Benchmarking Counterfactual Reasoning Abilities about Implicit Physical Properties
{kind=link}
Abstract
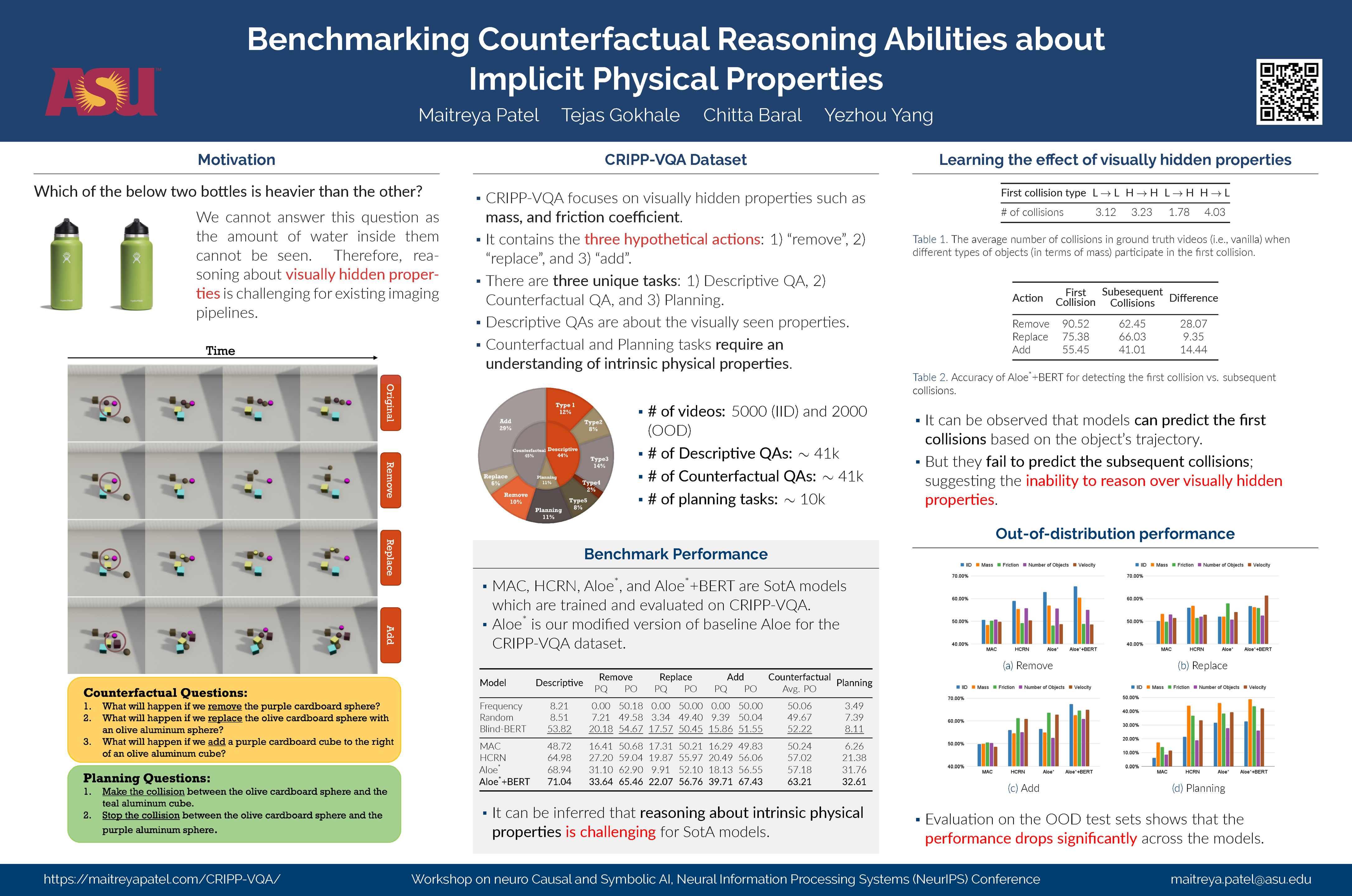
Videos often capture objects, their motion, and the interactions between different objects. Although real-world objects have physical properties associated with them, many of these properties (such as mass and coefficient of friction) are not captured directly by the imaging pipeline. However, these properties can be estimated by utilizing cues from relative object motion and the dynamics introduced by collisions. In this paper, we introduce a new video question answering task for reasoning about the implicit physical properties of objects in a scene, from videos. For this task, we introduce a dataset -- CRIPP-VQA, which contains videos of objects in motion, annotated with hypothetical/counterfactual questions about the effect of actions (such as removing, adding, or replacing objects), questions about planning (choosing actions to perform in order to reach a particular goal), as well as descriptive questions about the visible properties of objects. We benchmark the performance of existing deep learning based video question answering models on CRIPP-VQA (Counterfactual Reasoning about Implicit Physical Properties). Our experiments reveal a surprising and significant performance gap in terms of answering questions about implicit properties (the focus of this paper) and explicit properties (the focus of prior work) of objects (as shown in Table 1).