SPRINT: Scalable Semantic Policy Pre-training via Language Instruction Relabeling
{kind=link}
Abstract
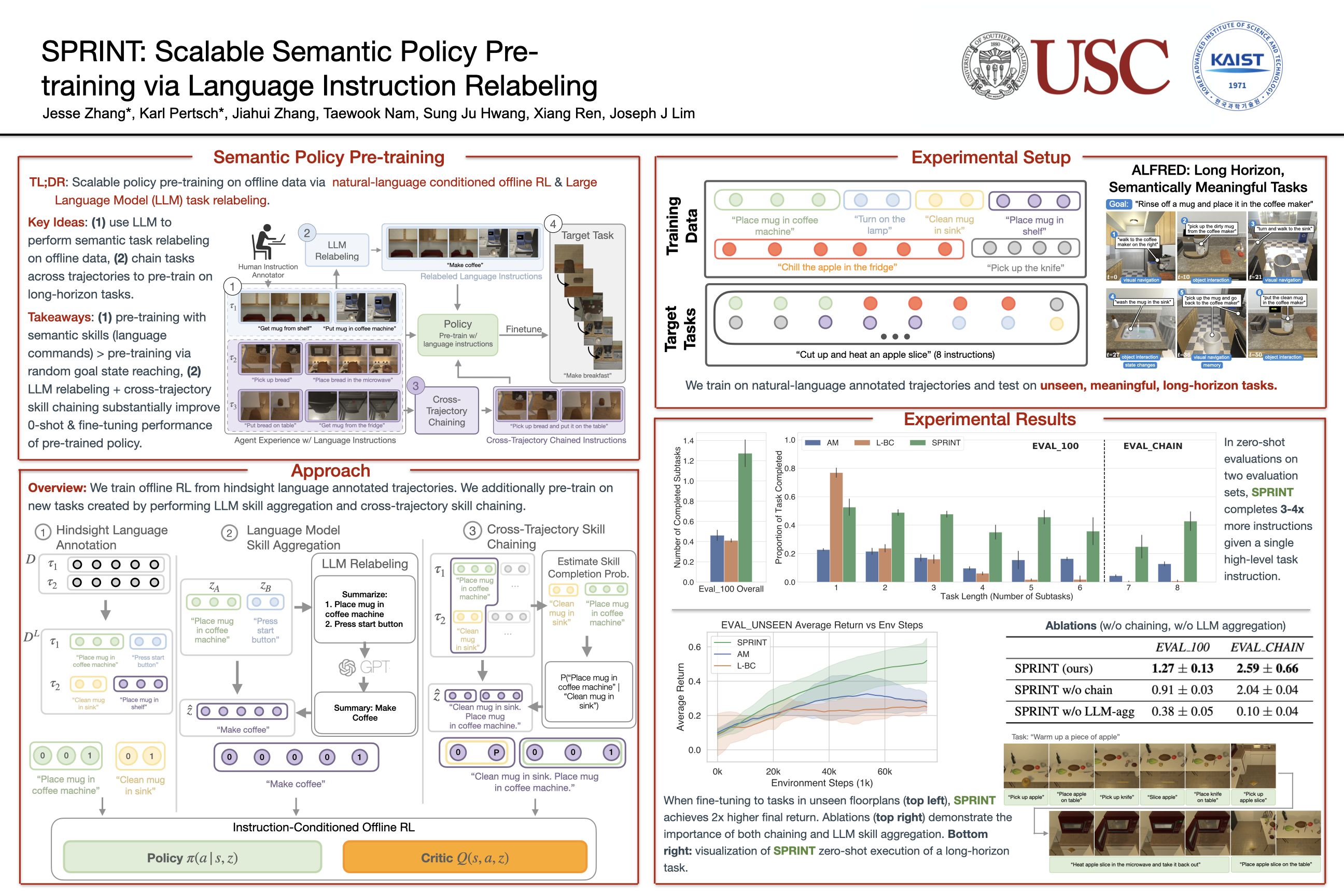
We propose SPRINT, an approach for scalable offline policy pre-training based on natural language instructions. SPRINT pre-trains an agent’s policy to execute a diverse set of semantically meaningful skills that it can leverage to learn new tasks faster. Prior work on offline pre-training required tedious manual definition of pre-training tasks or learned semantically meaningless skills via random goal-reaching. Instead, our approach SPRINT (Scalable Pre-training via Relabeling Language INsTructions) leverages natural language instruction labels on offline agent experience, collected at scale (e.g., via crowd-sourcing), to define a rich set of tasks with minimal human effort. Furthermore, by using natural language to define tasks, SPRINT can use pre-trained large language models to automatically expand the initial task set. By relabeling and aggregating task instructions, even across multiple training trajectories, we can learn a large set of new skills during pre-training. In experiments using a realistic household simulator, we show that agents pre-trained with SPRINT learn new long-horizon household tasks substantially faster than with previous pre-training approaches.