Stutter-TTS: Synthetic Generation of Diverse Stuttered Voice Profiles
in
Workshop: Synthetic Data for Empowering ML Research
{kind=link}
Abstract
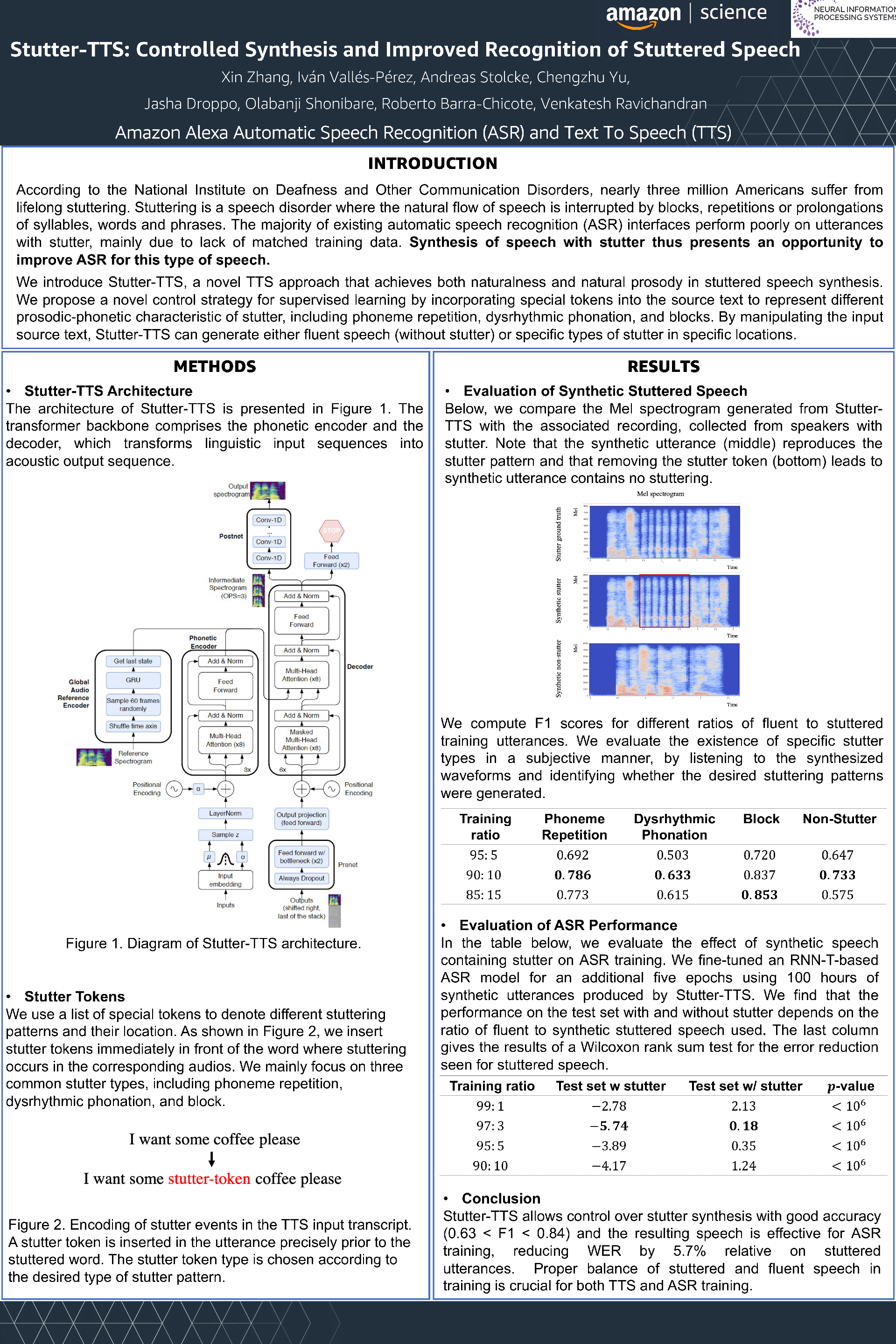
Stuttering is a speech disorder where the natural flow of speech is interrupted by blocks, repetitions or prolongations of syllables, words and phrases. The majority of existing automatic speech recognition (ASR) interfaces perform poorly on utterances with stutter, mainly due to lack of matched training data. Synthesis of stuttering voice profiles thus presents an opportunity to improve ASR for these speakers with stutter. We describe Stutter-TTS, an end-to-end neural text-to-speech model capable of synthesizing diverse types of stuttering utterances. We develop a simple, yet effective prosody-control strategy whereby additional tokens are introduced into source text during training to represent unique stuttering characteristics. By choosing the position of the stutter tokens, Stutter-TTS allows word-level control of where stuttering occurs in the synthesized utterance.