Contrastive Example-Based Control
{kind=link}
Abstract
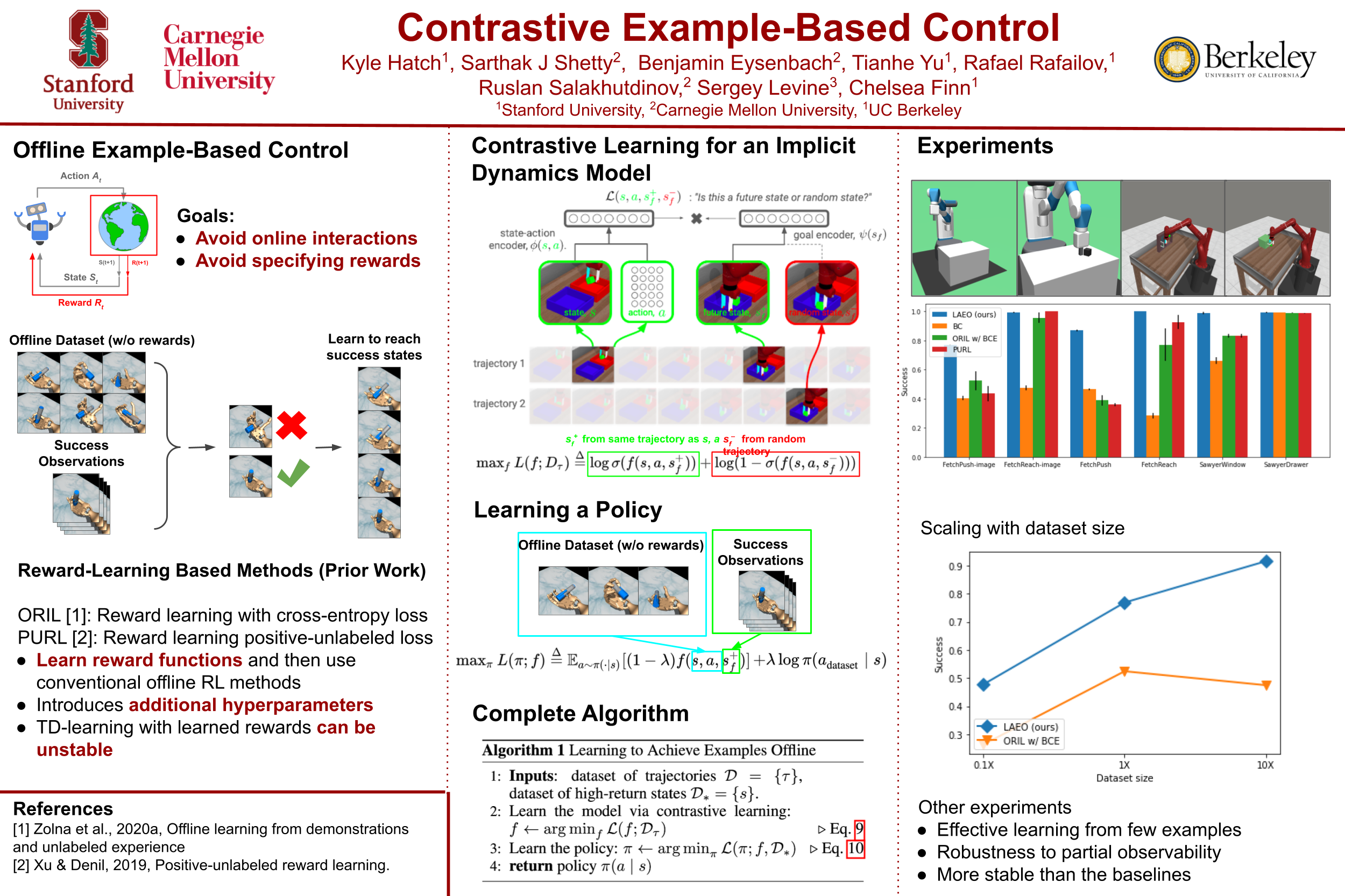
While there are many real-world problems that might benefit from reinforcement learning, these problems rarely fit into the MDP mold: interacting with the environment is often prohibitively expensive and specifying reward functions is challenging. Motivated by these challenges, prior work has developed data-driven approaches that learn entirely from samples from the transition dynamics and examples of high-return states. These methods typically learn a reward function from the high-return states, use that reward function to label the transitions, and then apply an offline RL algorithm to these transitions. While these methods can achieve good results on many tasks, they can be complex, carefully regularizing the reward function and using temporal difference updates. In this paper, we propose a simple and scalable approach to offline example-based control. Unlike prior approaches (e.g., ORIL, VICE, PURL) that learn a reward function, our method will learn an implicit model of multi-step transitions. We show that this implicit model can represent the Q-values for the example-based control problem. Thus, whereas a learned reward function must be combined with an RL algorithm to determine good actions, our model can directly be used to determine these good actions. Across a range of state-based and image-based offline control tasks, we find that our method outperforms baselines that use learned reward functions.