Squeezing more value out of your historical data: data-augmented behavioural cloning as launchpad for reinforcement learning
{kind=link}
Abstract
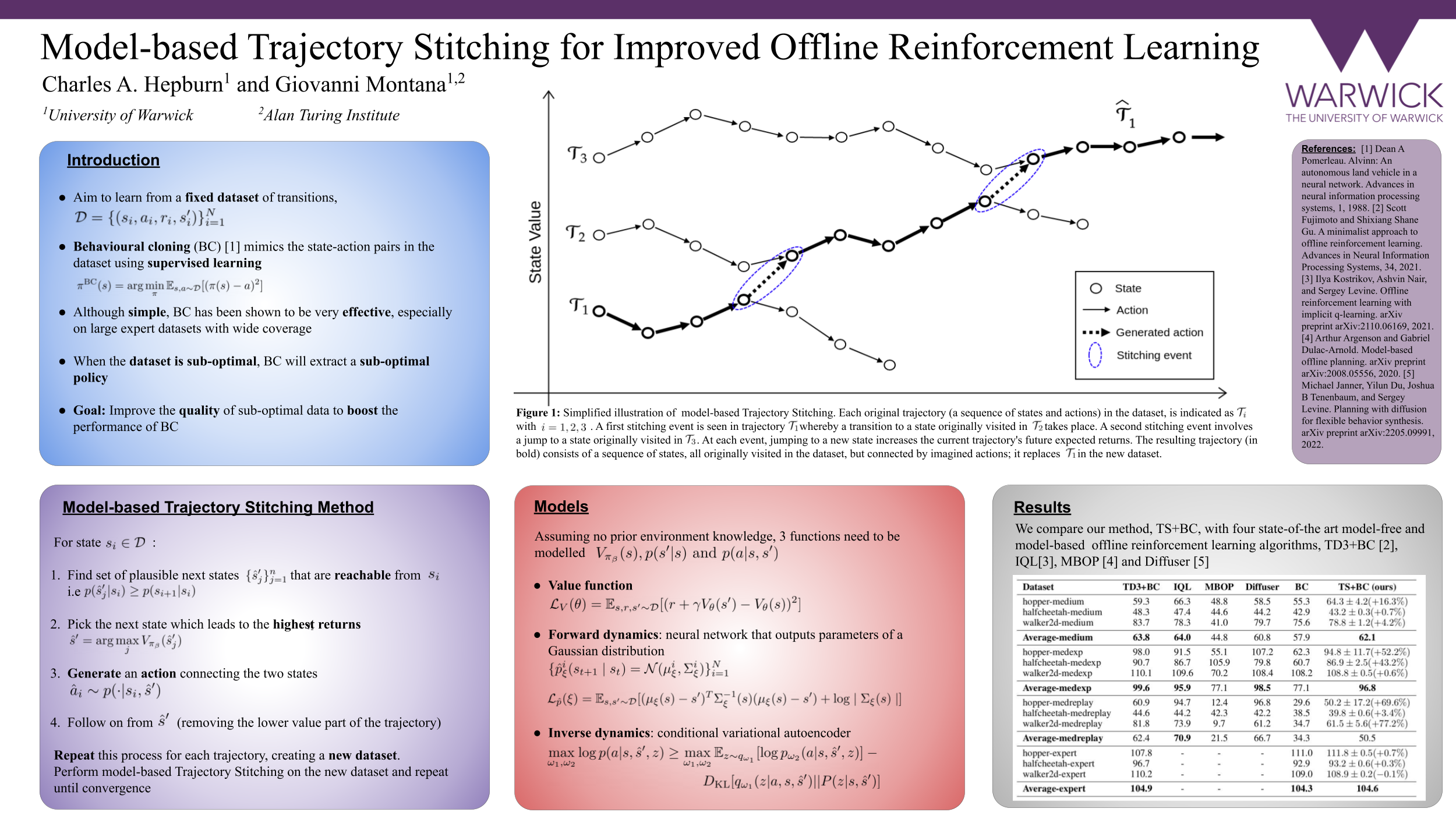
In many real-world applications collecting large, high-quality datasets may be too costly or impractical. Offline reinforcement learning (RL) aims to infer an optimal decision-making policy from a fixed set of data. Getting the most information from this dataset is then vital for good performance. We propose a model-based data augmentation strategy, Trajectory Stitching (TS), to improve the quality of sub-optimal trajectories. TS introduces unseen actions joining previously disconnected states: using a probabilistic notion of state reachability, it effectively `stitches' together parts of the historical demonstrations to generate new, higher quality ones. A stitching event consists of a transition between a pair of observed states through a synthetic and highly probable action. New actions are introduced only when they are expected to be beneficial, according to an estimated state-value function. We show that using supervised learning, behavioural cloning (BC), to extract a decision-making policy from the new TS dataset, leads to improvements over the behaviour-cloned policy from the original dataset. Improving over the BC policy could then be used as a launchpad for online RL through planning and demonstration-guided RL.