How do 3D image segmentation networks behave across the context versus foreground ratio trade-off?
{kind=link}
Abstract
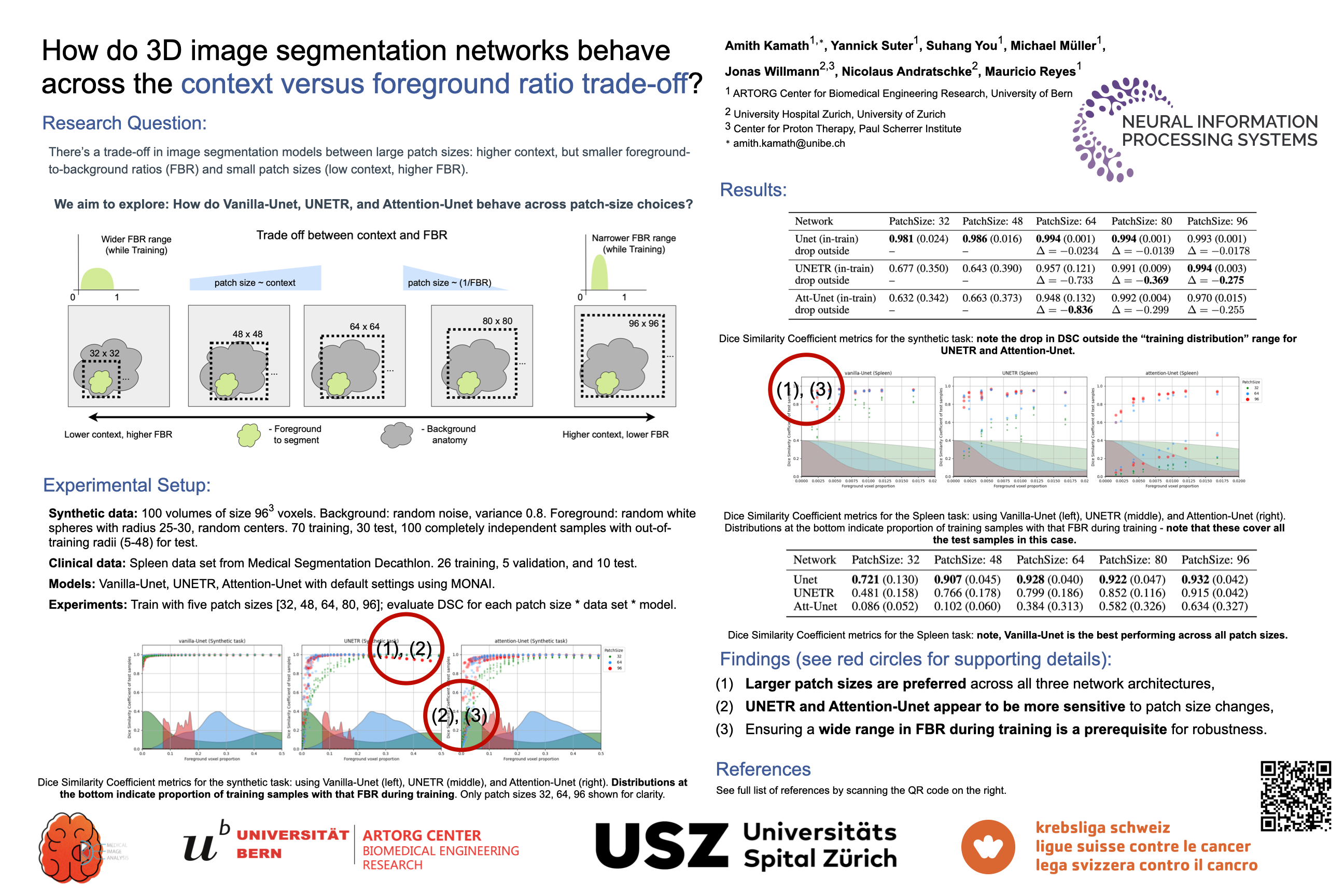
Modern 3D Medical Image Segmentation is typically done using a sliding window approach due to GPU memory constraints. However, this presents an interesting trade-off between the amount of global context the network sees at once, versus the proportion of foreground voxels available in each training sample. It is known already that UNets perform worse with low global context, but enlarging the context comes at the cost of heavy class imbalance between background (typically very large) and foreground (much smaller) while training. In this abstract, we analyze the behavior of Transformer-based (UNETR) and attention gated (Attention-Unet) models along with vanilla-Unets across this trade-off. We explore this using a synthetic data set, and a subset of the spleen segmentation data set from the Medical Segmentation Decathlon to demonstrate our results. Beyond showing that all three types of networks prefer more global context rather than bigger foreground-to-background ratios, we find that UNETR and attention-Unet appear to be less robust than vanilla-Unet to drifts between training versus test foreground ratios.