A Connection between One-Step Regularization and Critic Regularization in Reinforcement Learning
{kind=link}
Abstract
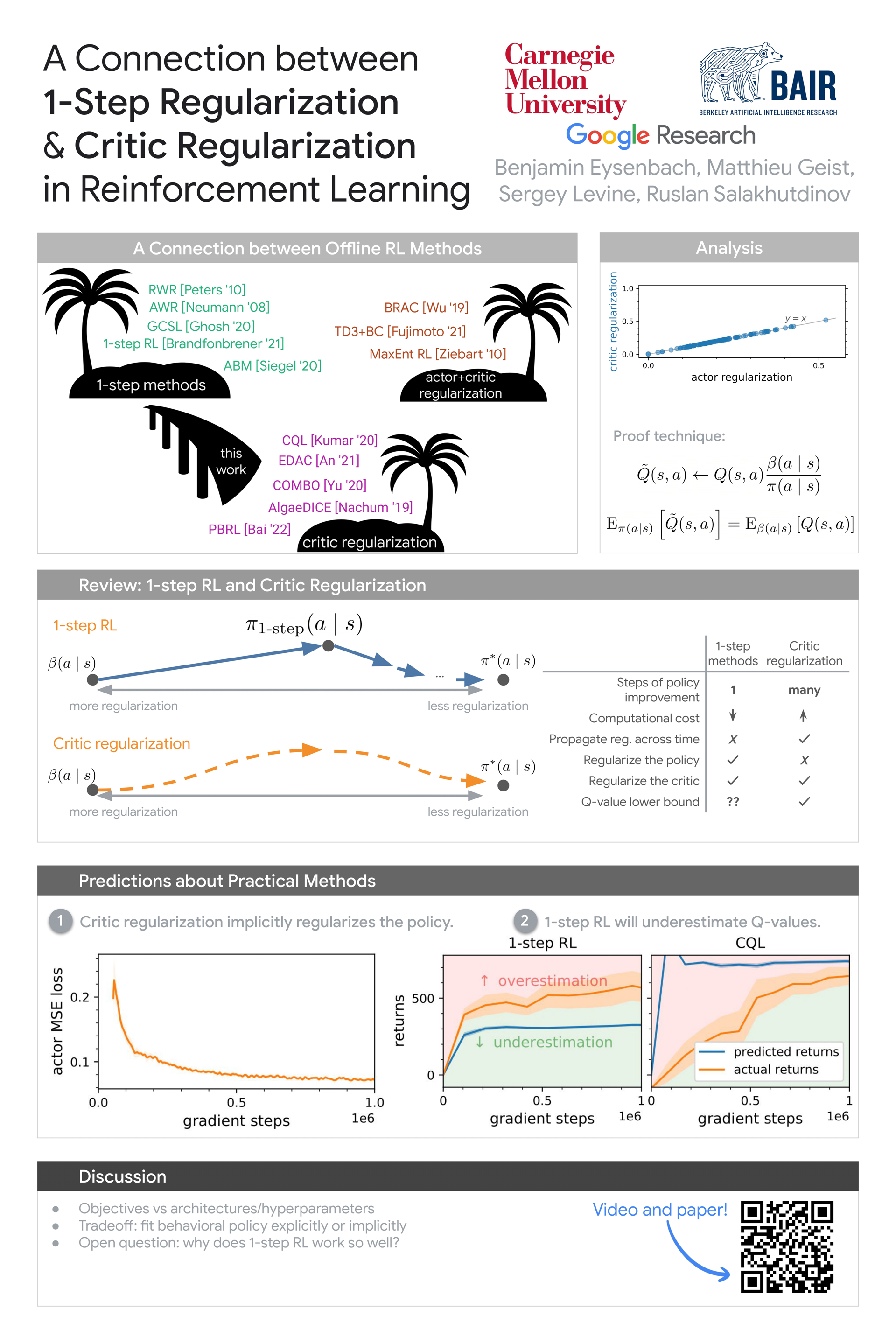
As with any machine learning problem with limited data, effective offline RL algorithms require careful regularization to avoid overfitting. One-step methods perform regularization by doing just a single step of policy improvement, while critic regularization methods do many steps of policy improvement with a regularized objective. These methods appear distinct. One-step methods, such as advantage-weighted regression and conditional behavioral cloning, truncate policy iteration after just one step. This ``early stopping'' makes one-step RL simple and stable, but can limit its asymptotic performance. Critic regularization typically requires more compute but has appealing lower-bound guarantees. In this paper, we draw a close connection between these methods: applying a multi-step critic regularization method with a regularization coefficient of 1 yields the same policy as one-step RL. While practical implementations violate our assumptions and critic regularization is typically applied with smaller regularization coefficients, our experiments nevertheless show that our analysis makes accurate, testable predictions about practical offline RL methods (CQL and one-step RL) with commonly-used hyperparameters. Our results that every problem can be solved with a single step of policy improvement, but rather that one-step RL might be competitive with critic regularization on RL problems that demand strong regularization.