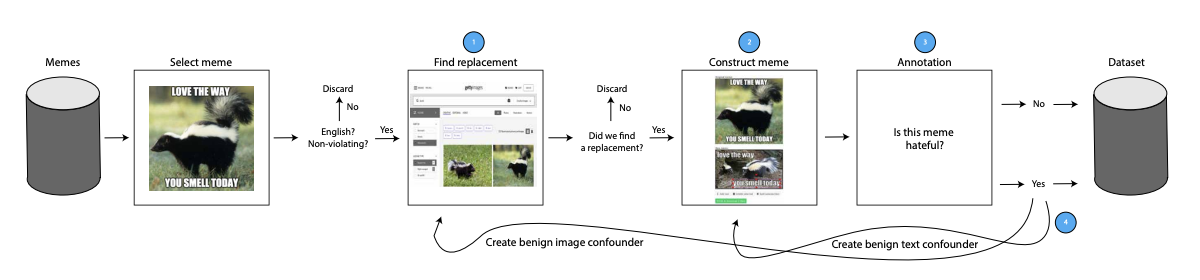
We propose a new challenge set for multimodal classification, focusing on detecting hate speech in multimodal memes. It is constructed such that unimodal models struggle and only multimodal models can succeed: difficult examples (“benign confounders”) are added to the dataset to make it hard to rely on unimodal signals. The task requires subtle reasoning, yet is straightforward to evaluate as a binary classification problem. We provide baseline performance numbers for unimodal models, as well as for multimodal models with various degrees of sophistication. We find that state-of-the-art methods perform poorly compared to humans (64.73% vs. 84.7%), illustrating the difficulty of the task and highlighting the challenge that this important problem poses to the community.
(June 3 - November 1)
Sepp Hochreiter (Institute of Advanced Research in Articial Intelligence (IARAI), Johannes-Kepler University Linz), Michael Kopp (Institute of Advanced Research in Artificial Intelligence (IARAI) , Here Technologies), D Kreil (Institute of Advanced Research in Artificial Intelligence (IARAI) GmbH), David Jonietz (Here Technologies), Ali Soleymani (Here Technologies), Moritz Neun (Here Technologies), Aleksandra Gruca (Silesian University of Technology), Pedro Herruzo (SEAT, S.A.)
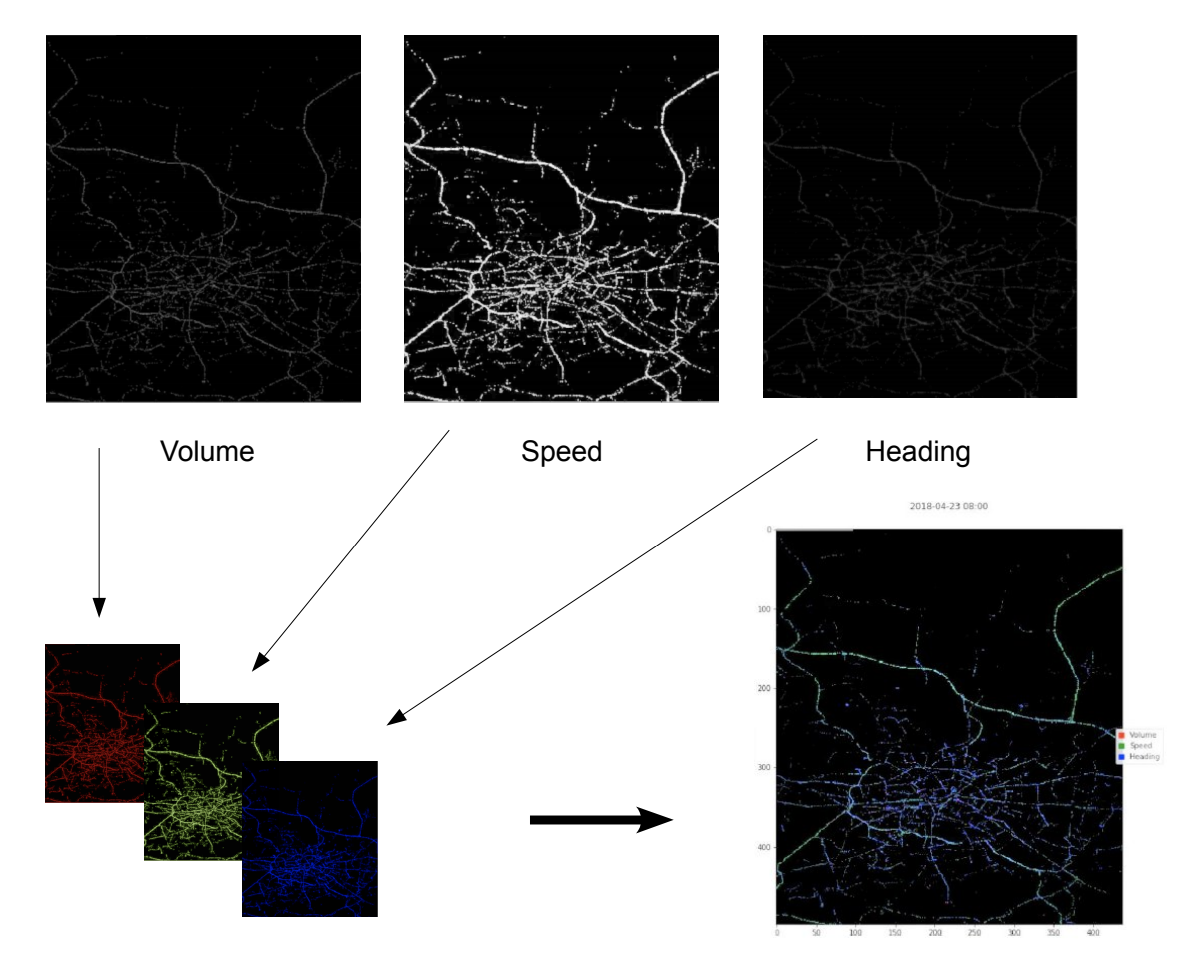
Predict high resolution traffic on a whole city map looking into the near future across the globe! Building on last year’s success, this year we are collecting traffic data from 10 cities mapped in 5 minute intervals, showing trends across weekdays and seasonal effects in a year - this is augmented with additional information such as maps of local weather, pollution, and mapping information (point of interest, street network, etc...), comprising a multi-dimensional movie, presenting the forecasting challenge as a frame prediction task. Improved traffic predictions are of great social, environmental, and economic value, while also advancing our general ability to capture the simple implicit rules underlying a complex system and model its future states.
Program committee
We are very grateful with the colleagues that helped us to review and select competition proposals:
Alexey Kurakin Google Brain
Andrea Censi ETH Zurich and nuTonomy inc.
Andreas Salzburger CERN
Antoine Ly Datascience game
Antoine Marot
Behar Veliqi University of Tubingen
Bogdan Ionescu "University Politehnica of Bucharest, Romania"
Brandon Houghton Carnegie Mellon University
Carmichael Ong Stanford University
Cecile Germain Université Paris Sud
Christoph Salge
David Ha Google
David Kreil
David Rousseau LAL-Orsay
Denny Britz Stanford University
Diego Perez-Liebana Queen Mary University of London
Emilio Cartoni Institute of Cognitive Sciences and Technologies
Esube Bekele In-Q-Tel
Evelyne Viegas Microsoft Research
Heather Gray Lawrence Berkeley National Lab
Hsueh-Cheng (Nick) Wang National Chiao Tung University
Hugo Jair Escalante INAOE
Jacopo Tani ETH Zurich
Jakob Foerster Facebook AI Research
jean-roch vlimant California Institute of Technology
Jennifer Hicks Stanford University
Joan Bruna "Courant Institute of Mathematical Sciences, NYU, USA"
Jonas Rauber University of Tübingen
Jonas Rauber University of Tubingen
Katja Hofmann Microsoft Research
Liam Paull Université de Montréal
Lino Rodriguez Coayahuitl INAOE
Łukasz Kidziński NI
Matthew Crosby Imperial College London
Mehreen Saeed
Odd Erik Gundersen Norwegian University of Science and Technology
Oscar Beijbom nuTonomy: an APTIV company
Pablo Samuel Castro Google
Qing-Shan Jia Tsinghua
Raluca Gaina Queen Mary University of London
Ron Bekkerman Cherre Inc.
Ryan Gardner
Sergio Escalera CVC and University of Barcelona
Seungmoon Song Stanford University
Stefan Bauer
Steven Farrell Lawrence Berkeley National Laboratory
Sunil Mallya Amazon AWS
Valentin Malykh MIPT
Wei-Wei Tu 4Paradigm Inc.
William Guss Carnegie Mellon University
Yoni Halpern Google
Zhengying Liu Inria