Break the bottleneck of AI deployment at the edge.
{kind=link}
Abstract
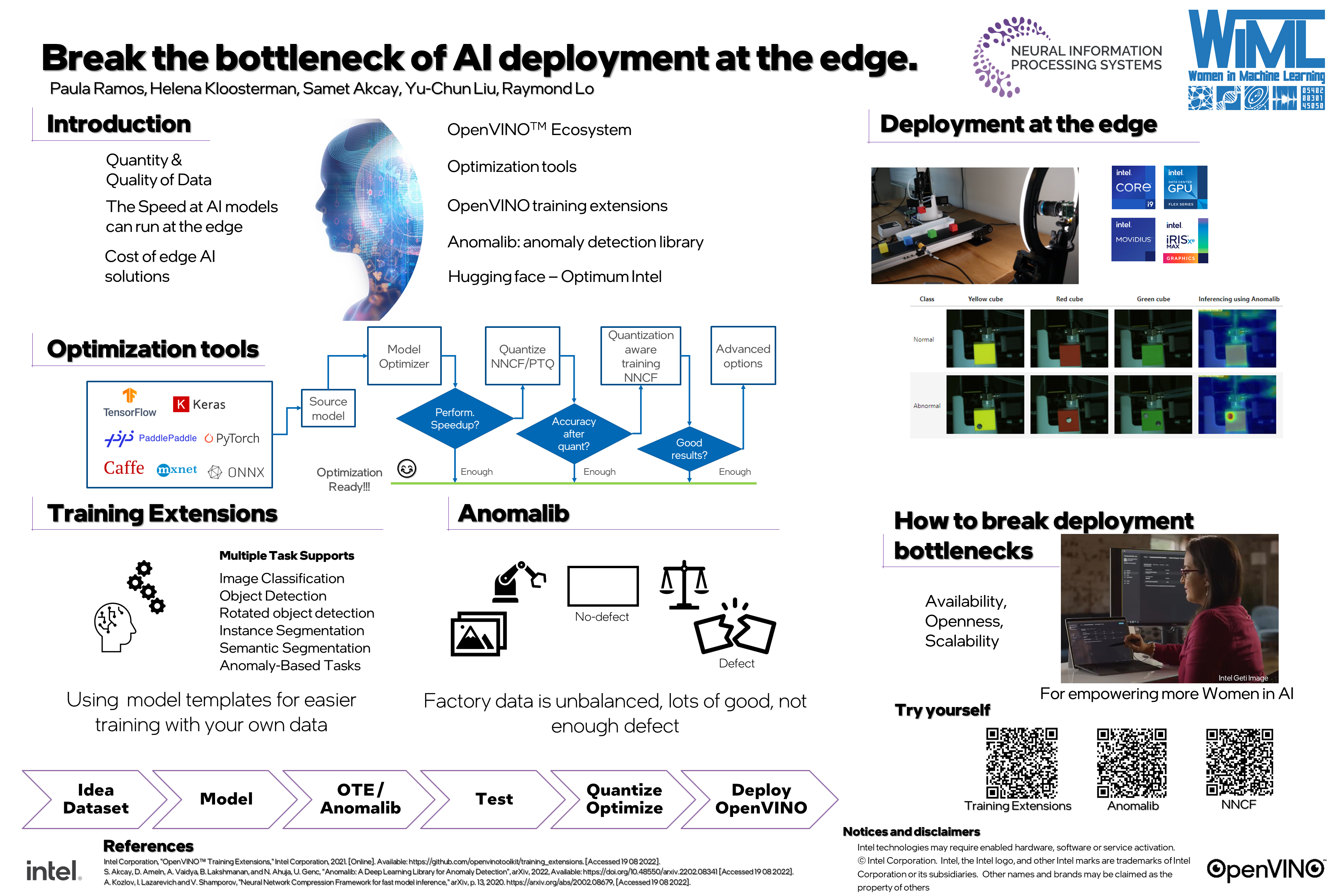
Today, the three main AI challenges in the industry are the quality and quantity of data required to create a performant AI model, the speed at which models can run at the edge, and the cost of edge solutions. To address these challenges, OpenVINO™ has developed an ecosystem that covers data management, retraining, optimization, and deployment. The Dataset Management Framework (Datumaro) builds, analyzes, and manages datasets. OpenVINO training extensions (OTE) create a suitable environment for training new computer vision models with efficient architectures using custom datasets, preserving data distribution, and achieving the best possible results for deploying models at the edge. For different use cases in industry and healthcare where there is insufficient data to initiate the supervised AI development process, OpenVINO released a new unsupervised anomaly detection library called Anomalib. The library offers several ready-to-use state-of-the-art anomaly detection algorithms from the literature and additional tools that facilitate end-to-end training and deployment pipeline. OpenVINO also provides three optimization tools that optimize deep learning models for faster, less memory-intensive execution: i) Model Optimizer (MO) swiftly converts models from various frameworks to the OpenVINO format, thereby enhancing the model's performance on Intel® processors. ii) The Post-Training Optimization Tool (POT) enables users to further accelerate the inference speed of OpenVINO format models by applying post-training quantization. iii) Neural Network Compression Framework (NNCF) integrates with PyTorch or TensorFlow training pipeline to quantize and compress models during or after training, increasing overall processing speed by 3.6x compared to the original FP16 model (SSD-300). Overall, OpenVINO has an ecosystem to facilitate a complete workflow, from data collection to model deployment, achieving high accuracy and being optimized for Intel® processors and accelerators.