OpenAL: Evaluation and Interpretation of Active Learning Strategies
{kind=link}
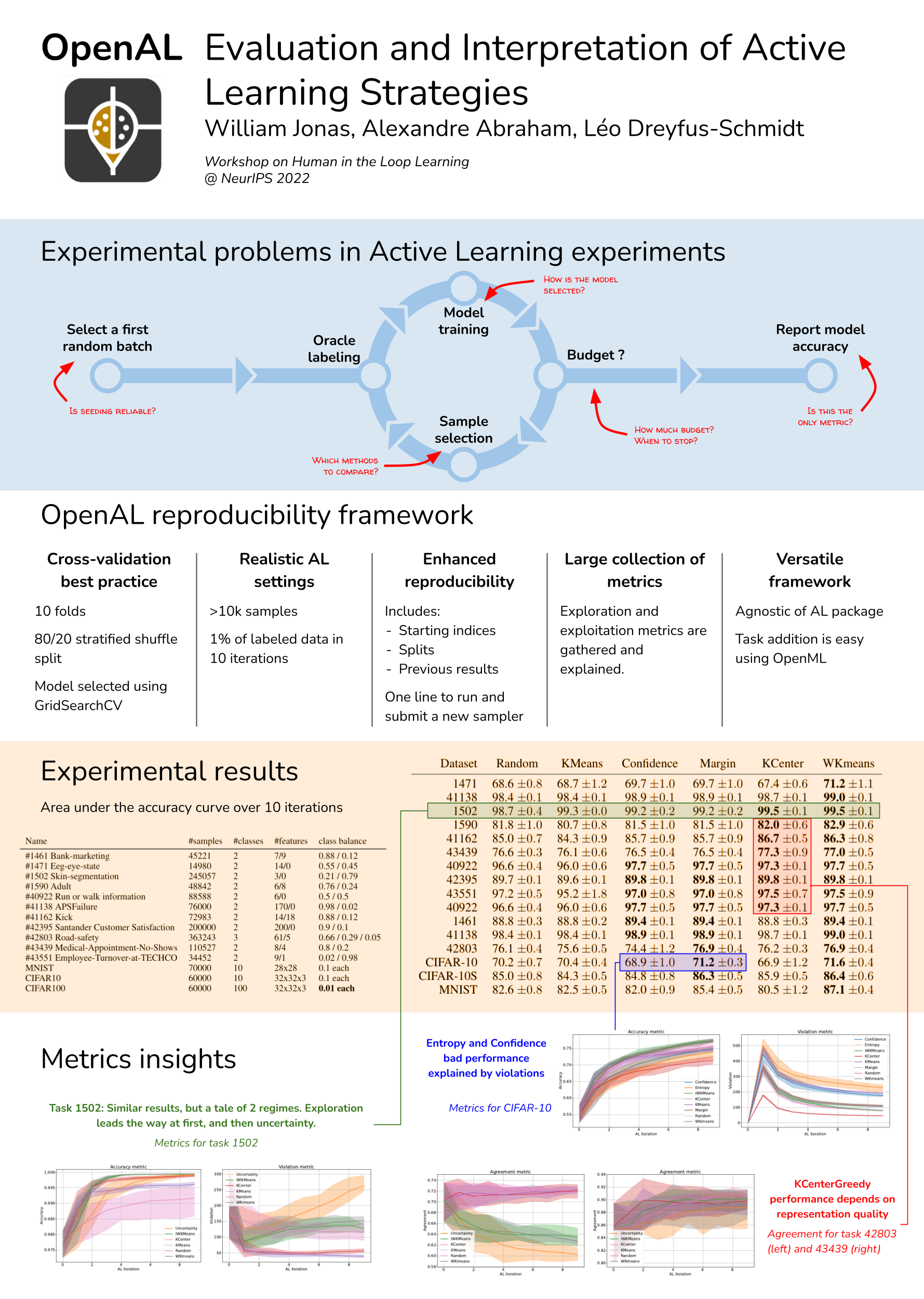
Abstract
Despite the vast body of literature on Active Learning (AL), there is no comprehensive and open benchmark allowing for efficient and simple comparison of proposed samplers. Additionally, the variability in experimental settings across the literature makes it difficult to choose a sampling strategy, which is critical due to the one-off nature of AL experiments. To address those limitations, we introduce a flexible and open-source framework to easily run and compare sampling AL strategies on a collection of realistic tasks. The proposed benchmark is augmented with interpretability metrics and statistical analysis methods to understand when and why some samplers outperform others. Last but not least, practitioners can easily extend the benchmark by submitting their own AL samplers.