Approaches to Optimizing Medical Treatment Policy using Temporal Causal Model-Based Simulation
in
Workshop: Synthetic Data for Empowering ML Research
{kind=link}
Abstract
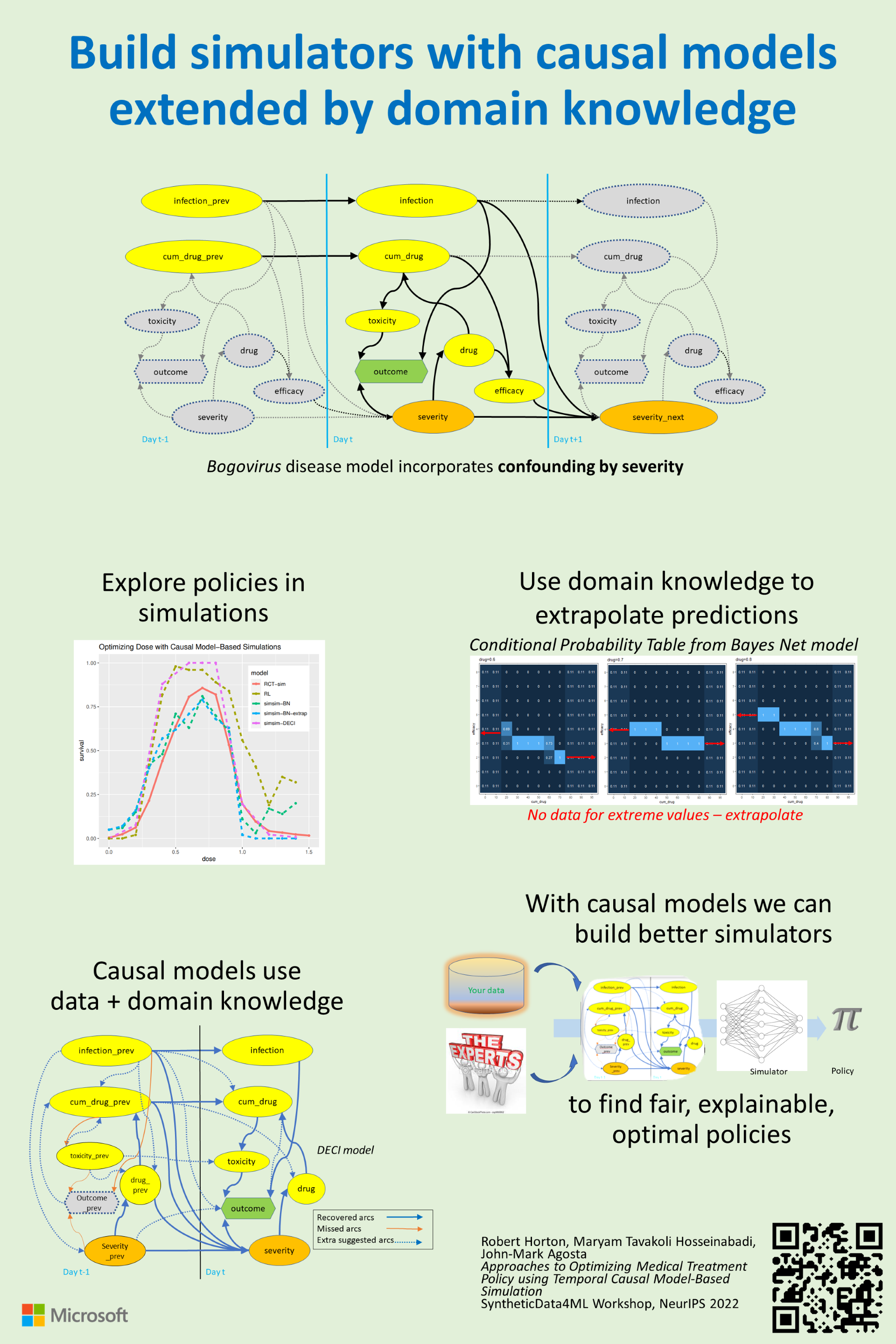
It is notoriously difficult to draw conclusions about the effects of medical interventions from observational data, where statistical confounding is rampant. An important example is "confounding by severity" in which sicker patients receive more aggressive intervention, leading to a misleading positive correlation between stronger intervention and worsening outcome. This scenario is quite generally applicable because it represents negative feedback control, where some control mechanism responds to a change by affecting the change in the opposite direction. This leads to a causal loop: the change affects the feedback and the feedback affects the change. We employ the classic approach to breaking such loops by unrolling them in time, so that the disease severity before treatment is a separate node from the severity after treatment. Unrolling produces a dataset where the information about a patient is no longer contained on a single row of a dataframe, but is spread over a set of rows representing timeslices. We want to base treatment decisions on the final outcome, which is only found at the end of this set of rows. Since we are interested in outcomes that occur at a future timeslice, we borrow a term from reinforcement learning and describe our type of intervention as a "policy". Our challenge is to properly integrate temporal modeling with causal modeling on observational data so that we can deconstruct these causal loops and reach useful analytical conclusions. Here we demonstrate a suitable analytical approach with a simple toy problem, a drug dosing policy to treat the disorder arising from infection with the fictitious pathogen Bogovirus. We begin by writing a simple bespoke simulation program to match a given causal graph; this generates a simulated dataset where we know the ground-truth about causal interactions. Using the known correct influence graph, together with other aspects of "domain knowledge", we build causal model-based simulations of the simulated data ("simsim" models) that let us estimate the expected effects of various treatment policies on ultimate outcomes. We compare this approach to the closely-relate field of reinforcement learning, and show how they are complementary.