Strategy-Aware Contextual Bandits
{kind=link}
Abstract
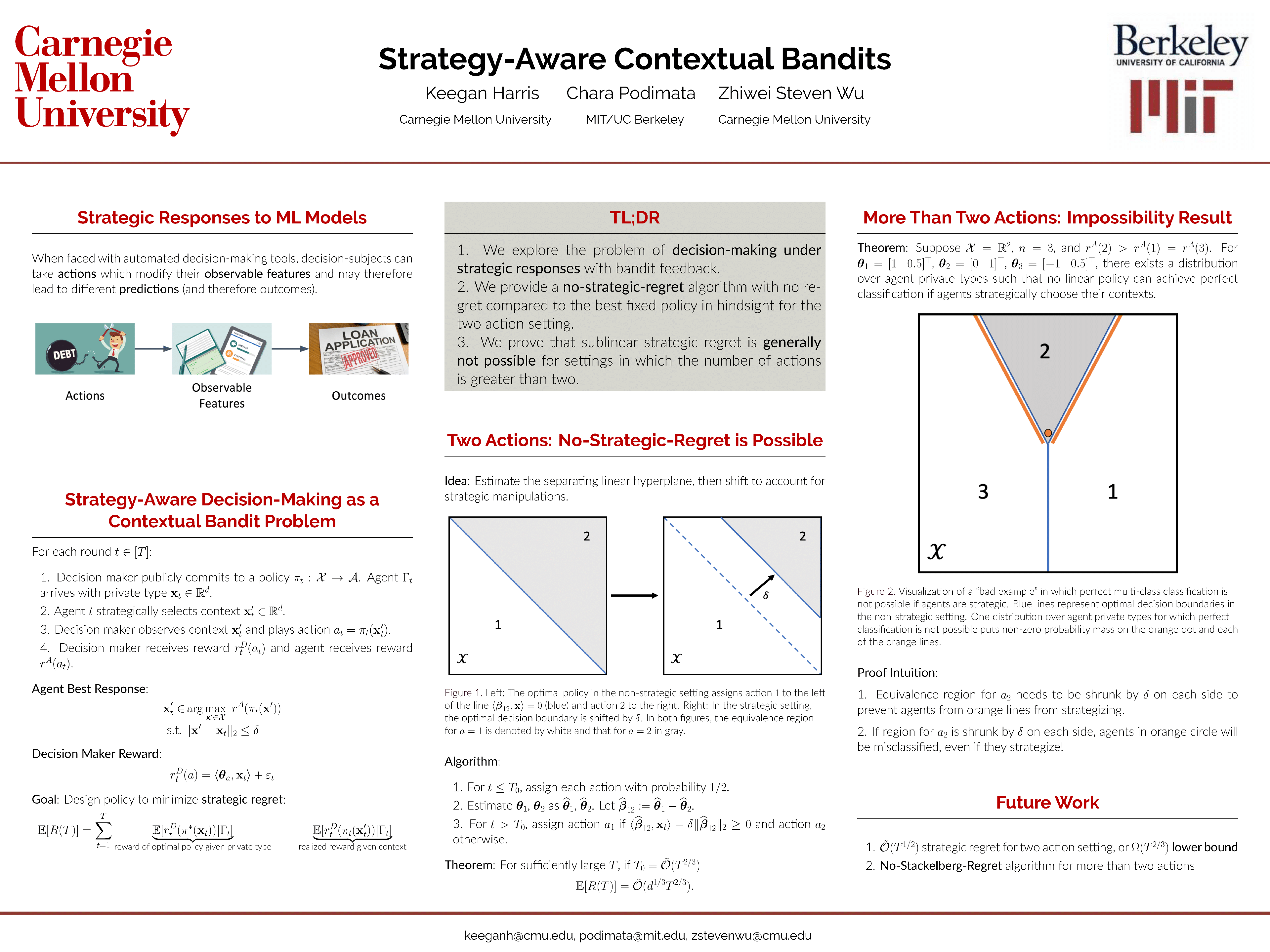
Algorithmic tools are often used to make decisions about people in high-stakes domains. In the presence of such automated decision making, there is incentive for strategic agents to modify their input to the algorithm in order to receive a more desirable outcome. While previous work on strategic classification attempts to capture this phenomenon, these models fail to take into account the multiple actions a decision maker usually has at their disposal, and the fact that they often have access only to bandit feedback. Indeed, in standard strategic classification, the decision maker's action is to either assign a positive or a negative prediction to the agent, and they are assumed to have access to the agent's true label after the fact. In contrast, we study a setting where the decision maker has access to multiple actions but only can see the outcome of the action they assign. We formalize this setting as a contextual bandit problem, in which a decision maker must take actions based on a sequence of strategically modified contexts. We provide an algorithm with no regret compared to the best fixed policy in hindsight if the agents' were truthful when revealing their contexts (i.e., no-strategic-regret) for the two action setting, and prove that sublinear strategic regret is generally not possible for settings in which the number of actions is greater than two. Along the way, we obtain impossibility results for multi-class strategic classification which may be of independent interest.