AsymQ: Asymmetric Q-loss to mitigate overestimation bias in off-policy reinforcement learning
{kind=link}
Abstract
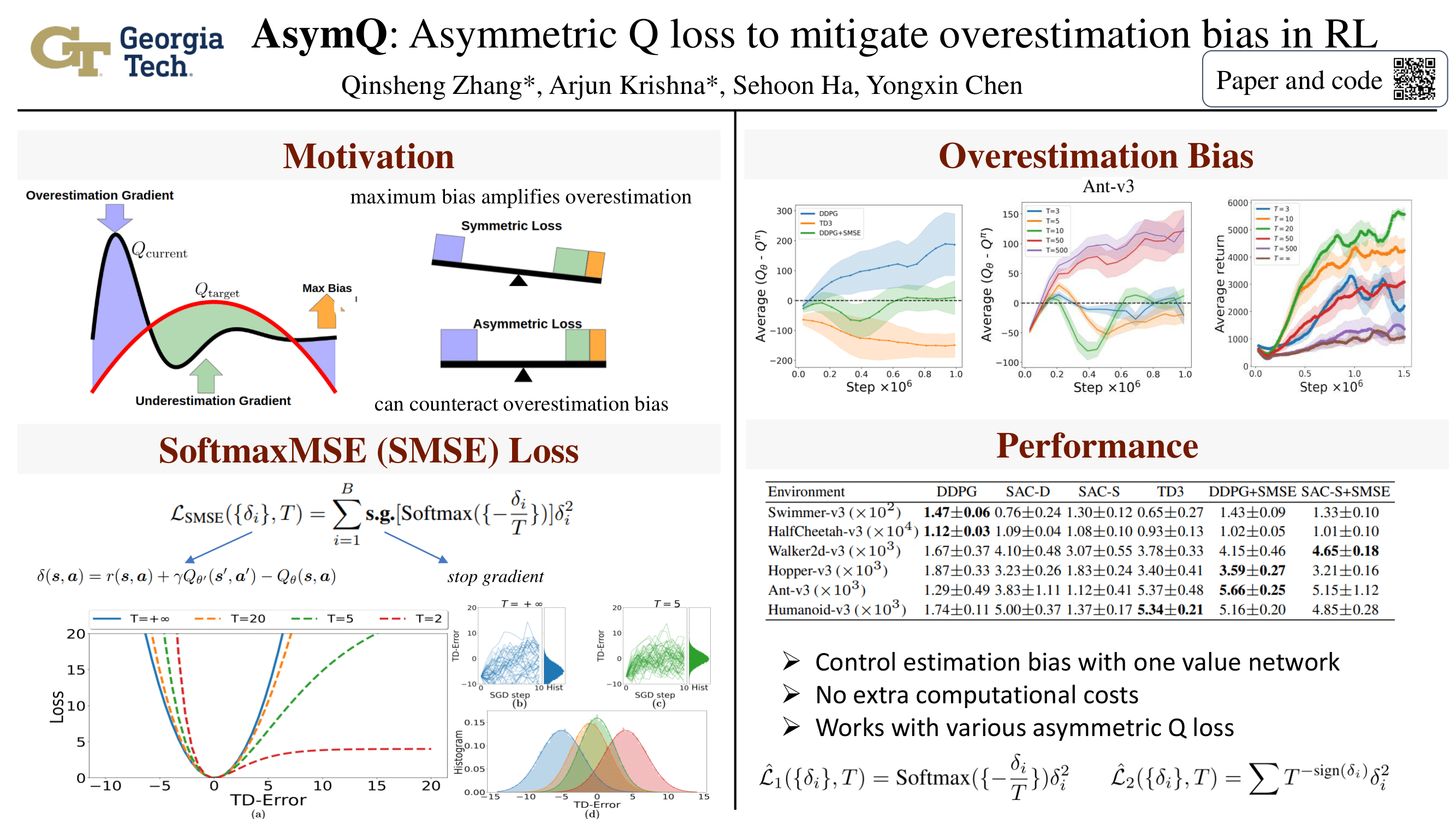
It is well-known that off-policy deep reinforcement learning algorithms suffer from overestimation bias in value function approximation. Existing methods to reduce overestimation bias often utilize multiple value function estimators. Consequently, these methods have a larger time and memory consumption. In this work, we propose a new class of policy evaluation algorithms dubbed, \textbf{AsymQ}, that use asymmetric loss functions to train the Q-value network. Departing from the symmetric loss functions such as mean squared error~(MSE) and Huber loss on the Temporal difference~(TD) error, we adopt asymmetric loss functions of the TD-error to impose a higher penalty on overestimation error. We present one such AsymQ loss called \textbf{Softmax MSE~(SMSE)} that can be implemented with minimal modifications to the standard policy evaluation. Empirically, we show that using SMSE loss helps reduce estimation bias, and subsequently improves policy performance when combined with standard reinforcement learning algorithms. With SMSE, even the Deep Deterministic Policy Gradients~(DDPG) algorithm can achieve performance comparable to that of state-of-the-art methods such as the Twin-Delayed DDPG (TD3) and Soft Actor Critic~(SAC) on challenging environments in the OpenAI Gym MuJoCo benchmark. We additionally demonstrate that the proposed SMSE loss can also boost the performance of Deep Q learning (DQN) in Atari games with discrete action spaces.