NeurIPS 2022 Competition Track Program
Below you will find a brief summary of accepted competitions NeurIPS 2022.
Competitions are grouped by category, all prizes are tentative and depend solely on the organizing team of each competition and the corresponding sponsors. Please note that all information is subject to change, visit the competition websites regularly and contact the organizers of each competition directly for more information.
Special Topics in Machine Learning
OGB-LSC 2022: A Large-Scale Challenge for ML on Graphs
Weihua Hu (Stanford University); Matthias Fey (TU Dortmund); Hongyu Ren (Stanford University); Maho Nakata (RIKEN); Yuxiao Dong (Tsinghua); Jure Leskovec (Stanford University)
Contacts: ogb-lsc@cs.stanford.edu
 Enabling effective and efficient machine learning (ML) over large-scale graph data (e.g., graphs with billions of edges) can have a huge impact on both industrial and scientific applications. At KDD Cup 2021, we organized the OGB Large-Scale Challenge (OGB-LSC), where we provided large and realistic graph ML tasks. Our KDD Cup attracted huge attention from the graph ML community (more than 500 team registrations across the globe), facilitating innovative methods being developed to yield significant performance breakthroughs. However, the problem of machine learning over large graphs is not solved yet and it is important for the community to engage in a focused multi-year effort in this area (like ImageNet and MS-COCO). Here we propose an annual ML challenge around large-scale graph datasets, which will drive forward method development and allow for tracking progress. We propose the 2nd OGB-LSC (referred to as OGB-LSC 2022) around the OGB-LSC datasets. Our proposed challenge consists of three tracks, covering core graph ML tasks of node-level prediction (academic paper classification with 240 million nodes), link-level prediction (knowledge graph completion with 90 million entities), and graph-level prediction (molecular property prediction with 4 million graphs). Importantly, we have updated two out of the three datasets based on the lessons learned from our KDD Cup, so that the resulting datasets are more challenging and realistic. Our datasets are extensively validated through our baseline analyses and last year’s KDD Cup. We also provide the baseline code as well as Python package to easily load the datasets and evaluate the model performance.
Enabling effective and efficient machine learning (ML) over large-scale graph data (e.g., graphs with billions of edges) can have a huge impact on both industrial and scientific applications. At KDD Cup 2021, we organized the OGB Large-Scale Challenge (OGB-LSC), where we provided large and realistic graph ML tasks. Our KDD Cup attracted huge attention from the graph ML community (more than 500 team registrations across the globe), facilitating innovative methods being developed to yield significant performance breakthroughs. However, the problem of machine learning over large graphs is not solved yet and it is important for the community to engage in a focused multi-year effort in this area (like ImageNet and MS-COCO). Here we propose an annual ML challenge around large-scale graph datasets, which will drive forward method development and allow for tracking progress. We propose the 2nd OGB-LSC (referred to as OGB-LSC 2022) around the OGB-LSC datasets. Our proposed challenge consists of three tracks, covering core graph ML tasks of node-level prediction (academic paper classification with 240 million nodes), link-level prediction (knowledge graph completion with 90 million entities), and graph-level prediction (molecular property prediction with 4 million graphs). Importantly, we have updated two out of the three datasets based on the lessons learned from our KDD Cup, so that the resulting datasets are more challenging and realistic. Our datasets are extensively validated through our baseline analyses and last year’s KDD Cup. We also provide the baseline code as well as Python package to easily load the datasets and evaluate the model performance.
Cross-Domain MetaDL: Any-Way Any-Shot Learning Competition with Novel Datasets from Practical Domains
Dustin Carrión (LISN/INRIA/CNRS, Université Paris-Saclay, France), Ihsan Ullah (LISN/INRIA/CNRS, Université Paris-Saclay, France), Sergio Escalera (Universitat de Barcelona and Computer Vision Center, Spain, and ChaLearn, USA), Isabelle Guyon (LISN/INRIA/CNRS, Université Paris-Saclay, France, and ChaLearn, USA), Felix Mohr (Universidad de La Sabana, Colombia), Manh Hung Nguyen (ChaLearn, USA), Joaquin Vanschoren (TU Eindhoven, the Netherlands).
Contacts: metalearningchallenge@googlegroups.com
 Meta-learning aims to leverage the experience from previous tasks to solve new tasks using only little training data, train faster and/or get better performance. The proposed challenge focuses on "cross-domain meta-learning" for few-shot image classification using a novel "any-way" and "any-shot" setting. The goal is to meta-learn a good model that can quickly learn tasks from a variety of domains, with any number of classes also called "ways" (within the range 2-20) and any number of training examples per class also called "shots" (within the range 1-20). We carve such tasks from various "mother datasets" selected from diverse domains, such as healthcare, ecology, biology, manufacturing, and others. By using mother datasets from these practical domains, we aim to maximize the humanitarian and societal impact. The competition is with code submission, fully blind-tested on the CodaLab challenge platform. A single (final) submission will be evaluated during the final phase, using ten datasets previously unused by the meta-learning community. After the competition is over, it will remain active to be used as a long-lasting benchmark resource for research in this field. The scientific and technical motivations of this challenge include scalability, robustness to domain changes, and generalization ability to tasks (a.k.a. episodes) in different regimes (any-way any-shot).
Meta-learning aims to leverage the experience from previous tasks to solve new tasks using only little training data, train faster and/or get better performance. The proposed challenge focuses on "cross-domain meta-learning" for few-shot image classification using a novel "any-way" and "any-shot" setting. The goal is to meta-learn a good model that can quickly learn tasks from a variety of domains, with any number of classes also called "ways" (within the range 2-20) and any number of training examples per class also called "shots" (within the range 1-20). We carve such tasks from various "mother datasets" selected from diverse domains, such as healthcare, ecology, biology, manufacturing, and others. By using mother datasets from these practical domains, we aim to maximize the humanitarian and societal impact. The competition is with code submission, fully blind-tested on the CodaLab challenge platform. A single (final) submission will be evaluated during the final phase, using ten datasets previously unused by the meta-learning community. After the competition is over, it will remain active to be used as a long-lasting benchmark resource for research in this field. The scientific and technical motivations of this challenge include scalability, robustness to domain changes, and generalization ability to tasks (a.k.a. episodes) in different regimes (any-way any-shot).
AutoML for the 2020s: Diverse Tasks, Modern Methods, and Efficiency at Scale
Samuel Guo (Carnegie Mellon University), Cong Xu (Hewlett Packard Labs), Nicholas Roberts (University of Wisconsin-Madison), Mikhail Khodak (Carnegie Mellon University), Junhong Shen (Carnegie Mellon University), Evan Sparks (Hewlett Packard Enterprise), Ameet Talwalkar (Carnegie Mellon University), Yuriy Nevmyvaka (Morgan Stanley), Frederic Sala (University of Wisconsin-Madison), Kashif Rasul (Morgan Stanley), Anderson Schneider (Morgan Stanley)
Contacts: automl.decathlon@gmail.com
 As more areas beyond the traditional AI domains (e.g., computer vision and natural language processing) seek to take advantage of data-driven tools, the need for developing ML systems that can adapt to a wide range of downstream tasks in an efficient and automatic way continues to grow. The AutoML for the 2020s competition aims to catalyze research in this area and establish a benchmark for the current state of automated machine learning. Unlike previous challenges which focus on a single class of methods such as non-deep-learning AutoML, hyperparameter optimization, or meta-learning, this competition proposes to (1) evaluate automation on a diverse set of small and large-scale tasks, and (2) allow the incorporation of the latest methods such as neural architecture search and unsupervised pretraining. To this end, we curate 20 datasets that represent a broad spectrum of practical applications in scientific, technological, and industrial domains. Participants are given a set of 10 development tasks selected from these datasets and are required to come up with automated programs that perform well on as many problems as possible and generalize to the remaining private test tasks. To ensure efficiency, the evaluation will be conducted under a fixed computational budget. To ensure robustness, the performance profiles methodology is used for determining the winners. The organizers will provide computational resources to the participants as needed and monetary prizes to the winners.
As more areas beyond the traditional AI domains (e.g., computer vision and natural language processing) seek to take advantage of data-driven tools, the need for developing ML systems that can adapt to a wide range of downstream tasks in an efficient and automatic way continues to grow. The AutoML for the 2020s competition aims to catalyze research in this area and establish a benchmark for the current state of automated machine learning. Unlike previous challenges which focus on a single class of methods such as non-deep-learning AutoML, hyperparameter optimization, or meta-learning, this competition proposes to (1) evaluate automation on a diverse set of small and large-scale tasks, and (2) allow the incorporation of the latest methods such as neural architecture search and unsupervised pretraining. To this end, we curate 20 datasets that represent a broad spectrum of practical applications in scientific, technological, and industrial domains. Participants are given a set of 10 development tasks selected from these datasets and are required to come up with automated programs that perform well on as many problems as possible and generalize to the remaining private test tasks. To ensure efficiency, the evaluation will be conducted under a fixed computational budget. To ensure robustness, the performance profiles methodology is used for determining the winners. The organizers will provide computational resources to the participants as needed and monetary prizes to the winners.
The Trojan Detection Challenge
Mantas Mazeika (UIUC), Dan Hendrycks (UC Berkeley), Huichen Li (UIUC), Xiaojun Xu (UIUC), Sidney Hough (Stanford), Arezoo Rajabi (UW), Dawn Song (UC Berkeley), Radha Poovendran (UW), Bo Li (UIUC), David Forsyth (UIUC)
Contacts: tdc-organizers@googlegroups.com
 A growing concern for the security of ML systems is the possibility for Trojan attacks on neural networks. There is now considerable literature for methods detecting these attacks. We propose the Trojan Detection Challenge to further the community's understanding of methods to construct and detect Trojans. This competition will consist of complimentary tracks on detecting/analyzing Trojans and creating evasive Trojans. Participants will be tasked with devising methods to better detect Trojans using a new dataset containing over 6,000 neural networks. Code and evaluations from three established baseline detectors will provide a starting point, and a novel Minimal Trojan attack will challenge participants to push the state-of-the-art in Trojan detection. At the end of the day, we hope our competition spurs practical innovations and clarifies deep questions surrounding the offense-defense balance of Trojan attacks.
A growing concern for the security of ML systems is the possibility for Trojan attacks on neural networks. There is now considerable literature for methods detecting these attacks. We propose the Trojan Detection Challenge to further the community's understanding of methods to construct and detect Trojans. This competition will consist of complimentary tracks on detecting/analyzing Trojans and creating evasive Trojans. Participants will be tasked with devising methods to better detect Trojans using a new dataset containing over 6,000 neural networks. Code and evaluations from three established baseline detectors will provide a starting point, and a novel Minimal Trojan attack will challenge participants to push the state-of-the-art in Trojan detection. At the end of the day, we hope our competition spurs practical innovations and clarifies deep questions surrounding the offense-defense balance of Trojan attacks.
Causal Insights for Learning Paths in Education
Wenbo Gong (Microsoft Research), Digory Smith (Eedi), Zichao Wang (Rice University), Simon Woodhead (Eedi), Nick Pawlowski (Microsoft Research), Joel Jennings (Microsoft Research), Cheng Zhang (Microsoft Research) Craig Barton (Eedi)
Contacts: causal_edu@outlook.com
 In this competition, participants will address two fundamental causal challenges in machine learning in the context of education using time-series data. The first is to identify the causal relationships between different constructs, where a construct is defined as the smallest element of learning. The second challenge is to predict the impact of learning one construct on the ability to answer questions on other constructs. Addressing these challenges will enable optimisation of students' knowledge acquisition, which can be deployed in a real edtech solution impacting millions of students. Participants will run these tasks in an idealised environment with synthetic data and a real-world scenario with evaluation data collected from a series of A/B tests.
In this competition, participants will address two fundamental causal challenges in machine learning in the context of education using time-series data. The first is to identify the causal relationships between different constructs, where a construct is defined as the smallest element of learning. The second challenge is to predict the impact of learning one construct on the ability to answer questions on other constructs. Addressing these challenges will enable optimisation of students' knowledge acquisition, which can be deployed in a real edtech solution impacting millions of students. Participants will run these tasks in an idealised environment with synthetic data and a real-world scenario with evaluation data collected from a series of A/B tests.
Natural Language Processing and Understanding
NL4Opt: Formulating Optimization Problems Based on Their Natural Language Descriptions
Rindranirina Ramamonjison (Huawei Technologies Canada), Amin Banitalebi-Dehkordi (Huawei Technologies Canada), Giuseppe Carenini (University of British Columbia), Bissan Ghaddar (Ivey Business School), Timothy Yu (Huawei Technologies Canada), Haley Li (University of British Columbia), Raymond Li (University of British Columbia), Zirui Zhou (Huawei Technologies Canada), Yong Zhang (Huawei Technologies Canada)
Contacts: nl4opt@gmail.com
 We propose a competition for extracting the meaning and formulation of an optimization problem based on its text description. For this competition, we have created the first dataset of linear programming (LP) word problems. A deep understanding of the problem description is an important first step toward generating the problem formulation. Therefore, we present two challenging sub-tasks for the participants. For the first sub-task, the goal is to recognize and label the semantic entities that correspond to the components of the optimization problem. For the second sub-task, the goal is to generate a meaningful representation (i.e. a logical form) of the problem from its description and its problem entities. This intermediate representation of an LP problem will be converted to a canonical form for evaluation. The proposed task will be attractive because of its compelling application, the low-barrier to the entry of the first sub-task, and the new set of challenges the second sub-task brings to semantic analysis and evaluation. The goal of this competition is to increase the access and usability of optimization solvers, allowing non-experts to solve important problems from various industries. In addition, this new task will promote the development of novel machine learning applications and datasets for operations research.
We propose a competition for extracting the meaning and formulation of an optimization problem based on its text description. For this competition, we have created the first dataset of linear programming (LP) word problems. A deep understanding of the problem description is an important first step toward generating the problem formulation. Therefore, we present two challenging sub-tasks for the participants. For the first sub-task, the goal is to recognize and label the semantic entities that correspond to the components of the optimization problem. For the second sub-task, the goal is to generate a meaningful representation (i.e. a logical form) of the problem from its description and its problem entities. This intermediate representation of an LP problem will be converted to a canonical form for evaluation. The proposed task will be attractive because of its compelling application, the low-barrier to the entry of the first sub-task, and the new set of challenges the second sub-task brings to semantic analysis and evaluation. The goal of this competition is to increase the access and usability of optimization solvers, allowing non-experts to solve important problems from various industries. In addition, this new task will promote the development of novel machine learning applications and datasets for operations research.
IGLU: Interactive Grounded Language Understanding in a Collaborative Environment
Julia Kiseleva (MSR), Alexey Skrynnik (MIPT), Artem Zholus (MIPT), Shrestha Mohanty (Microsoft), Negar Arabzadeh (University of Waterloo), Marc-Alexandre Côté (MSR), Mohammad Aliannejadi (University of Amsterdam), Milagro Teruel (MSR), Ziming Li (Amazon Alexa), Mikhail Burtsev (MIPT), Maartje ter Hoeve (University of Amsterdam), Zoya Volovikova (MIPT), Aleksandr Panov (MIPT), Yuxuan Sun (Meta AI), Kavya Srinet (Meta AI), Arthur Szlam (Meta AI), Ahmed Awadallah (MSR)
Contacts: info@iglu-contest.net
 Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment.
Human intelligence has the remarkable ability to quickly adapt to new tasks and environments. Starting from a very young age, humans acquire new skills and learn how to solve new tasks either by imitating the behavior of others or by following provided natural language instructions. To facilitate research in this direction, we propose IGLU: Interactive Grounded Language Understanding in a Collaborative Environment.
The primary goal of the competition is to approach the problem of how to develop interactive embodied agents that learn to solve a task while provided with grounded natural language instructions in a collaborative environment. Understanding the complexity of the challenge, we split it into sub-tasks to make it feasible for participants.
This research challenge is naturally related, but not limited, to two fields of study that are highly relevant to the NeurIPS community: Natural Language Understanding and Generation (NLU/G) and Reinforcement Learning (RL). Therefore, the suggested challenge can bring two communities together to approach one of the important challenges in AI. Another important aspect of the challenge is the dedication to perform a human-in-the-loop evaluation as a final evaluation for the agents developed by contestants.
Second AmericasNLP Competition: Speech-to-Text Translation for Indigenous Languages of the Americas
Manuel Mager (University of Stuttgart), Katharina Kann (University of Colorado Boulder), Abteen Ebrahimi (University of Colorado Boulder), Arturo Oncevay (University of Edinburgh), Rodolfo Zevallos (Pompeu Fabra University), Adam Wiemerslage (University of Colorado Boulder), Pavel Denisov (University of Stuttgart), John E. Ortega (New York University), Kristine Stenzel (University of Colorado Boulder), Aldo Alvarez (Universidad Nacional de Itapúa), Luis Chiruzzo (Universidad de la República), Rolando Coto-Solano (Dartmouth College), Hilaria Cruz (University of Louisville), Sofía Flores-Solórzano (University of Costa Rica), Ivan Vladimir Meza Ruiz (Universidad Nacional Autónoma de México), Alexis Palmer (University of Colorado Boulder), Ngoc Thang Vu (University of Stuttgart)
Contacts: americas.nlp.workshop@gmail.com
 AmericasNLP aims to encourage and increase the visibility of research on machine learning approaches for Indigenous languages of the Americas, as, until recently, those have often been overlooked by researchers. For the Second AmericasNLP Competition: Speech-to-Text Translation for Indigenous Languages of the Americas we ask participants to develop or contribute to the development of speech-to-text translation systems for five Indigenous languages of the Americas (Bribri, Guaraní, Kotiria, Quechua and Wa’ikhana), for which available resources are extremely limited. The main task of this competition is speech-to-text translation, and we additionally invite submissions to its two subtasks: automatic speech recognition and text-to-text machine translation.
AmericasNLP aims to encourage and increase the visibility of research on machine learning approaches for Indigenous languages of the Americas, as, until recently, those have often been overlooked by researchers. For the Second AmericasNLP Competition: Speech-to-Text Translation for Indigenous Languages of the Americas we ask participants to develop or contribute to the development of speech-to-text translation systems for five Indigenous languages of the Americas (Bribri, Guaraní, Kotiria, Quechua and Wa’ikhana), for which available resources are extremely limited. The main task of this competition is speech-to-text translation, and we additionally invite submissions to its two subtasks: automatic speech recognition and text-to-text machine translation.
Machine Learning for Physical and Life Sciences
Inferring Physical Properties of Exoplanets From Next-Generation Telescopes
Kai Yip (University College London), Ingo Waldmann (University College London), Quentin Changeat (University College London), Nikolaos Nikolaou (University College London), Mario Morvan (University College London), Ahmed Al-Rafaie (University College London), Billy Edwards (Commissariat à l’Energie Atomique et aux Energies Alternatives), Angelos Tsiaras (Instituto Nazionale di Astrofisica), Catarina Alves de Oliveira (European Space Agency), James Cho (Flatiron Institute Center for Computational Astrophysics), Pierre-Olivier Lagage (Commissariat à l’Energie Atomique et aux Energies Alternatives), Clare Jenner (Distributed Research using Advanced Computing, DiRAC), Jeyan Thiyagalingam (Rutherford Appleton Laboratory), Giovanna Tinetti (University College London)
Contacts: exoai.ucl@gmail.com
 The study of extra-solar planets, or simply, exoplanets, planets outside our own Solar System, is fundamentally a grand quest to understand our place in the Universe. Discoveries in the last two decades have re-defined what we know about planets, and helped us comprehend the uniqueness of our very own Earth. In recent years, however, the focus has shifted from planet detection to planet characterisation, where key planetary properties are inferred from telescope observations using Monte Carlo-based methods. However, the efficiency of sampling-based methodologies is put under strain by the high-resolution observational data from next generation telescopes, such as the James Webb Space Telescope and the Ariel Space Mission. We propose to host a regular competition with the goal of identifying a reliable and scalable method to perform planetary characterisation. Depending on the chosen track, participants will provide either quartile estimates or the approximate distribution of key planetary properties. They will have access to synthetic spectroscopic data generated from the official simulators for the ESA Ariel Space Mission. The aims of the competition are three-fold. 1) To offer a challenging application for comparing and advancing conditional density estimation methods. 2) To provide a valuable contribution towards reliable and efficient analysis of spectroscopic data, enabling astronomers to build a better picture of planetary demographics, and 3) To promote the interaction between ML and exoplanetary science.
The study of extra-solar planets, or simply, exoplanets, planets outside our own Solar System, is fundamentally a grand quest to understand our place in the Universe. Discoveries in the last two decades have re-defined what we know about planets, and helped us comprehend the uniqueness of our very own Earth. In recent years, however, the focus has shifted from planet detection to planet characterisation, where key planetary properties are inferred from telescope observations using Monte Carlo-based methods. However, the efficiency of sampling-based methodologies is put under strain by the high-resolution observational data from next generation telescopes, such as the James Webb Space Telescope and the Ariel Space Mission. We propose to host a regular competition with the goal of identifying a reliable and scalable method to perform planetary characterisation. Depending on the chosen track, participants will provide either quartile estimates or the approximate distribution of key planetary properties. They will have access to synthetic spectroscopic data generated from the official simulators for the ESA Ariel Space Mission. The aims of the competition are three-fold. 1) To offer a challenging application for comparing and advancing conditional density estimation methods. 2) To provide a valuable contribution towards reliable and efficient analysis of spectroscopic data, enabling astronomers to build a better picture of planetary demographics, and 3) To promote the interaction between ML and exoplanetary science.
Weather4cast - Super-Resolution Rain Movie Prediction under Spatio-temporal Shifts
Aleksandra Gruca (Silesian University of Technology), Pedro Herruzo (Institute of Advanced Research in Artificial Intelligence), Pilar Ripodas (Spanish Meteorological Agency, AEMET), Xavier Calbet (Spanish Meteorological Agency, AMET), Llorenç Lliso (Spanish Meteorological Agency, AMET), Federico Serva (European Space Agency), Bertrand Le Saux (European Space Agency), Michael Kopp (Institute of Advanced Research in Artificial Intelligence), David Kreil (Institute of Advanced Research in Artificial Intelligence), Sepp Hochreiter (Institute of Advanced Research in Artificial Intelligence)
Contacts: weather4cast@iarai.ac.at
 The Weather4cast NeurIPS Competition has a high practical impact for society: Unusual weather is increasing all over the world, reflecting ongoing climate change, and affecting communities in agriculture, transport, public health, safety, etc.
The Weather4cast NeurIPS Competition has a high practical impact for society: Unusual weather is increasing all over the world, reflecting ongoing climate change, and affecting communities in agriculture, transport, public health, safety, etc.
Can you predict future rain patterns with modern machine learning algorithms? Apply spatio-temporal modeling to complex dynamic systems. Get access to unique large-scale data and demonstrate temporal and spatial transfer learning under strong distributional shifts. We provide a super-resolution challenge of high relevance to local events: Predict future weather as measured by ground-based hi-res rain radar weather stations. In addition to movies comprising rain radar maps, you get large-scale multi-band satellite sensor images for exploiting data fusion. Winning models will advance key areas of methods research in machine learning, of relevance beyond the application domain.
Open Catalyst Challenge
Abhishek Das (Meta AI Research), Muhammed Shuaibi (Carnegie Mellon University), Aini Palizhati (Carnegie Mellon University), Siddharth Goyal (Meta AI Research), Adeesh Kolluru (Carnegie Mellon University), Janice Lan (Meta AI Research), Ammar Rizvi (Meta AI Research), Nima Shoghi (Meta AI Research), Anuroop Sriram (Meta AI Research), Brook Wander (Carnegie Mellon University), Brandon Wood (Meta AI Research), Zachary Ulissi (Carnegie Mellon University), C. Lawrence Zitnick (Meta AI Research)
Contacts: abhshkdz@fb.com
 Advancements to renewable energy processes are needed urgently to address climate change and energy scarcity around the world. Many of these processes, including the generation of electricity through fuel cells or fuel generation from renewable resources are driven through chemical reactions. The use of catalysts in these chemical reactions plays a key role in developing cost-effective solutions by enabling new reactions and improving their efficiency. Unfortunately, the discovery of new catalyst materials is limited due to the high cost of computational atomic simulations and experimental studies. Machine learning has the potential to significantly reduce the cost of computational simulations by orders of magnitude. By filtering potential catalyst materials based on these simulations, candidates of higher promise may be selected for experimental testing and the rate at which new catalysts are discovered could be greatly accelerated.
Advancements to renewable energy processes are needed urgently to address climate change and energy scarcity around the world. Many of these processes, including the generation of electricity through fuel cells or fuel generation from renewable resources are driven through chemical reactions. The use of catalysts in these chemical reactions plays a key role in developing cost-effective solutions by enabling new reactions and improving their efficiency. Unfortunately, the discovery of new catalyst materials is limited due to the high cost of computational atomic simulations and experimental studies. Machine learning has the potential to significantly reduce the cost of computational simulations by orders of magnitude. By filtering potential catalyst materials based on these simulations, candidates of higher promise may be selected for experimental testing and the rate at which new catalysts are discovered could be greatly accelerated.
The 2nd edition of the Open Catalyst Challenge invites participants to submit results of machine learning models that simulate the interaction of a molecule on a catalyst's surface. Specifically, the task is to predict the energy of an adsorbate-catalyst system in its relaxed state starting from an arbitrary initial state. From these values, the catalyst's impact on the overall rate of a chemical reaction may be estimated; a key factor in filtering potential catalysis materials. Competition participants are provided training and validation datasets containing over 6 million data samples from a wide variety of catalyst materials, and a new testing dataset specific to the competition. Results will be evaluated and winners determined by comparing against the computationally expensive approach of Density Functional Theory to verify the relaxed energies predicted. Baseline models and helper code are available on Github: https://github.com/open-catalyst-project/ocp.
Weakly Supervised Cell Segmentation in Multi-modality High-Resolution Microscopy Images
Jun Ma (University of Toronto), Ronald Xie (University of Toronto), Shamini Ayyadhury (University of Toronto), Sweta Banerjee (Indraprastha Institute of Information Technology-Delhi), Ritu Gupta (Institute Rotary Cancer Hospital of All India Institute of Medical Sciences), Anubha Gupta (Indraprastha Institute of Information Technology-Delhi), Gary D. Bader (University of Toronto), Bo Wang (University of Toronto)
Contacts: NeurIPS.CellSeg@gmail.com
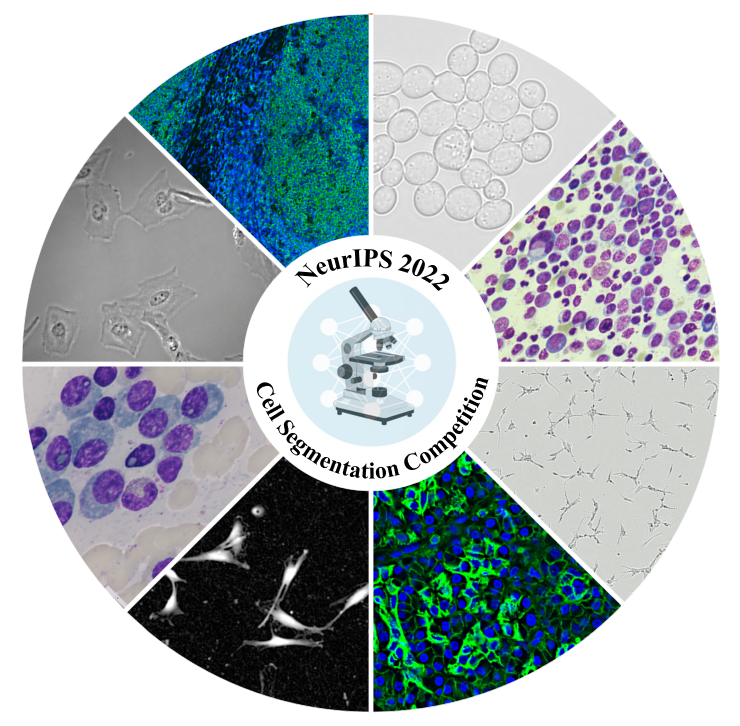 Cell segmentation is usually the first step for downstream single-cell analysis in microscopy image-based biology and biomedical research. Deep learning has been widely used for image segmentation, but it is hard to collect a large number of labelled cell images to train models because manually annotating cells is extremely time-consuming and costly. Furthermore, datasets used are often limited to one modality and lacking in diversity, leading to poor generalization of trained models. This competition aims to benchmark cell segmentation methods that could be applied to various microscopy images across multiple imaging platforms and tissue types. We frame the cell segmentation problem as a weakly supervised learning task to encourage models that use limited labelled and many unlabelled images for cell segmentation as unlabelled images are relatively easy to obtain in practice. We will implement a U-Net model as a baseline owing to their established success in biomedical image segmentation. This competition could serve as an important step toward universal and fully automatic cell image analysis tools, greatly accelerating the rate of discovery from image-based biological and biomedical research.
Cell segmentation is usually the first step for downstream single-cell analysis in microscopy image-based biology and biomedical research. Deep learning has been widely used for image segmentation, but it is hard to collect a large number of labelled cell images to train models because manually annotating cells is extremely time-consuming and costly. Furthermore, datasets used are often limited to one modality and lacking in diversity, leading to poor generalization of trained models. This competition aims to benchmark cell segmentation methods that could be applied to various microscopy images across multiple imaging platforms and tissue types. We frame the cell segmentation problem as a weakly supervised learning task to encourage models that use limited labelled and many unlabelled images for cell segmentation as unlabelled images are relatively easy to obtain in practice. We will implement a U-Net model as a baseline owing to their established success in biomedical image segmentation. This competition could serve as an important step toward universal and fully automatic cell image analysis tools, greatly accelerating the rate of discovery from image-based biological and biomedical research.
Multimodal Single-Cell Integration Across Time, Individuals, and Batches
Daniel Burkhardt (Cellarity), Jonathan Bloom (Cellarity), Robrecht Cannoodt (Data Intuitive), Malte Luecken (Helmholtz Munich), Smita Krishnaswamy (Yale University), Christopher Lance (Helmholtz Munich), Angela Pisco (Chan Zuckerberg Biohub), Fabian Theis (Helmholtz Munich)
Contacts: neurips@cellarity.com
 The last decade has witnessed a technological arms race to encode the molecular states of cells into DNA libraries, turning DNA sequencers into scalable single-cell microscopes. Single-cell measurements of DNA, RNA, and proteins have revealed rich cellular diversity across tissues and disease states. However, single-cell data poses a unique set of challenges. Identifying biologically relevant signals from the background sources of technical noise requires innovation in predictive and representational learning. Unlike in machine vision or natural language processing, biological ground truth is limited. Here, we leverage recent advances in multi-modal single-cell technologies which, by simultaneously measuring two layers of cellular processing in each cell, provide ground truth analogous to language translation. In 2021, we organized the first single-cell analysis competition at NeurIPS bringing together 280 participants to compete on an atlas-scale dataset of human bone marrow cells from 12 donors generated across 4 sites globally. This year, we will build on this success, address concerns identified from a survey of the participants in our 2021 competition, and extend the tasks to include a further open problem in single-cell data science: modelling multimodal time series. We are generating a new dataset to complement our previous atlas, modifying our competition submission system, and refining the task metrics to better capture biological processes regulating the flow of genetic information. The aim of this competition is to bring advances in representation learning (in particular, in fields involving self supervised, multi-view, and transfer learning) to unlock new capabilities bridging data science, machine learning, and computational biology. We hope this effort will be a bridge between the computational biology community and state of the art machine learning methods, which may not be traditionally associated or applied to biomedical data.
The last decade has witnessed a technological arms race to encode the molecular states of cells into DNA libraries, turning DNA sequencers into scalable single-cell microscopes. Single-cell measurements of DNA, RNA, and proteins have revealed rich cellular diversity across tissues and disease states. However, single-cell data poses a unique set of challenges. Identifying biologically relevant signals from the background sources of technical noise requires innovation in predictive and representational learning. Unlike in machine vision or natural language processing, biological ground truth is limited. Here, we leverage recent advances in multi-modal single-cell technologies which, by simultaneously measuring two layers of cellular processing in each cell, provide ground truth analogous to language translation. In 2021, we organized the first single-cell analysis competition at NeurIPS bringing together 280 participants to compete on an atlas-scale dataset of human bone marrow cells from 12 donors generated across 4 sites globally. This year, we will build on this success, address concerns identified from a survey of the participants in our 2021 competition, and extend the tasks to include a further open problem in single-cell data science: modelling multimodal time series. We are generating a new dataset to complement our previous atlas, modifying our competition submission system, and refining the task metrics to better capture biological processes regulating the flow of genetic information. The aim of this competition is to bring advances in representation learning (in particular, in fields involving self supervised, multi-view, and transfer learning) to unlock new capabilities bridging data science, machine learning, and computational biology. We hope this effort will be a bridge between the computational biology community and state of the art machine learning methods, which may not be traditionally associated or applied to biomedical data.
The SENSORIUM competition on predicting large scale mouse primary visual cortex activity
Konstantin F. Willeke (University of Tübingen), Paul G. Fahey (Baylor College of Medicine), Mohammad Bashiri (University of Tübingen), Laura Pede (University of Göttingen), Max F. Burg (University of Göttingen), Christoph Blessing (University of Göttingen), Santiago A. Cadena (University of Tübingen), Zhiwei Ding (Baylor College of Medicine), Konstantin-Klemens Lurz (University of Tübingen), Kayla Ponder (Baylor College of Medicine), Subash Prakash (University of Tübingen), Kishan Naik (University of Tübingen), Kantharaju Narayanappa (University of Tübingen), Alexander Ecker (University of Göttingen), Andreas S. Tolias (Baylor College of Medicine), Fabian H. Sinz (University of Göttingen)
Contacts: contact@sensorium2022.net
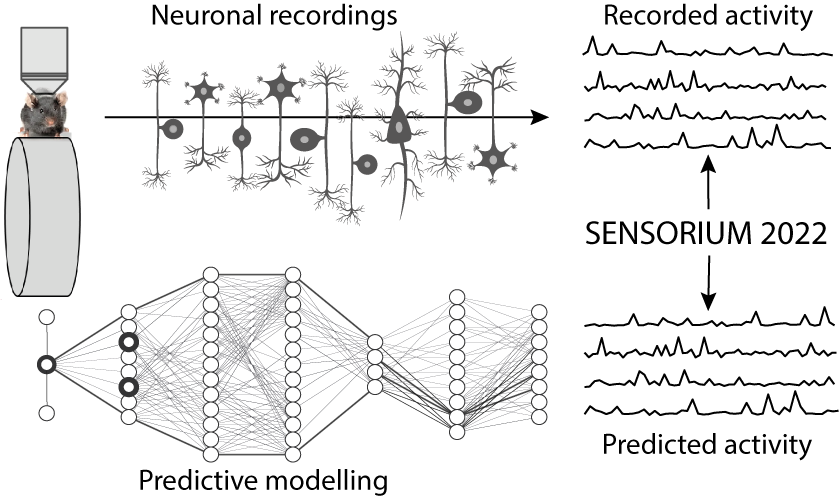 The experimental study of neural information processing in the biological visual system is challenging due to the nonlinear nature of neuronal responses to visual input. Artificial neural networks play a dual role in improving our understanding of this complex system, not only allowing computational neuroscientists to build predictive digital twins for novel hypothesis generation in silico, but also allowing machine learning to progressively bridge the gap between biological and machine vision.
The experimental study of neural information processing in the biological visual system is challenging due to the nonlinear nature of neuronal responses to visual input. Artificial neural networks play a dual role in improving our understanding of this complex system, not only allowing computational neuroscientists to build predictive digital twins for novel hypothesis generation in silico, but also allowing machine learning to progressively bridge the gap between biological and machine vision.
The mouse has recently emerged as a popular model system to study visual information processing, but no standardized large-scale benchmark to identify state-of-the-art models of the mouse visual system has been established. To fill this gap, we propose the sensorium benchmark competition. We collected a large-scale dataset from mouse primary visual cortex containing the responses of more than 28,000 neurons across seven mice stimulated with thousands of natural images.
Using this dataset, we will host two benchmark tracks to find the best predictive models of neuronal responses on a held-out test set. The two tracks differ in whether measured behavior signals are made available or not.
We provide code, tutorials, and pre-trained baseline models to lower the barrier to entering the competition. Beyond this proposal, our goal is to keep the accompanying website open with new yearly challenges for it to become a standard tool to measure progress in large-scale neural system identification models of the entire mouse visual hierarchy and beyond.
Multi-Agent Learning
The Third Neural MMO Challenge: Learning to Specialize in Massively Multiagent Open Worlds
Joseph Suarez (MIT), Sharada Mohanty (AICrowd), Jiaxin Chen (Parametrix.AI), Hanmo Chen (Parametrix.AI, Tsinghua Shenzhen International Graduate School, Tsinghua University), Hengman Zhu (Parametrix.AI), Chenghui You (Parametrix.AI), Bo Wu (Parametrix.AI), Xiaolong Zhu (Parametrix.AI), Jyotish Poonganam (AICrowd), Clare Zhu (Stanford University), Xiu Li (Tsinghua Shenzhen International Graduate School, Tsinghua University), Julian Togelius (New York University), Phillip Isola (MIT)
Contacts: https://discord.gg/BkMmFUC
Neural MMO is an open-source environment for agent-based intelligence research featuring large maps with large populations, long time horizons, and open-ended multi-task objectives. We propose a benchmark on this platform wherein participants train and submit agents to accomplish loosely specified goals -- both as individuals and as part of a team. The submitted agents are evaluated against thousands of other such user submitted agents. Participants get started with a publicly available code base for Neural MMO, scripted and learned baseline models, and training/evaluation/visualization packages. Our objective is to foster the design and implementation of algorithms and methods for adapting modern agent-based learning methods (particularly reinforcement learning) to a more general setting not limited to few agents, narrowly defined tasks, or short time horizons. Neural MMO provides a convenient setting for exploring these ideas without the computational inefficiency typically associated with larger environments.
Reconnaissance Blind Chess: An Unsolved Challenge for Multi-Agent Decision Making Under Uncertainty
Ryan W. Gardner (Johns Hopkins University Applied Physics Laboratory), Gino Perrotta (Johns Hopkins University Applied Physics Laboratory), Corey Lowman (Johns Hopkins University Applied Physics Laboratory), Casey Richardson (Johns Hopkins University Applied Physics Laboratory), Andrew Newman (Johns Hopkins University Applied Physics Laboratory), Jared Markowitz (Johns Hopkins University Applied Physics Laboratory), Nathan Drenkow (Johns Hopkins University Applied Physics Laboratory), Barton Paulhamus (Johns Hopkins University Applied Physics Laboratory), Ashley Llorens (Microsoft Research), Todd W. Neller (Gettysburg College), Raman Arora (Johns Hopkins University), Bo Li (University of Illinois Urbana-Champaign), Mykel J. Kochenderfer (Stanford University)
Contacts: ReconBlindChess@jhuapl.edu
 Reconnaissance Blind Chess (RBC) is like chess except a player cannot see her opponent's pieces in general. Rather, each player chooses a 3x3 square of the board to privately observe each turn. State-of-the-art algorithms, including those used to create agents for previous games like chess, Go, and poker, break down in Reconnaissance Blind Chess for several reasons including the imperfect information, absence of obvious abstractions, and lack of common knowledge. Build the best bot for this challenge in making strong decisions in competitive multi-agent scenarios in the face of uncertainty!
Reconnaissance Blind Chess (RBC) is like chess except a player cannot see her opponent's pieces in general. Rather, each player chooses a 3x3 square of the board to privately observe each turn. State-of-the-art algorithms, including those used to create agents for previous games like chess, Go, and poker, break down in Reconnaissance Blind Chess for several reasons including the imperfect information, absence of obvious abstractions, and lack of common knowledge. Build the best bot for this challenge in making strong decisions in competitive multi-agent scenarios in the face of uncertainty!
Urban and Environmental Challenges
EURO Meets NeurIPS 2022 Vehicle Routing Competition
Wouter Kool (ORTEC), Laurens Bliek (Eindhoven University of Technology), Reza Refaei Afshar (Eindhoven University of Technology), Yingqian Zhang (Eindhoven University of Technology), Kevin Tierney (Bielefeld University), Eduardo Uchoa (Universidade Federal Fluminense), Thibaut Vidal (Polytechnique Montréal), Joaquim Gromicho (ORTEC)
Contacts: euro-neurips-vrp-2022@ortec.com
 Solving vehicle routing problems (VRPs) is an essential task for many industrial applications. While VRPs have been traditionally studied in the operations research (OR) domain, they have lately been the subject of extensive work in the machine learning (ML) community. Both the OR and ML communities have begun to integrate ML into their methods, but in vastly different ways. While the OR community mostly relies on simplistic ML methods, the ML community generally uses deep learning, but fails to outperform OR baselines. To address this gap, this competition, a joint effort of several previous competitions, brings together the OR and ML communities to solve a challenging VRP variant on real-world data provided by ORTEC, a leading provider of vehicle routing software. The challenge focuses on both a `classic' deterministic VRP with time windows (VRPTW) and a dynamic version in which new orders arrive over the course of a day. As a baseline, we will provide a state-of-the-art VRPTW solver and a simple strategy to use it to solve the dynamic variant, thus ensuring that all competition participants have the tools necessary to solve both versions of the problem. We anticipate that the winning method will significantly advance the state-of-the-art for solving routing problems, therefore providing a strong foundation for further research in both the OR and ML communities, as well as a practical impact on the real-world solving of VRPs.
Solving vehicle routing problems (VRPs) is an essential task for many industrial applications. While VRPs have been traditionally studied in the operations research (OR) domain, they have lately been the subject of extensive work in the machine learning (ML) community. Both the OR and ML communities have begun to integrate ML into their methods, but in vastly different ways. While the OR community mostly relies on simplistic ML methods, the ML community generally uses deep learning, but fails to outperform OR baselines. To address this gap, this competition, a joint effort of several previous competitions, brings together the OR and ML communities to solve a challenging VRP variant on real-world data provided by ORTEC, a leading provider of vehicle routing software. The challenge focuses on both a `classic' deterministic VRP with time windows (VRPTW) and a dynamic version in which new orders arrive over the course of a day. As a baseline, we will provide a state-of-the-art VRPTW solver and a simple strategy to use it to solve the dynamic variant, thus ensuring that all competition participants have the tools necessary to solve both versions of the problem. We anticipate that the winning method will significantly advance the state-of-the-art for solving routing problems, therefore providing a strong foundation for further research in both the OR and ML communities, as well as a practical impact on the real-world solving of VRPs.
The CityLearn Challenge 2022
Zoltan Nagy (UT Austin), Kingsley Nweye (UT Austin), Sharada Mohanty (AI Crowd), Siva Sankaranarayanan (EPRI), Jan Drgona (PNNL), Tianzhen Hong (LBNL), Sourav Dey (CU Boulder), Gregor Henze (CU Boulder)
Contacts: nagy@utexas.edu
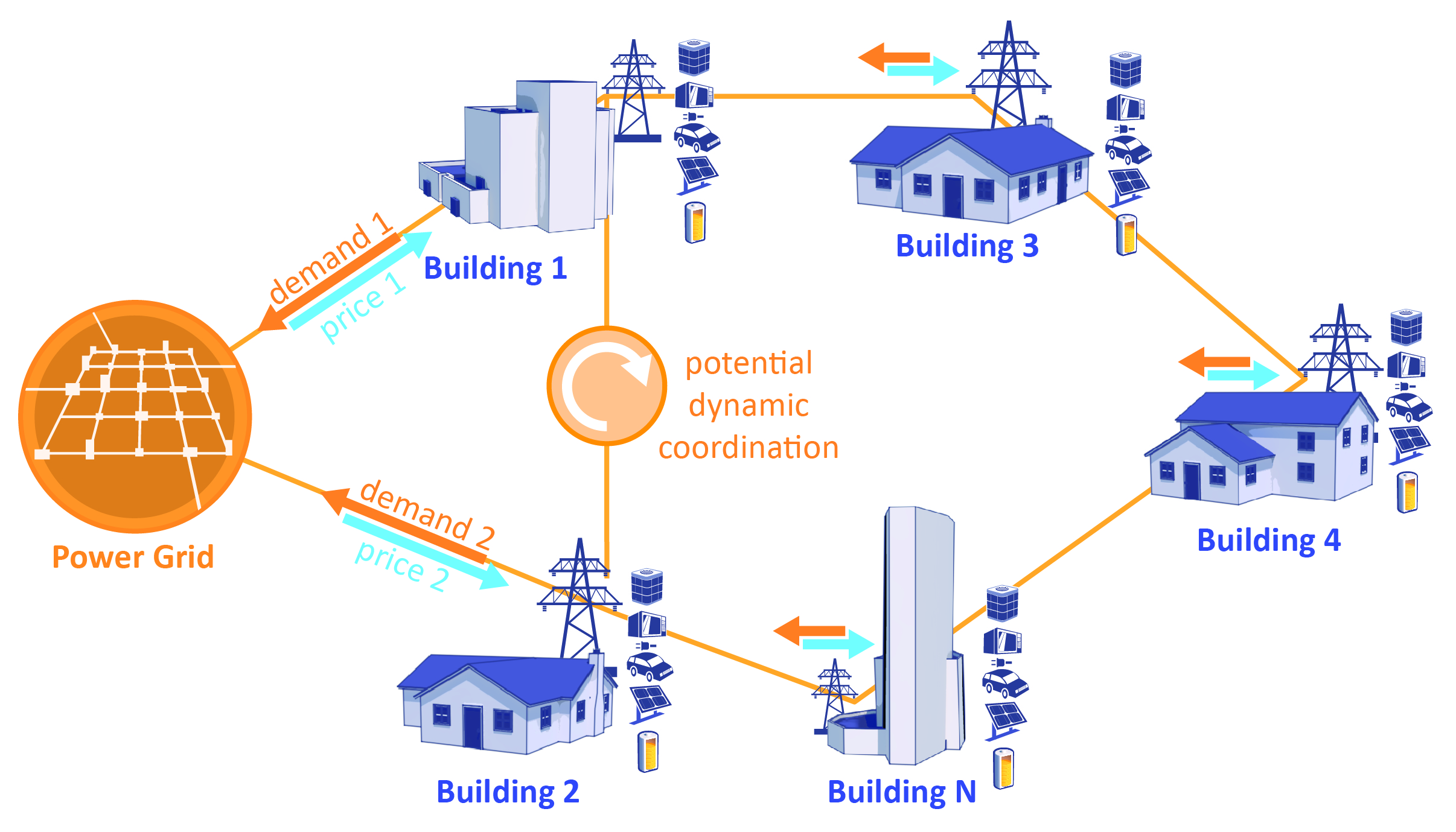 Reinforcement learning has gained popularity as a model-free and adaptive controller for the built-environment in demand-response applications. However, a lack of standardization on previous research has made it difficult to compare different RL algorithms with each other. Also, it is unclear how much effort is required in solving each specific problem in the building domain and how well a trained RL agent will scale up to new environments. The CityLearn Challenge 2022 provides an avenue to address these problems by leveraging CityLearn, an OpenAI Gym Environment for the implementation of RL agents for demand response. The challenge utilizes operational electricity demand data to develop an equivalent digital twin model of the 20 buildings. Participants are to develop energy management agents for battery charge and discharge control in each building with a goal of minimizing electricity demand from the grid, electricity bill and greenhouse gas emissions. We provide a baseline RBC agent for the evaluation of the RL agents performance and rank the participants' according to their solution's ability to outperform the baseline.
Reinforcement learning has gained popularity as a model-free and adaptive controller for the built-environment in demand-response applications. However, a lack of standardization on previous research has made it difficult to compare different RL algorithms with each other. Also, it is unclear how much effort is required in solving each specific problem in the building domain and how well a trained RL agent will scale up to new environments. The CityLearn Challenge 2022 provides an avenue to address these problems by leveraging CityLearn, an OpenAI Gym Environment for the implementation of RL agents for demand response. The challenge utilizes operational electricity demand data to develop an equivalent digital twin model of the 20 buildings. Participants are to develop energy management agents for battery charge and discharge control in each building with a goal of minimizing electricity demand from the grid, electricity bill and greenhouse gas emissions. We provide a baseline RBC agent for the evaluation of the RL agents performance and rank the participants' according to their solution's ability to outperform the baseline.
Traffic4cast 2022 – Predict Dynamics along Graph Edges from Sparse Node Data: Whole City Traffic and ETA from simple Road Counters
Moritz Neun (Institute of Advanced Research in Artificial Intelligence - IARAI), Christian Eichenberger (IARAI), Henry Martin (ETH Zürich (Switzerland), IARAI), Pedro Herruzo (Polytechnic University of Catalonia (Spain), IARAI), Markus Spanring (IARAI), Fei Tang, Kevin Malm (HERE Technologies), Michael Kopp (IARAI), David P. Kreil (IARAI), Sepp Hochreiter (Johannes Kepler University Linz (Austria), IARAI)
Contacts: traffic4cast@iarai.ac.at
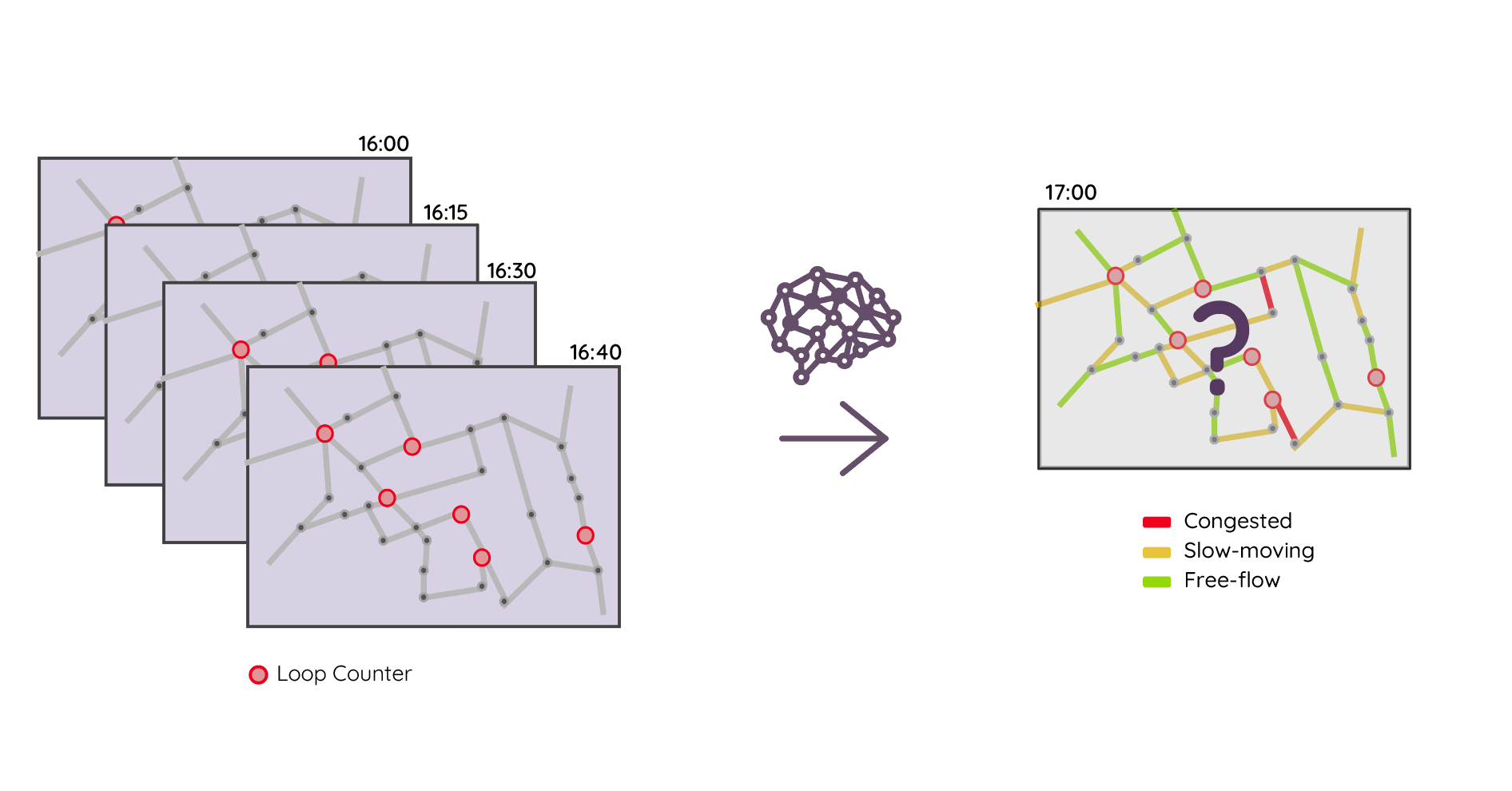 The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackle this problem in a data driven way, advancing the latest methods in modern machine learning for modelling complex spatial systems over time. This year, our dynamic road graph data combine information from road maps, 10^12 location probe data points, and car loop counters in three entire cities for two years. While loop counters are the most accurate way to capture the traffic volume they are only available in some locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. Specifically, in our core challenge we invite participants to predict for three cities the congestion classes known from the red, yellow, or green colouring of roads on a common traffic map for the entire road graph 15min into the future. We provide car count data from spatially sparse loop counters in these three cities in 15min aggregated time bins for one hour prior to the prediction time slot. For our extended challenge participants are asked to predict the actual average speeds on each road segment in the graph 15min into the future.
The global trends of urbanization and increased personal mobility force us to rethink the way we live and use urban space. The Traffic4cast competition series tackle this problem in a data driven way, advancing the latest methods in modern machine learning for modelling complex spatial systems over time. This year, our dynamic road graph data combine information from road maps, 10^12 location probe data points, and car loop counters in three entire cities for two years. While loop counters are the most accurate way to capture the traffic volume they are only available in some locations. Traffic4cast 2022 explores models that have the ability to generalize loosely related temporal vertex data on just a few nodes to predict dynamic future traffic states on the edges of the entire road graph. Specifically, in our core challenge we invite participants to predict for three cities the congestion classes known from the red, yellow, or green colouring of roads on a common traffic map for the entire road graph 15min into the future. We provide car count data from spatially sparse loop counters in these three cities in 15min aggregated time bins for one hour prior to the prediction time slot. For our extended challenge participants are asked to predict the actual average speeds on each road segment in the graph 15min into the future.
VisDA 2022 Challenge: Sim2Real Domain Adaptation for Industrial Recycling
Dina Bashkirova (Boston University), Samarth Mishra (Boston University), Piotr Teterwak (Boston University), Donghyun Kim (MIT-IBM Watson AI Lab), Diala Lteif (Boston University) , Rachel Lai (Boston University), Fadi Alladkani (Worcester Polytechnic Institute), James Akl (Worcester Polytechnic Institute), Vitaly Ablavsky (University of Washington), Sarah Adel Bargal (Boston University), Berk Calli (Worcester Polytechnic Institute), Kate Saenko (Boston University, MIT-IBM Watson AI Lab)
Contacts: visda-organizers@googlegroups.com
 Efficient post-consumer waste recycling is one of the key challenges of modern society, as countries struggle to find sustainable solutions to rapidly rising waste levels and avoid increased soil and sea pollution. The US is one of the leading countries in waste generation by volume but recycles less than 35% of its recyclable waste. Recyclable waste is sorted according to material type (paper, plastic, etc.) in material recovery facilities (MRFs) which still heavily rely on manual sorting. Computer vision solutions are an essential component in automating waste sorting and ultimately solving the pollution problem.
Efficient post-consumer waste recycling is one of the key challenges of modern society, as countries struggle to find sustainable solutions to rapidly rising waste levels and avoid increased soil and sea pollution. The US is one of the leading countries in waste generation by volume but recycles less than 35% of its recyclable waste. Recyclable waste is sorted according to material type (paper, plastic, etc.) in material recovery facilities (MRFs) which still heavily rely on manual sorting. Computer vision solutions are an essential component in automating waste sorting and ultimately solving the pollution problem.
In this sixth iteration of the VisDA challenge, we introduce a simulation-to-real (Sim2Real) semantic image segmentation competition for industrial waste sorting. We aim to answer the question: can synthetic data augmentation improve performance on this task and help adapt to changing data distributions? Label-efficient and reliable semantic segmentation is essential for this setting, but differs significantly from existing semantic segmentation datasets: waste objects are typically severely deformed and randomly located, which limits the efficacy of both shape and context priors, and have long tailed distributions and high clutter. Synthetic data augmentation can benefit such applications due to the difficulty in obtaining labels and rare categories. However, new solutions are needed to overcome the large domain gap between simulated and real images. Natural domain shift due to factors such as MRF location, season, machinery in use, etc., also needs to be handled in this application.
Competitors will have access to two sources of training data: a novel procedurally generated synthetic waste sorting dataset, SynthWaste, as well as fully-annotated waste sorting data collected from a real material recovery facility. The target test set will be real data from a different MRF.
Autonomous Systems and Task Execution
Driving SMARTS
Amir Rasouli (Huawei Canada), Randy Goebel (University of Alberta), Adam Scibior (Inverted AI), Matthew E. Taylor (University of Alberta), Iuliia Kotseruba (York University), Tianpei Yang (University of Alberta), Florian Shkurti (University of Toronto), Liam Paull (University of Montreal), Yuzheng Zhuang (Huawei), Kasra Rezaee (Huawei Canada), Animesh Garg (University of Toronto), David Meger (McGill University), Montgomery Alban (Huawei Canada), Jun Luo (Huawei Canada)
Contacts: smarts4ad@gmail.com
 Driving SMARTS is a regular competition aiming to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition is designed to support methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, using a combination of naturalistic AD data and open-source simulation platform SMARTS.
Driving SMARTS is a regular competition aiming to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition is designed to support methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, using a combination of naturalistic AD data and open-source simulation platform SMARTS.
The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions.
The proposed setup consists of 1) real-world AD data replayed in simulation to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) two baselines: random and RL-based. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
Habitat Rearrangement Challenge
Andrew Szot (Georgia Tech), Karmesh Yadav (Meta AI Research), Alex Clegg (Meta AI Research), Vincent-Pierre Berges (Meta AI Research), Aaron Gokaslan (Meta AI Research), Angel Chang (Simon Fraser University), Manolis Savva (Simon Fraser University), Zsolt Kira (Georgia Tech), Dhruv Batra (Meta AI Research)
Contacts: https://github.com/facebookresearch/habitat-challenge/issues
 We propose the Habitat Rearrangement Challenge. Specifically, a virtual robot (Fetch mobile manipulator) is spawned in a previously unseen simulation environment and asked to rearrange objects from initial to desired positions -- picking/placing objects from receptacles (counter, sink, sofa, table), opening/closing containers (drawers, fridges) as necessary. The robot operates entirely from onboard sensing -- head- and arm-mounted RGB-D cameras, proprioceptive joint-position sensors (for the arm), and egomotion sensors (for the mobile base) -- and may not access any privileged state information (no prebuilt maps, no 3D models of rooms or objects, no physically-implausible sensors providing knowledge of mass, friction, articulation of containers). This is a challenging embodied AI task involving embodied perception, mobile manipulation, sequential decision making in long-horizon tasks, and (potentially) deep reinforcement and imitation learning. Developing such embodied intelligent systems is a goal of deep scientific and societal value, including practical applications in home assistant robots.
We propose the Habitat Rearrangement Challenge. Specifically, a virtual robot (Fetch mobile manipulator) is spawned in a previously unseen simulation environment and asked to rearrange objects from initial to desired positions -- picking/placing objects from receptacles (counter, sink, sofa, table), opening/closing containers (drawers, fridges) as necessary. The robot operates entirely from onboard sensing -- head- and arm-mounted RGB-D cameras, proprioceptive joint-position sensors (for the arm), and egomotion sensors (for the mobile base) -- and may not access any privileged state information (no prebuilt maps, no 3D models of rooms or objects, no physically-implausible sensors providing knowledge of mass, friction, articulation of containers). This is a challenging embodied AI task involving embodied perception, mobile manipulation, sequential decision making in long-horizon tasks, and (potentially) deep reinforcement and imitation learning. Developing such embodied intelligent systems is a goal of deep scientific and societal value, including practical applications in home assistant robots.
The MineRL BASALT Competition on Fine-tuning from Human Feedback
Anssi Kanervisto (MSR), Stephanie Milani (CMU), Karolis Ramanauskas (Independent), Byron Galbraith (Seva Inc.), Steven Wang (ETH Zürich), Sander Schulhoff (University of Maryland), Brandon Houghton (OpenAI), Sharada Mohanty (AICrowd), and Rohin Shah (DeepMind)
Contacts: basalt@minerl.io
 Given the impressive capabilities demonstrated by pre-trained foundation models, we must now grapple with how to harness these capabilities towards useful tasks. Since many such tasks are hard to specify programmatically, researchers have turned towards a different paradigm: fine-tuning from human feedback. The MineRL BASALT competition aims to spur research on this important class of techniques, in the domain of the popular video game Minecraft. The competition consists of a suite of four tasks with hard-to-specify reward functions. We define these tasks by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants train a separate agent for each task, using any method they want; we expect participants will choose to fine-tune the provided pre-trained models. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. We believe this competition will improve our ability to build AI systems that do what their designers intend them to do, even when intent cannot be easily formalized. This achievement will allow AI to solve more tasks, enable more effective regulation of AI systems, and make progress on the AI alignment problem.
Given the impressive capabilities demonstrated by pre-trained foundation models, we must now grapple with how to harness these capabilities towards useful tasks. Since many such tasks are hard to specify programmatically, researchers have turned towards a different paradigm: fine-tuning from human feedback. The MineRL BASALT competition aims to spur research on this important class of techniques, in the domain of the popular video game Minecraft. The competition consists of a suite of four tasks with hard-to-specify reward functions. We define these tasks by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants train a separate agent for each task, using any method they want; we expect participants will choose to fine-tune the provided pre-trained models. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. We believe this competition will improve our ability to build AI systems that do what their designers intend them to do, even when intent cannot be easily formalized. This achievement will allow AI to solve more tasks, enable more effective regulation of AI systems, and make progress on the AI alignment problem.
Real Robot Challenge III -- Learning Dexterous Manipulation from Offline Data in the Real World
Georg Martius (MPI for Intelligent Systems), Nico Gürtler (MPI for Intelligent Systems), Felix Widmaier (MPI for Intelligent Systems), Cansu Sancaktar (MPI for Intelligent Systems), Sebastian Blaes (MPI for Intelligent Systems), Pavel Kolev (MPI for Intelligent Systems), Stefan Bauer (KTH Stockholm), Manuel Wüthrich (Harvard University), Markus Wulfmeier (DeepMind), Martin Riedmiller (DeepMind), Arthur Allshire (University of Toronto), Annika Buchholz (MPI for Intelligent Systems), Bernhard Schölkopf (MPI for Intelligent Systems)
Contacts: trifinger.mpi@gmail.com
 In this year's Real Robot Challenge, the participants will apply offline reinforcement learning (RL) to robotics datasets and evaluate their policies remotely on a cluster of real TriFinger robots. Usually, experimentation on real robots is quite costly and challenging. For this reason, a large part of the RL community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interaction with the environment. The purpose of this competition is to alleviate this problem by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last two years, offline RL algorithms became increasingly popular and capable. This year’s Real Robot Challenge provides a platform for evaluation, comparison and showcasing the performance of these algorithms on real-world data. In particular, we propose a dexterous manipulation problem that involves pushing, grasping and in-hand orientation of blocks.
In this year's Real Robot Challenge, the participants will apply offline reinforcement learning (RL) to robotics datasets and evaluate their policies remotely on a cluster of real TriFinger robots. Usually, experimentation on real robots is quite costly and challenging. For this reason, a large part of the RL community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interaction with the environment. The purpose of this competition is to alleviate this problem by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last two years, offline RL algorithms became increasingly popular and capable. This year’s Real Robot Challenge provides a platform for evaluation, comparison and showcasing the performance of these algorithms on real-world data. In particular, we propose a dexterous manipulation problem that involves pushing, grasping and in-hand orientation of blocks.
MyoChallenge: Learning contact-rich manipulation using a musculoskeletal hand
Vittorio Caggiano (Meta AI), Huwawei Wang (University of Twente), Guillaume Durandau (University of Twente), Seungmoon Song (Northeastern University), Yuval Tassa (Deepmind), Josh Merel (Meta), Massimo Sartori (University of Twente), Vikash Kumar (Meta AI)
Contacts: myochallenge2022@gmail.com
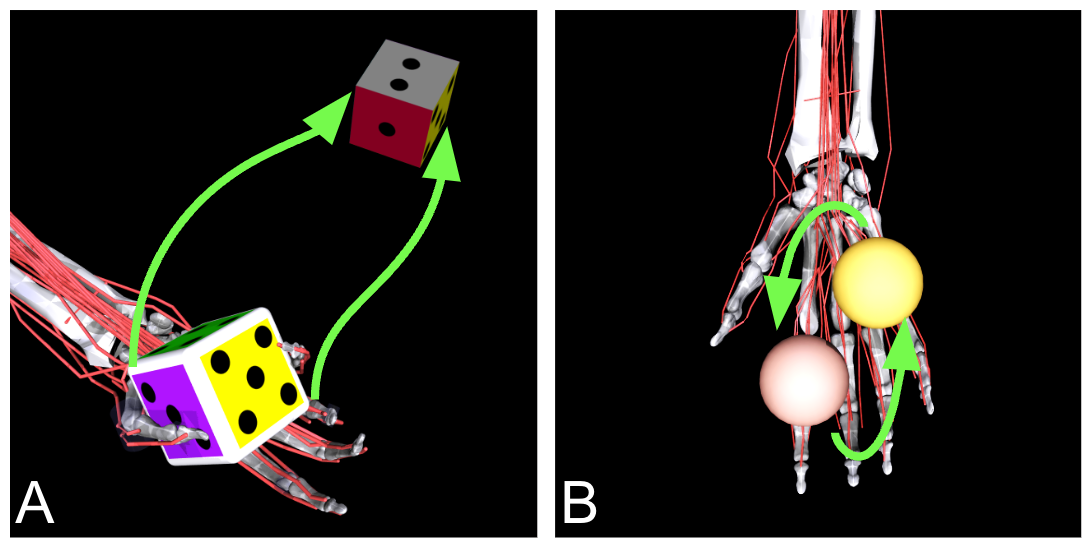 Manual dexterity has been considered one of the critical components of human evolution. The ability to perform movements as simple as holding and rotating an object in the hand without dropping it needs the coordination of more than 35 muscles which, act synergistically or antagonistically on multiple joints. They control the flexion and extension of the joints connecting the bones which in turn allow the manipulation to happen. This complexity in control is markedly different than typical pre-specified movements or torque-based controls used in robotics. In this competition - MyoChallenge, participants will develop controllers for a realistic hand to solve a series of dexterous manipulation tasks. Participants will be provided with a physiologically accurate and efficient neuromusculoskeletal human hand model developed in the (free) MuJoCo physics simulator. In addition, the provided model has also contact-rich capabilities. Participants will be interfacing with a standardized training environment to help build the controllers. The final score will then be based on an environment with unknown parameters. This challenge builds on 3 previous NeurIPS challenges on controlling legs musculoskeletal model for locomotion, which attracted about 1300 participants and generated 8000 submissions, which produced 9 academic publications. This challenge will leverage the experience and knowledge from the previous challenges and will further establish neuromusculoskeletal modeling as a benchmark for the neuromuscular control and machine learning community.
Manual dexterity has been considered one of the critical components of human evolution. The ability to perform movements as simple as holding and rotating an object in the hand without dropping it needs the coordination of more than 35 muscles which, act synergistically or antagonistically on multiple joints. They control the flexion and extension of the joints connecting the bones which in turn allow the manipulation to happen. This complexity in control is markedly different than typical pre-specified movements or torque-based controls used in robotics. In this competition - MyoChallenge, participants will develop controllers for a realistic hand to solve a series of dexterous manipulation tasks. Participants will be provided with a physiologically accurate and efficient neuromusculoskeletal human hand model developed in the (free) MuJoCo physics simulator. In addition, the provided model has also contact-rich capabilities. Participants will be interfacing with a standardized training environment to help build the controllers. The final score will then be based on an environment with unknown parameters. This challenge builds on 3 previous NeurIPS challenges on controlling legs musculoskeletal model for locomotion, which attracted about 1300 participants and generated 8000 submissions, which produced 9 academic publications. This challenge will leverage the experience and knowledge from the previous challenges and will further establish neuromusculoskeletal modeling as a benchmark for the neuromuscular control and machine learning community.
In addition of providing challenges for the biomechanics and machine learning community, this challenge will provide new opportunities to explore solutions that will inspire the robotic, medical, and rehabilitation fields on one of the most complex dexterous skills humans are able to perform.
Program committee
We are very grateful to the colleagues that helped us review and select the competition proposals for this year
Abhishek Das (Facebook AI Research)
Adeesh Kolluru (Carnegie Mellon University)
Alara Dirik (Bogazici University)
Aleksandr Panov (AIRI, MIPT)
Aleksandra Gruca (Silesian University of Technology)
Alexander Ganshin (Meteum.AI)
Alexey Skrynnik (AIRI)
Ambros Gleixner (Zuse Institut Berlin)
Amit Dhurandhar (IBM Research)
Andrew Gordon Gordon Wilson (New York University)
Andrey Malinin (Yandex)
Annika Reinke (DKFZ)
Anuroop Sriram (Facebook)
Aravind Mohan (Waymo)
Artem Zholus (MIPT)
Bastian A Rieck (Institute of AI for Health, Helmholtz Centre Munich)
Bjoern W. Schuller (Imperial College London)
Bogdan Emanuel Ionescu (University Politehnica of Bucharest)
Byron V Galbraith (Talla)
Chenran Li (University of California, Berkeley)
Chris Cameron (UBC)
Christian J. Steinmetz (Queen Mary University of London)
Christopher Morris (TU Dortmund University)
Dan Hendrycks (UC Berkeley)
Daniel B Burkhardt (Yale University)
Daniel C Suo (Princeton University)
David Kreil
David Rousseau (IJCLab-Orsay)
Dipam Chakraborty (AIcrowd)
Dmitry A Baranchuk (MSU / Yandex)
Dominik Baumann (Uppsala University)
Donghyun Kim (Boston University)
Emilio Cartoni (Institute of Cognitive Sciences and Technologies)
Erhan Bilal (IBM Research)
Ewan Dunbar (University of Toronto)
Geoffrey Siwo
George Tzanetakis (University of Victoria)
Gissel Velarde (Consultant)
Gregory Clark (Google)
Haozhe Sun (Paris-Saclay University)
Harsha Vardhan Simhadri (Microsoft Research India)
Hengbo Ma (University of California, Berkeley)
Hsueh-Cheng (Nick) Wang (National Chiao Tung University)
Hugo Jair Escalante (INAOE)
Isabelle Guyon (CNRS, INRIA, University Paris-Saclay and ChaLearn)
Jacopo Tani (ETH Zurich)
Jakob Foerster (University of Toronto)
Jan Van Rijn (Leiden University)
jean-roch vlimant (California Institute of Technology)
Jesse Engel (Google)
José Hernández-Orallo (Universitat Politecnica de Valencia)
Joseph Turian (Independent)
Julian Zilly (ETH Zurich)
Julio Saez-Rodriguez (Heidelberg University)
Kahn Rhrissorrakrai (IBM Research)
Karolis Ramanauskas
Keiko Nagami
Lei Jiang (Indiana University)
Liam Paull (University of Montreal)
Lino A Rodriguez Coayahuitl (INAOE)
Louis-Guillaume Gagnon (University of California, Berkeley)
Luis E. Ferro-Díez (Institute of Advanced Research in Artificial Intelligence (IARAI))
Matthew Walter (Toyota Technological Institute at Chicago)
Matthias Bruhns (University of Tubingen)
Matthijs Douze (Facebook AI Research)
Maxime Gasse (MILA)
Michael K Kopp (Institute of Advanced Research in Artificial Intelligence (IARAI) GmbH)
Mikhail Burtsev (MIPT)
Mohammad Aliannejadi (University of Amsterdam)
Moritz Neun (IARAI)
Muhammed Shuaibi (Carnegie Mellon University)
Odd Erik Gundersen (Norwegian University of Science and Technology)
Oliver Kroemer (Carnegie Mellon University)
Parth Patwa (PathCheck Foundation)
Pavel Izmailov (New York University)
Pedro Herruzo (Institute of Advanced Research in Artificial Intelligence)
Pranay Manocha (Princeton University)
Qi Chen (Microsoft Research Asia)
Quentin Cappart (Polytechnique Montreal)
Robert Kirk (UCL)
Rocky B Garg (Stanford University)
Ron Bekkerman (Cherre)
Sahika Genc (Amazon Artificial Intelligence)
Sai Vemprala (Microsoft)
Sebastian Farquhar (University of Oxford)
Sebastian Pokutta (ZIB)
Song Bian (Beihang University)
Steven Wang (UC Berkeley)
Tabitha Edith Lee (Carnegie Mellon University)
Tao Zhang (Department of Automation, Tsinghua University, Beijing, China)
Tianjian Zhang (The Chinese University of Hong Kong, Shenzhen)
Valentin A Malykh (MIPT)
Vitaly Kurin (University of Oxford)
Wenjie Ruan (University of Exeter)
Xiaoxi Wei (Imperial College London)
Yingshan CHANG (Carnegie Mellon University)
Yingzhen Li (Imperial College London)
Yonatan Bisk (Carnegie Mellon University)
Zhen Xu (4Paradigm)